
資料倉庫系統的實現與使用(含OLAP重點講解)
前言
上一篇重點講解了資料倉庫建模,它是資料倉庫開發中最核心的部分。然而完整的資料倉庫系統還會涉及其他一些元件的開發,其中最主要的是ETL工程,線上分析處理工具(OLAP)和商務智慧(BI)應用等。
本文將對這些方面做一個總體性的介紹(尤其是OLAP),旨在讓讀者對資料倉庫的認識提升到一個全域性性的高度。
建立資料倉庫
資料倉庫的建立方法和資料庫類似,也是通過編寫DDL語句來實現。在過去,資料倉庫系統大都建立在RDBMS上,因為維度建模其實也可以看做是關係建模的一種。但如今隨著開源分散式資料倉庫工具如Hadoop Hive,Spark SQL的興起,開發人員往往將建模和實現分離。使用專門的建模軟體進行ER建模、關係建模、維度建模,而具體實現則在Hive/Spark SQL下進行。沒辦法,誰讓這些開源工具沒有提供自帶的視覺化建模外掛呢:-(。
話說現在的開源分散式工具都是"散兵作戰",完成一個大的專案要組合N個工具,沒有一個統一的開發平臺。還有就是視覺化效果比較差,介面很難看或者沒有介面。個人建議在資金足夠的情況下儘量使用商用大資料平臺來開發,雖然這些商用產品廣告打得多少有點誇張,但是它們的易用性做的是真好。這裡筆者推薦阿里雲的數加平臺,附連結:https://data.aliyun.com/。
ETL:抽取、轉換、載入
在本系列第一篇中,曾大致介紹了該環節,它很可能是資料倉庫開發中最耗時的階段。本文將詳細對這個環節進行講解。
ETL工作的實質就是從各個資料來源提取資料,對資料進行轉換,並最終載入填充資料到資料倉庫維度建模後的表中
1. 抽取(Extract)
資料倉庫是面向分析的,而操作型資料庫是面向應用的。顯然,並不是所有用於支撐業務系統的資料都有拿來分析的必要。因此,該階段主要是根據資料倉庫主題、主題域確定需要從應用資料庫中提取的數。
具體開發過程中,開發人員必然經常發現某些ETL步驟和資料倉庫建模後的表描述不符。這時候就要重新核對、設計需求,重新進行ETL。正如資料庫系列的這篇中講到的,任何涉及到需求的變動,都需要重頭開始並更新需求文件。
2. 轉換(Transform)
轉換步驟主要是指對提取好了的資料的結構進行轉換,以滿足目標資料倉庫模型的過程。此外,轉換過程也負責資料質量工作,這部分也被稱為資料清洗(data cleaning)。資料質量涵蓋的內容可具體參考這裡。
3. 載入(Load)
載入過程將已經提取好了,轉換後保證了資料質量的資料載入到目標資料倉庫。載入可分為兩種L:首次載入(first load)和重新整理載入(refresh load)。其中,首次載入會涉及到大量資料,而重新整理載入則屬於一種微批量式的載入。
多說一句,如今隨著各種分散式、雲端計算工具的興起,ETL實則變成了ELT。就是業務系統自身不會做轉換工作,而是在簡單的清洗後將資料匯入分散式平臺,讓平臺統一進行清洗轉換等工作。這樣做能充分利用平臺的分散式特性,同時使業務系統更專注於業務本身。
OLAP/BI工具
資料倉庫建設好以後,使用者就可以編寫SQL語句對其進行訪問並對其中資料進行分析。但每次查詢都要編寫SQL語句的話,未免太麻煩,而且對維度建模資料進行分析的SQL程式碼套路比較固定。於是,便有了OLAP工具,它專用於維度建模資料的分析。而BI工具則是能夠將OLAP的結果以圖表的方式展現出來,它和OLAP通常出現在一起。(注:本文所指的OLAP工具均指代這兩者。)
在規範化資料倉庫中OLAP工具和資料倉庫的關係大致是這樣的: 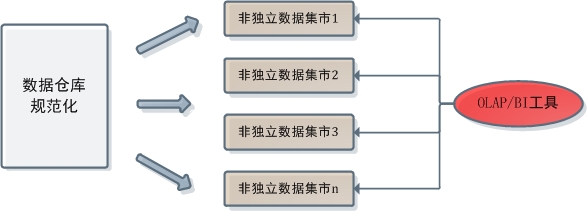
這種情況下,OLAP不允許訪問中心資料庫。一方面中心資料庫是採取規範化建模的,而OLAP只支援對維度建模資料的分析;另一方面規範化資料倉庫的中心資料庫本身就不允許上層開發人員訪問。而在維度建模資料倉庫中,OLAP/BI工具和資料倉庫的關係則是這樣的:
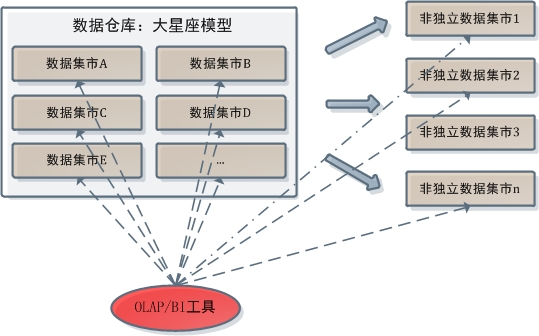
在維度建模資料倉庫中,OLAP不但可以從資料倉庫中直接取數進行分析,還能對架構在其上的資料集市群做同樣工作。對該部分講解感到模糊的讀者請重看上篇中三種資料倉庫建模體系部分。
資料立方體(Data Cube)
在介紹OLAP工具的具體使用前,先要了解這個概念:資料立方體(Data Cube)。
很多年前,當我們要手工從一堆資料中提取資訊時,我們會分析一堆資料報告。通常這些資料報告採用二維表示,是行與列組成的二維表格。但在真實世界裡我們分析資料的角度很可能有多個,資料立方體可以理解為就是維度擴充套件後的二維表格。下圖展示了一個三維資料立方體:
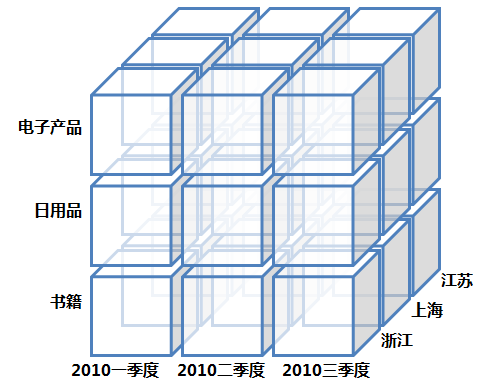
儘管這個例子是三維的,但更多時候資料立方體是N維的。它的實現有兩種方式,本文後面部分會講到。其中上一篇講到的星形模式就是其中一種,該模式其實是一種連線關係表與資料立方體的橋樑。但對於大多數純OLAP使用者來講,資料分析的物件就是這個邏輯概念上的資料立方體,其具體實現不用深究。對於這些OLAP工具的使用者來講,基本用法是首先配置好維表、事實表,然後在每次查詢的時候告訴OLAP需要展示的維度和事實欄位和操作型別即可。
下面介紹資料立方體中最常見的五大操作:切片,切塊,旋轉,上卷,下鑽。
1. 切片和切塊(Slice and Dice)
在資料立方體的某一維度上選定一個維成員的操作叫切片,而對兩個或多個維執行選擇則叫做切塊。下圖邏輯上展示了切片和切塊操作:
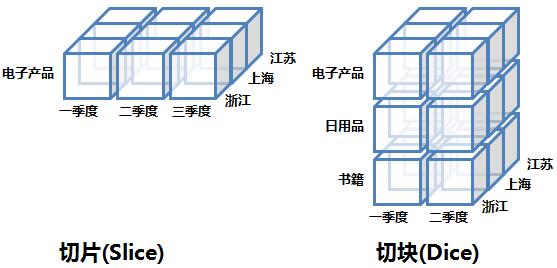
這兩種操作的SQL模擬語句如下,主要是對WHERE語句做工作:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#
切片
SELECT Locates.地區,
Products.分類, SUM(數量)
FROM Sales,
Dates, Products, Locates
WHERE Dates.季度
= 2
AND Sales.Date_key
= Dates.Date_key
AND Sales.Locate_key
= Locates.Locate_key
AND Sales.Product_key
= Products.Product_key
GROUP BY Locates.地區,
Products.分類
#
切塊
SELECT Locates.地區,
Products.分類, SUM(數量)
FROM Sales,
Dates, Products, Locates
WHERE (Dates.季度
= 2 OR Dates.季度
= 3) AND (Locates.地區
= '江蘇' OR Locates.地區
= '上海')
AND Sales.Date_key
= Dates.Date_key
AND Sales.Locate_key
= Locates.Locate_key
AND Sales.Product_key
= Products.Product_key
GROUP BY Dates.季度,
Locates.地區, Products.分類
|
2. 旋轉(Pivot)
旋轉就是指改變報表或頁面的展示方向。對於使用者來說,就是個檢視操作,而從SQL模擬語句的角度來說,就是改變SELECT後面欄位的順序而已。下圖邏輯上展示了旋轉操作:
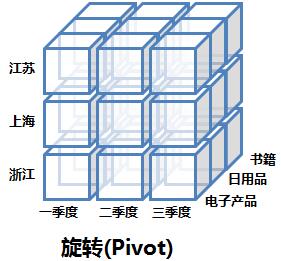
3. 上卷和下鑽(Rol-up and Drill-down)
上卷可以理解為"無視"某些維度;下鑽則是指將某些維度進行細分。下圖邏輯上展示了上卷和下鑽操作:
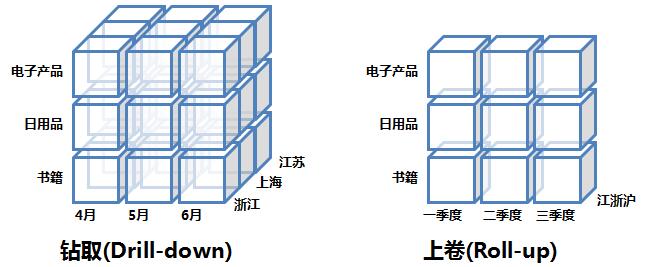
這兩種操作的SQL模擬語句如下,主要是對GROUP BY語句做工作:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#
上卷
SELECT Locates.地區,
Products.分類, SUM(數量)
FROM Sales,
Products, Locates
WHERE Sales.Locate_key
= Locates.Locate_key
AND Sales.Product_key
= Products.Product_key
GROUP BY Locates.地區,
Products.分類
#
下鑽
SELECT Locates.地區,
Dates.季度, Products.分類, SUM(數量)
FROM Sales,
Dates, Products, Locates
WHERE Sales.Date_key
= Dates.Date_key
AND Sales.Locate_key
= Locates.Locate_key
AND Sales.Product_key
= Products.Product_key
GROUP BY Dates.季度.月份,
Locates.地區, Products.分類
|
4. 其他OLAP操作
除了上述的幾個基本操作,不同的OLAP工具也會提供自有的OLAP查詢功能,如鑽過,鑽透等,本文不一一進行講解。通常一個複雜的OLAP查詢是多個這類OLAP操作疊加的結果。
回到頂部OLAP的架構模式
1. MOLAP(Multidimensional Online Analytical Processing)
MOLAP架構會生成一個新的多維資料集,也可以說是構建了一個實際資料立方體。其架構如下圖所示:
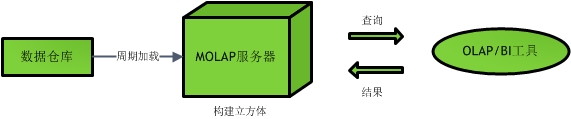
在該立方體中,每一格對應一個直接地址,且常用的查詢已被預先計算好。因此每次的查詢都是非常快速的,但是由於立方體的更新比較慢,所以是否使用這種架構得具體問題具體分析。
相關推薦
資料倉庫系統的實現與使用(含OLAP重點講解)
前言 上一篇重點講解了資料倉庫建模,它是資料倉庫開發中最核心的部分。然而完整的資料倉庫系統還會涉及其他一些元件的開發,其中最主要的是ETL工程,線上分析處理工具(OLAP)和商務智慧(BI)應用等。 本文將對這些方面做一個總體性的介紹
DTCC 2020 | 阿里雲李飛飛:雲原生分散式資料庫與資料倉庫系統點亮資料上雲之路
簡介: 資料庫將面臨怎樣的變革?雲原生資料庫與資料倉庫有哪些獨特優勢?在日前的 DTCC 2020大會上,阿里巴巴集團副總裁、阿里雲資料庫產品事業部總裁、ACM傑出科學家李飛飛就《雲原生分散式資料庫與資料倉庫系統點亮資料上雲之路》進行了精彩分享。 雲端計算時代,雲原生分散式資料庫和資料倉庫開始崛起,提供彈
5資料倉庫的架構與設計
公司之前的資料都是直接傳到Hdfs上進行操作,沒有一個數據倉庫,趁著最近空出幾臺伺服器,搭了個簡陋的資料倉庫,這裡記錄一下資料倉庫的一些知識。涉及的主要內容有: 什麼是資料倉庫? 資料倉庫的架構 資料倉庫多維資料模型的設計 1. 什麼是資料倉庫 1.1 資料倉庫的概念 官方定義 資料倉庫是一
美團DB資料同步到資料倉庫的架構與實踐
背景 在資料倉庫建模中,未經任何加工處理的原始業務層資料,我們稱之為ODS(Operational Data Store)資料。在網際網路企業中,常見的ODS資料有業務日誌資料(Log)和業務DB資料(DB)兩類。對於業務DB資料來說,從MySQL等關係型資料庫的業務資料進行採集,然後匯入到Hive中,是進行
資料倉庫的架構與設計
公司之前的資料都是直接傳到Hdfs上進行操作,沒有一個數據倉庫,趁著最近空出幾臺伺服器,搭了個簡陋的資料倉庫,這裡記錄一下資料倉庫的一些知識。涉及的主要內容有: 1. 什麼是資料倉庫 1.1 資料倉庫的概念 官方定義 資料倉庫是一個面向主
恆豐銀行基於大資料平臺構建資料倉庫的研究與實踐
恆豐銀行原傳統資料倉庫是建立在IOE(IBM、ORACLE、EMC)傳統架構體系上,已接入資料來源系統有30多個,配套建立監管資料集市、資料分析集市,風險資料集市三個主要資料集市,負責十幾個管理應用和監管系統的資料需求,下游建有銀行管理類系統如綜合經營分析系統(管理駕駛艙)、
資料庫與資料倉庫的區別與聯絡
資料庫是面向事務的設計,資料倉庫是面向主題設計的。資料庫一般儲存線上交易資料,資料倉庫儲存的一般是歷史資料。 資料庫是面向事務的設計,資料倉庫是面向主題設計的。資料庫一般儲存線上交易資料,資料倉庫儲存的一般是歷史資料。資料庫設計是儘量避免冗餘,一般採用符合正規化的規則來設計
大資料導論(4)——OLTP與OLAP、資料庫與資料倉庫
公司內部的資料自下而上流動,同時完成資料到資訊、知識、洞察的轉化過程。 而企業內部資料,從日常OLTP流程中產生,實時儲存進不同的資料庫中。同時定期被提取、經格式轉化、清洗和載入(ETL),以統一的格式儲存進資料倉庫,以供決策者進行OLAP處理,並將處理結果視覺化。 OLTP & OLAP 企業
基於BS架構的臨床科研資料管理系統的設計與實現
基於BS架構的臨床科研資料管理系統的設計與實現 2018年11月10日 目錄 第一章 緒論... 6 1.1
環境企業表單許可權分配填報資料系統設計與實現
目 錄 摘要 Ⅰ 致謝 36 第一章 前言 1.1 專案的背景和意義 科技發展,新技術不僅顛覆了傳統產業,更改變了人們原有的生產生活方式。隨著中國環境
分布式爬蟲系統設計、實現與實戰:爬取京東、蘇寧易購全網手機商品數據+MySQL、HBase存儲
大數據 分布式 爬蟲 Java Redis [TOC] 1 概述 在不用爬蟲框架的情況,經過多方學習,嘗試實現了一個分布式爬蟲系統,並且可以將數據保存到不同地方,類似MySQL、HBase等。 基於面向接口的編碼思想來開發,因此這個系統具有一定的擴展性,有興趣的朋友直接看一下代碼,就能理
基於WebGIS的Web服務器日誌管理系統設計與實現_愛學術——免費下載
富客戶端 平臺 .com 服務器日誌 操作 shu 實現 c51 bsp 【摘要】WebGIS優勢是通過互聯網對地理空間數據進行發布和應用,以實現空間數據的共享和相互操作。將WebGIS和富客戶端技術引入Web服務器日誌管理領域,從總體設計、數據庫設計、實現框架等幾個方面設
基於Web的企業排班管理系統設計與實現_愛學術——免費下載
安全 html 快速 開發框架 管理 document 企業 search src 【摘要】隨著我國企業的快速發展,落後的排班方式正日益影響企業的工作效率。本文即探討基於Web的企業排班管理。提出基於SSH開發框架並結合MVC設計模式來開發企業排班管理系統,提高系統的安全性
機房環境監控系統設計與實施重點!
機房環境監控系統的設計方案是否合理、優化、實用,決定了前期投資的經濟性。因此,機房的總體設計方案的確定是很重要的,這取決於設計的理念和技術水平。 建設方一般對機房前期的建設比較慎重,要選擇有技術實力的設計單位和技術人員進行機房的設計和施工,以保證機房方案的經濟實用和機房的施工質量的保證。 機房裡除了擺
基於James技術的企業電子郵件系統設計與實現
基於James技術的企業電子郵件系統設計與實現 轉載:https://www.taodocs.com/p-156363658.html 1、簡介
【活動預告】NEO區塊鏈公開課(5):NNS系統設計與實現
NEO區塊鏈公開課第5期: 主題:NEL精品課程之NNS系統設計與實現 時間:10月20日13:30—17:00 地點:上海市楊浦區政學路77號INNOSPACE 1樓IPOCLUB 報名連結:http://www.huodongxing.c
【架構】分散式追蹤系統設計與實現
分散式系統為什麼需要 Tracing? 先介紹一個概念:分散式跟蹤,或分散式追蹤。 電商平臺由數以百計的分散式服務構成,每一個請求路由過來後,會經過多個業務系統並留下足跡,併產生對各種Cache或DB的訪問,但是這些分散的資料對於問題排查,或是流程優化都幫助有限。
在Ubuntu主機下實現與Windows虛擬機器共享資料夾
一.概述 由於要實現Ubuntu主機中的一些檔案與Windows虛擬機器共享,因此要建立一個共享資料夾對映到虛擬機器中. 網上許多都是Windows主機+Linux虛擬機器的配置,在此分享主機是Linux的. 主機:Ubuntu 桌面版18.04 虛擬機器:Virtual Box,Windows7
資料倉庫建設-OLAP和資料立方體
一、OALP概述 資料立方體,他是一種用於OLAP以及OLAP操作(如上卷、下鑽、切片和切塊)的多維資料模型。資料立方體儲存多為聚集資訊。每個單元存放一個聚集值,對應於多維空間的一個數據點。每個屬性都可能存在概念分層,允許在多個抽象層進行資料分析。
《超市智慧化管理系統設計與實現》論文筆記(四)
一、基本資訊 標題:超市智慧化管理系統設計與實現 時間:2014 來源:電子科技大學 關鍵詞:超市; 資料庫; 商品; 窗體; 控制元件; 二、研究內容 1.主要內容: 該篇論文主要表述的是完成一個超