
搜狐新聞文字分類:機器學習大亂鬥
目標
- 從頭開始實踐中文短文字分類,記錄一下實驗流程與遇到的坑
- 運用多種機器學習(深度學習 + 傳統機器學習)方法比較短文字分類處理過程與結果差別
工具
- 深度學習:keras
- 傳統機器學習:sklearn
參與比較的機器學習方法
- CNN 、 CNN + word2vec
- LSTM 、 LSTM + word2vec
- MLP(多層感知機)
- 樸素貝葉斯
- KNN
- SVM
- SVM + word2vec 、SVM + doc2vec
第 1-3 組屬於深度學習方法,第 4-6 組屬於傳統機器學習方法,第 7 組算是種深度與傳統合作的方法,畫風清奇,拿來試試看看效果
資料集
先上結果
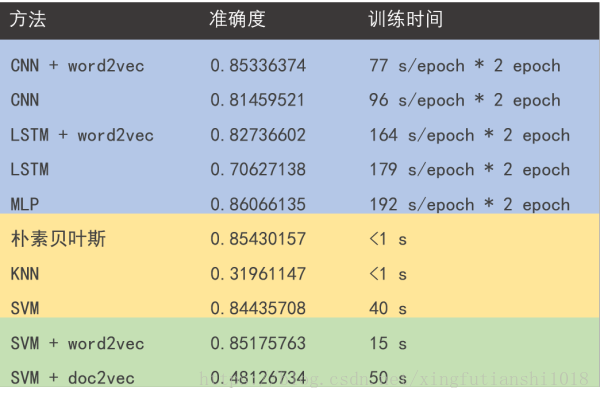
實驗結論
- 引入預訓練的 word2vec 模型會給訓練帶來好處,具體來說:(1)間接引入外部訓練資料,防止過擬合;(2)減少需要訓練的引數個數,提高訓練效率
- LSTM 需要訓練的引數個數遠小於 CNN,但訓練時間大於 CNN。CNN 在分類問題的表現上一直很好,無論是影象還是文字;而想讓 LSTM 優勢得到發揮,首先讓訓練資料量得到保證
- 將單詞在 word2vec 中的詞向量加和求平均獲得整個句子的語義向量的方法看似 naive 有時真挺奏效,當然僅限於短句子,長度 100 以內應該可以
- 機器學習方法萬千,具體選擇用什麼樣的方法還是要取決於資料集的規模以及問題本身的複雜度,對於複雜程度一般的問題,看似簡單的方法有可能是墜吼地
乾貨上完了,下面是實驗的具體流程
0 資料預處理
將下載的原始資料進行轉碼,然後給文字標類別的標籤,然後製作訓練與測試資料,然後控制文字長度,分詞,去標點符號
哎,坑多,費事,比較麻煩
首先,搜狗實驗室提供的資料下載下來是 xml 格式,並且是 GBK (萬惡之源)編碼,需要轉成 UTF8,並整理成 json 方便處理。原始資料長這個樣:

這麼大的資料量,怎麼轉碼呢?先嚐試利用 python 先讀入資料然後轉碼再儲存,可傲嬌 python 並不喜歡執行這種語句。。。再嘗試利用 vim 的 :set fileencoding=utf-8,亂碼從███變成錕斤拷。。。

經過幾次嘗試,只能通過文字編輯器開啟,然後利用文字編輯器轉換編碼。這樣問題來了,檔案大小1.6G,記事本就不提了,Notepad 和 Editplus 也都紛紛陣亡。。。

還好最後發現了 UltraEdit,不但可以開啟,速度簡直飛起來,轉碼後再整理成的 json
UltraEdit 就是好就是秒就是呱呱叫
搜狗新聞的資料沒有直接提供分類,而是得通過新聞來源網址的 url 來查其對應得分類,比如 gongyi.sohu.com 的 url 字首對應的新聞型別就是“公益類”。對著他提供的對照表查,1410000+的總資料,成功標出來的有510000+,標不出來的新聞基本都來自 roll.sohu.com,這是搜狐的滾動新聞,亂七八糟大雜燴,難以確定是什麼類

對成功標出來的15個類的新聞,統計一下類別的分佈,結果如下:

分佈比較不均,第 14 類和第 15 類的新聞很少,另外第 8 類和第 11 類一個新聞也沒有
所以最後選了剩下的11個類,每個類抽2000個新聞,按4:1分成訓練與測試,如圖

11個類分別是

對這些新聞的長度進行統計結果如下:

橫軸是新聞的長度,縱軸是擁有此長度的新聞數量。在長度為500字和1600字時突然兩個峰,猜測是搜狐新聞的一些長度限制???excited

長度0-100的放大觀察,分佈還可以,說明如果基於這套資料做短文字分類,需要對原始文字進行固定長度的擷取,長度 100 可能是個不錯的選擇

上一步選出來的訓練新聞長這樣,因為考慮到新聞標題的意義重大,這裡就將新聞標題和新聞內容接到一起,用空格隔開,然後擷取每條新聞的前 100 個字

一行是一條新聞,訓練資料17600行,測試資料4324行。然後用jieba分詞,分詞後利用詞性標註結果,把詞性為‘x’(字串)的去掉,就完成了去標點符號

jieba真是好真是秒真是呱呱叫
最後得到以下結果檔案:(1)新聞文字資料,每行 1 條新聞,每條新聞由若干個片語成,詞之間以空格隔開,訓練文字 17600 行,測試文字 4324 行;(2)新聞標籤資料,每行 1 個數字,對應這條新聞所屬的類別編號,訓練標籤 17600行,測試標籤 4324 行
1 CNN
深度學習用的 keras 工具,操作簡單易懂,模型上手飛快,居家旅行必備。keras 後端用的 Tensorflow,雖然用什麼都一樣
不使用預訓練 word2vec 模型的 CNN:
首先一些先設定一些會用到的引數
MAX_SEQUENCE_LENGTH = 100 # 每條新聞最大長度
EMBEDDING_DIM = 200 # 詞向量空間維度
VALIDATION_SPLIT = 0.16 # 驗證集比例
TEST_SPLIT = 0.2 # 測試集比例第一步先把訓練與測試資料放在一起提取特徵,使用 keras 的 Tokenizer 來實現,將新聞文件處理成單詞索引序列,單詞與序號之間的對應關係靠單詞的索引表 word_index 來記錄,這裡從所有新聞中提取到 65604 個單詞,比如 [苟,國家,生死] 就變成了 [1024, 666, 233] ;然後將長度不足 100 的新聞用 0 填充(在前端填充),用 keras 的 pad_sequences 實現;最後將標籤處理成 one-hot 向量,比如 6 變成了 [0,0,0,0,0,0,1,0,0,0,0,0,0],用 keras 的 to_categorical 實現
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
import numpy as np
tokenizer = Tokenizer()
tokenizer.fit_on_texts(all_texts)
sequences = tokenizer.texts_to_sequences(all_texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
labels = to_categorical(np.asarray(all_labels))
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
再將處理後的新聞資料按 6.4:1.6:2 分為訓練集,驗證集,測試集
p1 = int(len(data)*(1-VALIDATION_SPLIT-TEST_SPLIT))
p2 = int(len(data)*(1-TEST_SPLIT))
x_train = data[:p1]
y_train = labels[:p1]
x_val = data[p1:p2]
y_val = labels[p1:p2]
x_test = data[p2:]
y_test = labels[p2:]
print 'train docs: '+str(len(x_train))
print 'val docs: '+str(len(x_val))
print 'test docs: '+str(len(x_test))
然後就是搭建模型,首先是一個將文字處理成向量的 embedding 層,這樣每個新聞文件被處理成一個 100 x 200 的二維向量,100 是每條新聞的固定長度,每一行的長度為 200 的行向量代表這個單詞在空間中的詞向量。下面通過 1 層卷積層與池化層來縮小向量長度,再加一層 Flatten 層將 2 維向量壓縮到 1 維,最後通過兩層 Dense(全連線層)將向量長度收縮到 12 上,對應新聞分類的 12 個類(其實只有 11 個類,標籤 0 沒有用到)。搭完收工,最後,訓練模型,測試模型,一鼓作氣,攻下高地。
from keras.layers import Dense, Input, Flatten, Dropout
from keras.layers import Conv1D, MaxPooling1D, Embedding
from keras.models import Sequential
model = Sequential()
model.add(Embedding(len(word_index) + 1, EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH))
model.add(Dropout(0.2))
model.add(Conv1D(250, 3, padding='valid', activation='relu', strides=1))
model.add(MaxPooling1D(3))
model.add(Flatten())
model.add(Dense(EMBEDDING_DIM, activation='relu'))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()
模型長這個樣子

問:這裡只使用了 1 層卷積層,為什麼不多加幾層?
答:新聞長度只有100個單詞,即特徵只有100維,1 層卷積加池化後特徵已經縮減為 32 維,再加捲積可能就卷沒了。 2 層 3 層也做過,效果都不好
問:為什麼只訓練 2 輪
答:因為是遍歷訓練資料不是隨機抽取,1 輪訓練已經接近飽和,實驗表明第 2 輪訓練基本沒什麼提升
問:為什麼卷積核為什麼選擇 250 個?
答:因為開心

實驗結果如下

準確度 0.81459521
擁有11個分類的問題達到這個準確度,應該也不錯(易滿足)。並且搜狗給的資料本來也不是很好(甩鍋)。可以看到在訓練集上的準確度達到了 0.88,但是測試集上的準確度只有 0.81,說明還是有些過擬合。另外,整個模型需要訓練的引數接近 1500 萬,其中 1300 萬都是 embedding 層的引數,說明如果利用 word2vec 模型替換 embedding 層,解放這 1300 萬引數,肯定會讓訓練效率得到提高
基於預訓練的 word2vec 的 CNN :
參考資料
既然提到了 word2vec 可能會提高訓練效率,那就用實驗驗證一下。(重點)(重點)(重點)正常的深度學習訓練,比如上面的 CNN 模型,第一層(除去 Input 層)是一個將文字處理成向量的 embedding 層。這裡為了使用預訓練的 word2vec 來代替這個 embedding 層,就需要將 embedding 層的 1312 萬個引數用 word2vec 模型中的詞向量替換。替換後的 embedding 矩陣形狀為 65604 x 200,65604 行代表 65604 個單詞,每一行的這長度 200 的行向量對應這個詞在 word2vec 空間中的 200 維向量。最後,設定 embedding 層的引數固定,不參加訓練,這樣就把預訓練的 word2vec 嵌入到了深度學習的模型之中
VECTOR_DIR = 'wiki.zh.vector.bin' # 詞向量模型檔案
from keras.utils import plot_model
from keras.layers import Embedding
import gensim
w2v_model = gensim.models.KeyedVectors.load_word2vec_format(VECTOR_DIR, binary=True)
embedding_matrix = np.zeros((len(word_index) + 1, EMBEDDING_DIM))
for word, i in word_index.items():
if unicode(word) in w2v_model:
embedding_matrix[i] = np.asarray(w2v_model[unicode(word)],
dtype='float32')
embedding_layer = Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
模型搭建與剛才類似,就是用嵌入了 word2vec 的 embedding_layer 替換原來的 embedding 層
from keras.layers import Dense, Input, Flatten, Dropout
from keras.layers import Conv1D, MaxPooling1D, Embedding
from keras.models import Sequential
model = Sequential()
model.add(embedding_layer)
model.add(Dropout(0.2))
model.add(Conv1D(250, 3, padding='valid', activation='relu', strides=1))
model.add(MaxPooling1D(3))
model.add(Flatten())
model.add(Dense(EMBEDDING_DIM, activation='relu'))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()
#plot_model(model, to_file='model.png',show_shapes=True)
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=2, batch_size=128)
model.save('word_vector_cnn.h5')
print model.evaluate(x_test, y_test)
模型長相跟之前一致,實驗輸出與測試結果如下

準確度 0.85336374
相比不使用 word2vec 的 cnn,過擬合的現象明顯減輕,使準確度得到了提高。並且需要訓練的引數大大減少了,使訓練時間平均每輪減少 20s 左右

2 LSTM
終於到了自然語言處理界的大哥 LSTM 登場,還有點小期待

不使用預訓練的 word2vec 模型的 LSTM:
特徵提取以及 embedding 的過程跟 CNN 的實驗一致。接下來的 LSTM 層的功能在最終效果上(或許)可以理解成將一個序列的詞向量壓縮成一個句向量。每個新聞經過 embedding 層後得到一個 100 x 200 的 2 維向量,通過將這 100 個詞向量按前後順序逐個輸入 LSTM 層中,最後輸出一個 1 維的長度 200 的向量,最後一個全連線層將長度收縮到 12
from keras.layers import Dense, Input, Flatten, Dropout
from keras.layers import LSTM, Embedding
from keras.models import Sequential
model = Sequential()
model.add(Embedding(len(word_index) + 1, EMBEDDING_DIM,
input_length=MAX_SEQUENCE_LENGTH))
model.add(LSTM(200, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.2))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()
模型長這樣

大哥開動!

準確度** 0.70627138**

並沒有期待中那麼美好。。。原因是這點小資料量,並沒有讓 LSTM 發揮出它的優勢。並不能給大哥一個賓士的草原。。。並不能讓大哥飛起來。。。另外使用 LSTM 需要訓練的引數要比使用 CNN 少很多,但是訓練時間是 CNN 的 2 倍。大哥表示不但飛不動,還飛的很累。。。
基於預訓練的 word2vec 模型:
流程跟上面使用 word2vec 的 CNN 的基本一致,同樣也是用嵌入了 word2vec 的 embedding_layer 替換原始的 embedding 層
from keras.layers import Dense, Input, Flatten, Dropout
from keras.layers import LSTM, Embedding
from keras.models import Sequential
model = Sequential()
model.add(embedding_layer)
model.add(LSTM(200, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.2))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()
準確度 0.82736602
效果好了不少,依然存在過擬合現象,再一次說明了資料量對 LSTM 的重要性,使用預訓練的 word2vec 模型等於間接增加了訓練語料,所以在這次實驗中崩壞的不是很嚴重
3 MLP(多層感知機)
參考資料
MLP 是一個結構上很簡單很 naive 的神經網路。資料的處理流程也跟上面兩個實驗差不多,不過不再將每條新聞處理成 100 x 200 的 2 維向量,而是成為長度 65604 的 1 維向量。65604 代表資料集中所有出現的 65604 個單詞,資料的值用 tf-idf 值填充,整個文件整合為一個用 17600 x 65604 個 tf-idf 值填充的矩陣,第 i 行 j 列的值表徵了第 j 個單詞在第 i 個文件中的的 tf-idf值(當然這裡也可以不用 tf-idf 值,而只是使用 0/1 值填充, 0/1 代表第 j 個單詞在第 i 個文件中是否出現,但是實驗顯示用 tf-idf 的效果更好)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(all_texts)
sequences = tokenizer.texts_to_sequences(all_texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = tokenizer.sequences_to_matrix(sequences, mode='tfidf')
labels = to_categorical(np.asarray(all_labels))
模型很簡單,僅有兩個全連線層組成,將長度 65604 的 1 維向量經過 2 次壓縮成為長度 12 的 1 維向量
from keras.layers import Dense, Dropout
from keras.models import Sequential
model = Sequential()
model.add(Dense(512, input_shape=(len(word_index)+1,), activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()

準確度 0.86066135
相比 CNN 與 LSTM 的最好成績,並且在訓練集上的準確度已經高達 0.99!這可是 11 分類啊

只是不能像 CNN 與 LSTM 那樣藉助預訓練 word2vec 的幫助,加上資料量不大,所以稍微有些過擬合,不過結果依舊很不錯。沒有複雜的 embedding,清新脫俗的傳統感知機模型在這種小資料集的簡單問題上表現非常好(雖然訓練引數已經達到了 3300 萬個,單輪耗時也將近 200s 了)
4 樸素貝葉斯
非深度學習方法這裡使用 sklearn 來實踐
首先登場的是樸素貝葉斯。資料處理的過程跟上述的 MLP 是一致的,也是將整個文件集用 tf-idf 值填充,讓整個文件整合為一個 17600 x 65604 的 tf-idf 矩陣。這裡需要使用 sklearn 的 CountVectorizer 與 TfidfTransformer 函式實現。程式碼如下
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
count_v0= CountVectorizer();
counts_all = count_v0.fit_transform(all_text);
count_v1= CountVectorizer(vocabulary=count_v0.vocabulary_);
counts_train = count_v1.fit_transform(train_texts);
print "the shape of train is "+repr(counts_train.shape)
count_v2 = CountVectorizer(vocabulary=count_v0.vocabulary_);
counts_test = count_v2.fit_transform(test_texts);
print "the shape of test is "+repr(counts_test.shape)
tfidftransformer = TfidfTransformer();
train_data = tfidftransformer.fit(counts_train).transform(counts_train);
test_data = tfidftransformer.fit(counts_test).transform(counts_test);
這裡有一個需要注意的地方,由於訓練集和測試集分開提取特徵會導致兩者的特徵空間不同,比如訓練集裡 “苟” 這個單詞的序號是 1024,但是在測試集裡序號就不同了,或者根本就不存在在測試集裡。所以這裡先用所有文件共同提取特徵(counts_v0),然後利用得到的詞典(counts_v0.vocabulary_)再分別給訓練集和測試集提取特徵。然後開始訓練與測試
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
clf = MultinomialNB(alpha = 0.01)
clf.fit(x_train, y_train);
preds = clf.predict(x_test);
num = 0
preds = preds.tolist()
for i,pred in enumerate(preds):
if int(pred) == int(y_test[i]):
num += 1
print 'precision_score:' + str(float(num) / len(preds))
準確度 0.85430157
這只是一個簡單的樸素貝葉斯方法,準確度高到驚人,果然最簡單的有時候就是最有效的

5 KNN
跟上面基本一致,只是將 MultinomialNB 函式變成 KNeighborsClassifier 函式,直接上結果
from sklearn.neighbors import KNeighborsClassifier
for x in range(1,15):
knnclf = KNeighborsClassifier(n_neighbors=x)
knnclf.fit(x_train,y_train)
preds = knnclf.predict(x_test);
num = 0
preds = preds.tolist()
for i,pred in enumerate(preds):
if int(pred) == int(y_test[i]):
num += 1
print 'K= '+str(x)+', precision_score:' + str(float(num) / len(preds))
K=11時,準確度 0.31961147,非常低,KNN 方法還是不太適合做此類問題

6 SVM
這裡 svm 的 kernel 選用了線性核,其他的比如多項式核和高斯核也都試過,效果極差,直接上結果
from sklearn.svm import SVC
svclf = SVC(kernel = 'linear')
svclf.fit(x_train,y_train)
preds = svclf.predict(x_test);
num = 0
preds = preds.tolist()
for i,pred in enumerate(preds):
if int(pred) == int(y_test[i]):
num += 1
print 'precision_score:' + str(float(num) / len(preds))
7 SVM + word2vec 與 doc2vec
這兩個實驗是後期新加入的,畫風比較清奇,是騾是馬溜一圈,就決定拿過來做個實驗一起比較一下
svm + word2vec:
這個實驗的主要思想是這樣:原本每條新聞由若干個片語成,每個詞在 word2vec 中都有由一個長度 200 的詞向量表示,且這個詞向量的位置是與詞的語義相關聯的。那麼對於每一條新聞,將這條新聞中所有的詞的詞向量加和取平均,既能保留句子中所有單詞的語義,又能生成一個蘊含著這句話的綜合語義的“句向量”,再基於這個長度 200 的句向量使用 svm 分類。這個思想看起來很 naive,但是又說不出什麼不合理的地方。嘗試一下,程式碼與結果如下:
import gensim
import numpy as np
w2v_model = gensim.models.KeyedVectors.load_word2vec_format(VECTOR_DIR, binary=True)
x_train = []
x_test = []
for train_doc in train_docs:
words = train_doc.split(' ')
vector = np.zeros(EMBEDDING_DIM)
word_num = 0
for word in words:
if unicode(word) in w2v_model:
vector += w2v_model[unicode(word)]
word_num += 1
if word_num > 0:
vector = vector/word_num
x_train.append(vector)
for test_doc in test_docs:
words = test_doc.split(' ')
vector = np.zeros(EMBEDDING_DIM)
word_num = 0
for word in words:
if unicode(word) in w2v_model:
vector += w2v_model[unicode(word)]
word_num += 1
if word_num > 0:
vector = vector/word_num
x_test.append(vector)
準確度 0.85175763,驚了,這種看似很 naive 的方法竟然取得了非常好的效果。相比於之前所有包括 CNN、LSTM、MLP、SVM 等方法,這種方法有很強的優勢。它不需要特徵提取的過程,也不需固定新聞的長度,一個模型訓練好,跨著資料集都能跑。但是也有其缺陷一面,比如忽略詞語的前後關係,並且當句子長度較長時,求和取平均已經無法準確保留語義資訊了。但是在短文字分類上的表現還是很亮

svm + doc2vec:
上面 svm + word2vec 的實驗提到當句子很長時,簡單求和取平均已經不能保證原來的語義資訊了。偶然發現了 gensim 提供了一個 doc2vec 的模型,直接為文件量身訓練“句向量”,神奇。具體原理不講了(也不是很懂),直接給出使用方法
import gensim
sentences = gensim.models.doc2vec.TaggedLineDocument('all_contents.txt')
model = gensim.models.Doc2Vec(sentences, size=200, window=5, min_count=5)
model.save('doc2vec.model')
print 'num of docs: ' + str(len(model.docvecs))
all_contents.txt 裡是包括訓練文件與測試文件在內的所有資料,同樣每行 1 條新聞,由若干個片語成,詞之間用空格隔開,先使用 gensim 的 TaggedLineDocument 函式預處理下,然後直接使用 Doc2Vec 函式開始訓練,訓練過程很快(可能因為資料少)。然後這所有 21924 篇新聞就變成了 21924 個長度 200 的向量,取出前 17600 個給 SVM 做分類訓練,後 4324 個測試,程式碼和結果如下:
import gensim
model = gensim.models.Doc2Vec.load('doc2vec.model')
x_train = []
x_test = []
y_train = train_labels
y_test = test_labels
for idx, docvec in enumerate(model.docvecs):
if idx < 17600:
x_train.append(docvec)
else:
x_test.append(docvec)
print 'train doc shape: '+str(len(x_train))+' , '+str(len(x_train[0]))
print 'test doc shape: '+str(len(x_test))+' , '+str(len(x_test[0]))
from sklearn.svm import SVC
svclf = SVC(kernel = 'rbf')
svclf.fit(x_train,y_train)
preds = svclf.predict(x_test);
num = 0
preds = preds.tolist()
for i,pred in enumerate(preds):
if int(pred) == int(y_test[i]):
num += 1
print 'precision_score:' + str(float(num) / len(preds))
準確度 0.48126734,慘不忍睹。原因可能就是文件太短,每個文件只有不超過 100 個詞,導致對“句向量”的學習不準確,word2vec 模型訓練需要 1G 以上的資料量,這裡訓練 doc2vec 模型20000個文件卻只有 5M 的大小,所以崩壞。這裡對 doc2vec 的應用場景有一些疑問,如果我新加入一條新聞想要分類,那麼我必須先要把這個新聞加到文件集裡,然後重新對文件集進行 doc2vec 的訓練,得到這個新新聞的文件向量,然後由於文件向量模型變了, svm 分類模型應該也需要重新訓練了。所以需要自底向上把所有模型打破重建才能讓為新文件分類?那實用性很差啊。也可能我理解有誤,希望是這樣。
總結

短文字分類這個坑終於填完了,共計 12 種機器學習方法以及變形,花了 4 天時間才把這個坑填上。當然機器學習界方法萬千五花八門,無法窮舉,見不多識不廣的我也只能拿我知道的這幾個做個實驗玩一下供以後參考。12 種方法優勢各異,做個總結:
- 引入預訓練的 word2vec 模型會給訓練帶來好處,具體來說:(1)間接引入外部訓練資料,防止過擬合;(2)減少需要訓練的引數個數,提高訓練效率
- LSTM 需要訓練的引數個數遠小於 CNN,但訓練時間大於 CNN。CNN 在分類問題的表現上一直很好,無論是影象還是文字;而想讓 LSTM 優勢得到發揮,首先讓訓練資料量得到保證
- 將單詞在 word2vec 中的詞向量加和求平均獲得整個句子的語義向量的方法看似 naive 有時真挺奏效,當然僅限於短句子,長度 100 以內應該可以
- 機器學習方法萬千,具體選擇用什麼樣的方法還是要取決於資料集的規模以及問題本身的複雜度,對於複雜程度一般的問題,看似簡單的方法有可能是墜吼地