
斯坦福大學-自然語言處理入門 筆記 第十七課 資訊檢索(information retrieval)
阿新 • • 發佈:2018-11-06
一、介紹
- 資訊檢索(information retrieval)是從海量集合體(一般是儲存在計算機中的文字)中找到滿足資訊需求(information need)的材料(一般是文件)
- 資訊檢索的應用領域:網頁搜尋,郵件搜尋,電腦內部搜尋,法律資訊檢索等等
- 資訊檢索的基本假設:
- 集合體(collection):一組假設為靜態(static)的文件
- 目標:抽取和使用者資訊需求相關的文件,並幫助他們完成任務
- 一個經典的搜尋模型
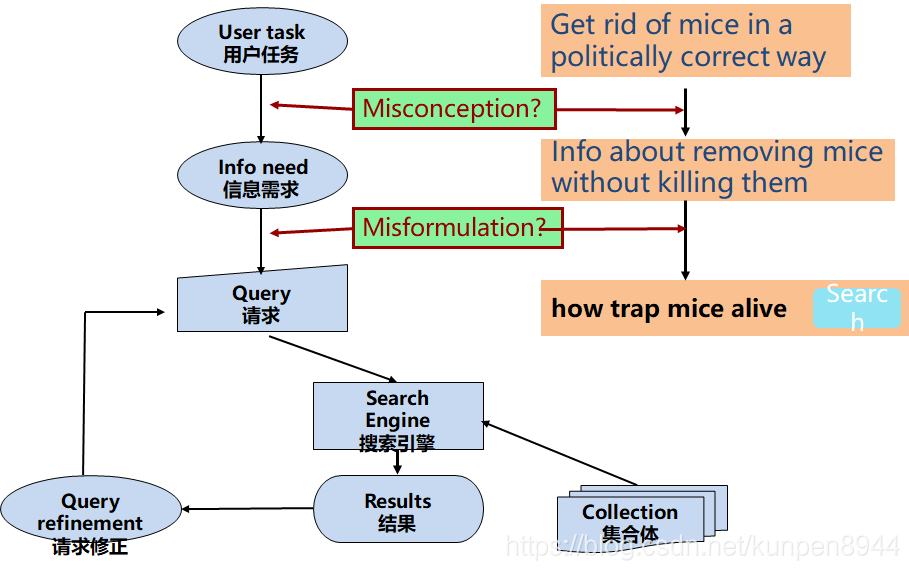
- 模型評估
- precision:檢索的文件與使用者的資訊需求(注意這裡不是請求)相關的比例
- recall:在集合體中相關的文件被檢索到的比例
二、項-文件關聯矩陣(Term-document incidence matrices)
- 假設我們現在面臨一個任務:找到莎士比亞戲劇之中,含有Brutus和Caesar但是卻沒有Calpurnia的那部。
- 方法一:直接全文搜尋含有Brutus和Caesar的戲劇,然後去掉沒有Calpurnia的那一部
- 存在的問題
- 對於一個更大的語料集合體而言,這個計算的速度會很慢,特別是對於判斷沒有Calpurnia的任務而言(因為這個任務必須必須要掃描全文)
- 對於其他的操作而言,比如找countrymen邊上的Romans,這種方法不夠靈活
- 不能進行檢索排名
- 存在的問題
- 方法二:構建一個項-文件關聯矩陣:行表示單詞,列表示文件;如果單詞在這個文件中出現了,就標1;如果沒有出現,就標0。
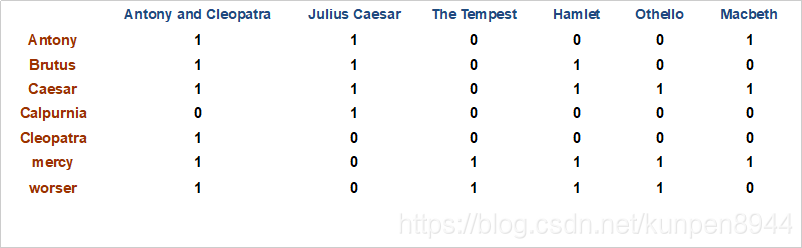 運算方法:位運算:Brutus行 AND Caesar行 AND (NOT Calpurnia)
運算方法:位運算:Brutus行 AND Caesar行 AND (NOT Calpurnia) - 上面兩種方法對於集合體更大的情況是不適用的,因為這個時候矩陣的規模已經大到不能接受了。但是這個矩陣的一個特徵是非常稀疏,因此我們可以只記錄1的位置。
三、倒排索引(Inverted Index)
- 對文件進行索引,對於每個項(term)t,我們儲存那些有這個項的文件的索引。
- 我們需要可變大小的倒排表(posting lists)
- 我們一般不會用固定大小的陣列來儲存,因為會面臨溢位的問題
- 在記憶體中的話,倒排表一般會使用連結串列或者可變長度的陣列
- 在硬碟中的話,就需要一個連續運作(continuous run)的倒排表
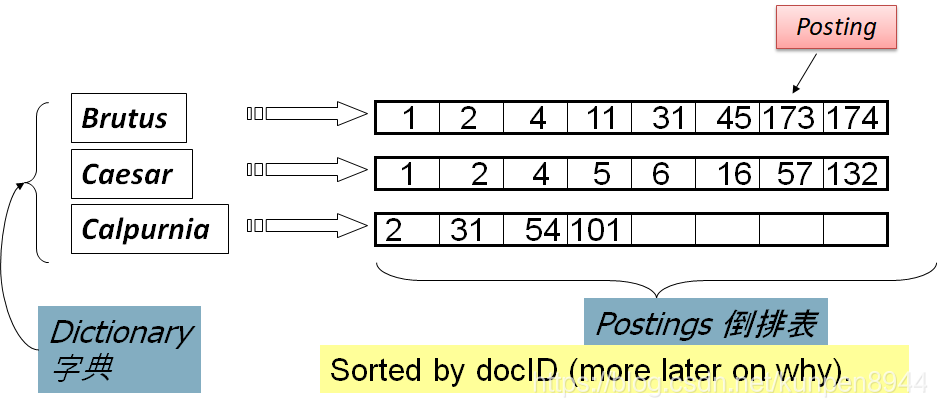
- 倒排索引的流程
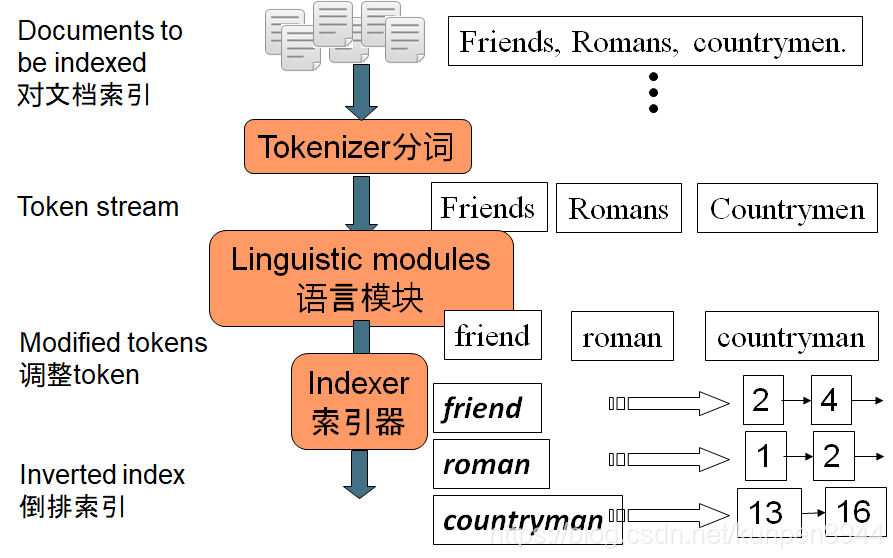
- 倒排索引前的預處理

- 索引流程
- 先把調整後的token展開成序列
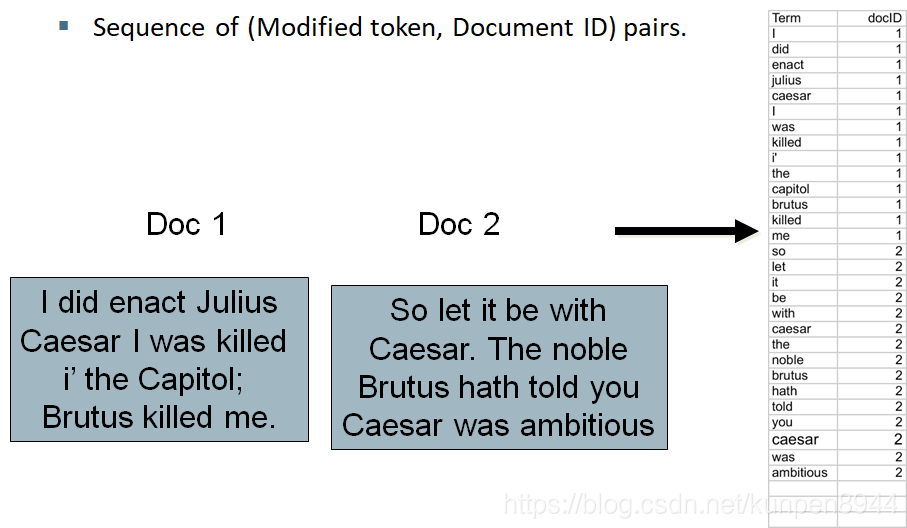
- 先根據token本身,然後根據文件ID進行排序
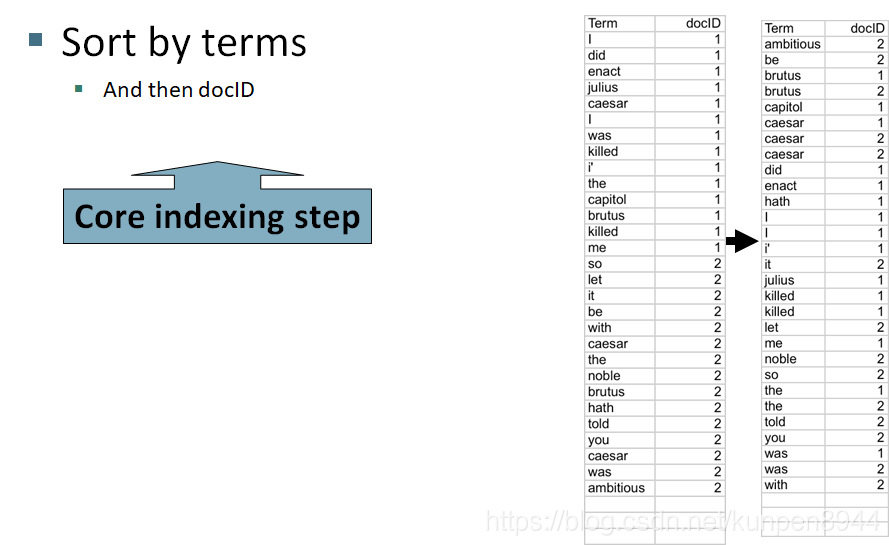
- 把同一個文件中相同的term進行合併,如caesar
- 拆分成字典和倒排表
- 加入文件頻率資訊
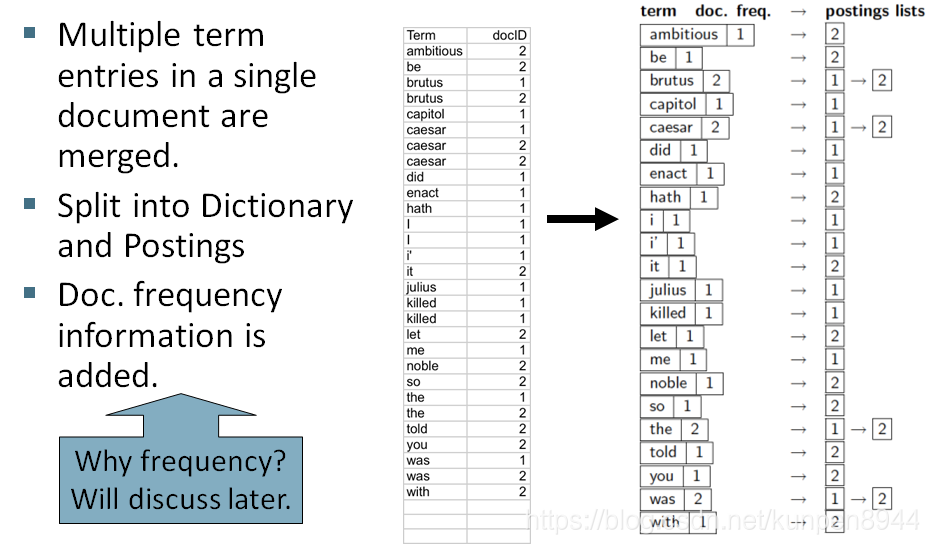
- 對於一個資訊檢索系統而言,它的儲存是由這些組成的:項和對應的頻率構成的字典,包含文件序號的連結串列以及連結串列和字典元素之間的指標。所以一個資訊檢索系統比較關注的兩個問題是:我們怎麼有效地進行檢索?我們需要多少儲存空間?
- 先把調整後的token展開成序列
四、在倒排表中如何處理請求
- 這裡講一下對AND的請求的處理
比如我們要找同時含有Brutus和Caesar的文件。我們的處理方法是在字典中找到Brutus和Caesar的位置,然後找到兩者對應的連結串列,對這兩個連結串列進行合併。

合併的主要想法是找兩個指標從這兩個連結串列的頭節點開始向後進行迴圈,如果兩者指標指向的空間的值相同則儲存該索引,兩個指標都前進一個指標;如果兩個指標指向的空間的值不同,就讓小的那個指標前進一步,然後進行比較;如此迴圈,知道一個指標指向了連結串列的尾巴為止。這種演算法的時間複雜度是O(x+y),其中x和y分別表示兩條連結串列的長度。
程式碼如下:

五、片語請求與位置索引
- 問題:如果我們想要處理一個片語的請求應該如何處理?
- 方法一:雙單詞索引
- 對文件中出現的連續單詞都進行雙單詞索引,比如出現friends,Romans,Countryman,就有兩個雙單詞:friends Romans以及Romans Countryman。接著對雙單詞構建倒排表和字典。這樣的話,我們就可以解決雙單詞的片語的查詢問題。如果是要查詢三單詞的話,只需要找到對應的兩個雙單詞的倒排連結串列,然後在進行AND操作就可以了。
- 這種方法可能存在的問題是:1)對於兩個以上的單詞片語可能會搜尋到含有對應的雙單詞,但是實際上這些雙單詞並不相連的問題。2)雙單詞會導致字典的規模很大
- 因此,一般雙單詞索引不是這種問題的標準解決方法,但是可以作為一種補充手段。
- 方法二:位置索引(positional index)
- 具體方法是在構建倒排表的時候不僅僅記錄項(term)出現的文件序號,也記錄在對應文件中的位置。

- 具體演算法:上一節的演算法的拓展,在比對到文件的序號相同的時候,再進行一次類似的演算法,判斷兩個指標指向的單詞位置是否是相鄰的。當然基於這個演算法我們也可以進一步拓展到臨近請求(proximity queries),比如索引A在B的三個單詞距離內的文件。
- 空間複雜度:這種方法會大大增加儲存所需的空間,但是由於其對臨近請求與片語請求的有效性,所以我們一般標準處理方法還是位置索引。索引的規模適合文件的平均規模有關係的,平均網頁的項(term)個數小於1000,如果是書籍的話很容易就超過100000項(term)。假設每個項(term)出現頻率是0.1%,那麼對於有100000項(term)的文件而言,位置索引就會導致倒排表比原來增加100倍。這裡有一個比較粗略的估算規則:在和英語比較類似的語言中,網頁的位置索引要比非位置索引大2-4倍,和原文件的規模比起來大概是35%-50%。
- 具體方法是在構建倒排表的時候不僅僅記錄項(term)出現的文件序號,也記錄在對應文件中的位置。
- 把上面兩種方法結合起來構成的資訊搜尋模型會更有效。對於一些特定的經常搜尋的詞,比如“michael jackson”,採用位置索引的效率是很低的,我們可以直接採用雙單詞索引。其他的則使用位置索引。比如根據Williams et al(2004)的論文,他採用了這樣的演算法,可以使得演算法時間是原來純位置索引的1/4,但是空間需求只增加了26%。