
語義分割演算法總結(一)
注:
在本文中經常會提到輸出資料的維度,為了防止讀者產生錯誤的理解,在本文的開頭做一下說明。
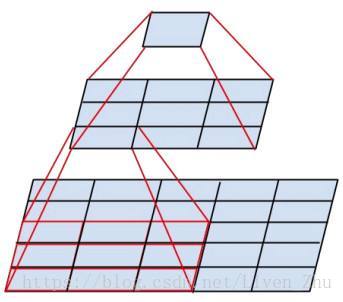
如上圖,原始影象大小為5*5,經過一次卷積後,影象變為3*3。那就是5*5的輸入,經過一個卷積層後,輸出的維度變為3*3,再經過一個卷積層,輸出的維度變為1*1,這裡的5*5,3*3和1*1即為本文提到的資料的維度。
1、什麼是語義分割
影象語義分割可以說是影象理解的基石性技術,在自動駕駛系統(具體為街景識別與理解)、無人機應用(著陸點判斷)以及穿戴式裝置應用中舉足輕重。我們都知道,影象是由許多畫素(Pixel)組成,而「語義分割」顧名思義就是將畫素按照影象中表達語義含義的不同進行分組(Grouping)/分割(Segmentation)。

上面的圖片就是一個具體的語義分割的例子。左邊的實際圖片作為輸入,我們想要通過一定的演算法,得出右邊的分割圖片。
2、 語義分割演算法介紹
2.1 FCNN(全連線卷積神經網路)
2014年,來自UC Berkeley 的Trevor Darrell 組在2014年提出了全連線的卷積神經網路,開啟了卷積神經網路應用在語義分割的先河。由於用於影象分類和檢測的卷積神經網路關注的是影象級,所以在卷積網路的後面會有全連線層,用於降低網路的維度,輸出我們想要的分類資訊和位置資訊;但是語義分割關注的是影象的畫素級(Pixel-level),我們希望輸入的是一張圖片,輸出的仍然是尺寸基本一致的圖片,所以在FCNN中,去掉了一般卷積網路後面的全連線層。
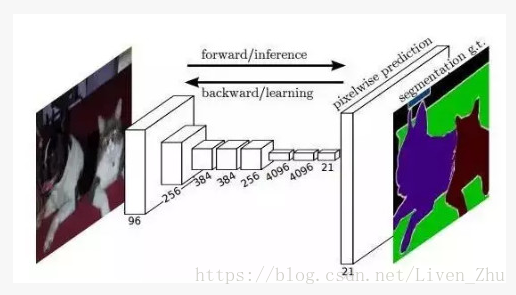
上圖就是FCNN的基本架構。在經過一個全卷積的預訓練的網路之後,比如說VGG,由於池化操作降低了影象空間維度,特徵map仍然需要被上取樣。與簡單的雙線性插值不同,反捲積層可以學習插值。該層也叫上卷積(upconvolution),全卷積(full convolution),轉置卷積(transpose convolution)或者分數化卷積(fractionally-strided convolution)。
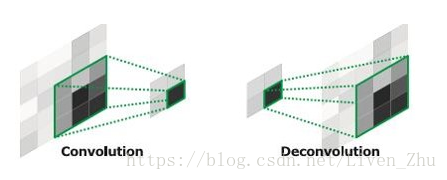
然而,上取樣(即反捲積層)產生粗糙的分割圖,是因為在池化過程中資訊的丟失。因此,跳轉連線能夠產生解析度更高的特徵對應圖。
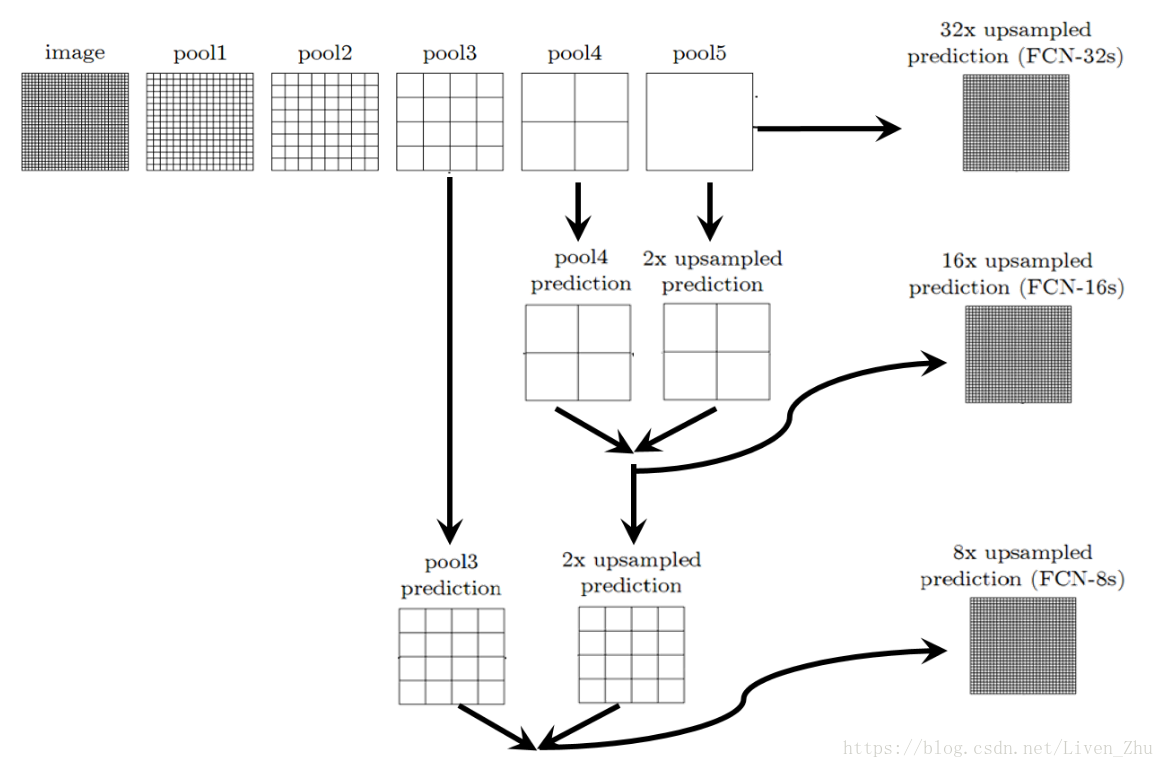
跳轉連線如上圖。我們不再僅僅用最後的池化層的輸出的來進行反捲積,而是利用前面的池化層的輸出為我們提供更多的原始圖片的資訊。原文的作者對這種方案進行了對比:
1、用pool5的輸出作為上取樣(反捲積)的輸入,由於經過了5個池化層,影象被縮小到原始影象的1/32,所以使用上取樣將pool5的輸出放大32倍,得到一個32倍放大的分割圖。
2、用pool5的輸出採用上取樣2倍放大,與pool4的輸出疊加後,再經過上取樣16倍放大,得到一個輸出16倍放大的分割圖。
3、將pool5和pool4的疊加和2倍放大後,再疊加pool3的輸出,然後呢進行上取樣8倍放大,最後得到一個8倍放大的分割圖。
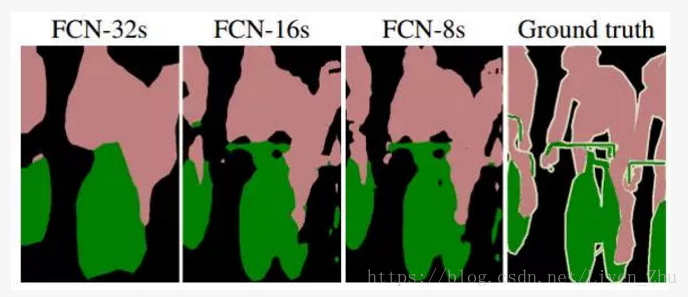
上圖就是三種分割方案與真實分割的對比,顯然,採用第三種分割方案的解析度更高。這是由於,僅採用pool5的輸出做上取樣進行32倍放大,由於pool5輸出的每一個元素的感受域更大,導致原始影象中很多細節的特徵丟失,所以得到的分割圖就相對比較粗糙。而後面的兩種方案,分別加進了前面池化層的輸出,由於前面池化層的輸出資料的每一個元素的感受域相對較小,所以很多原始影象的細節特徵得以保留,得到的分割圖的解析度就更高。
下面簡單說一下什麼是感受域?
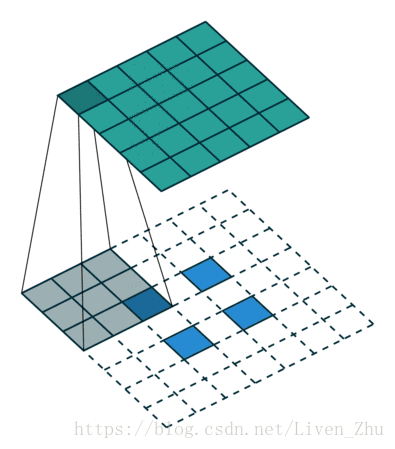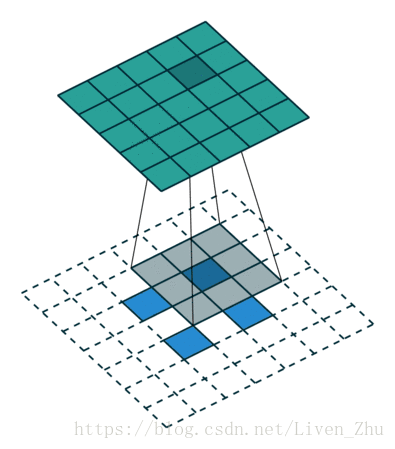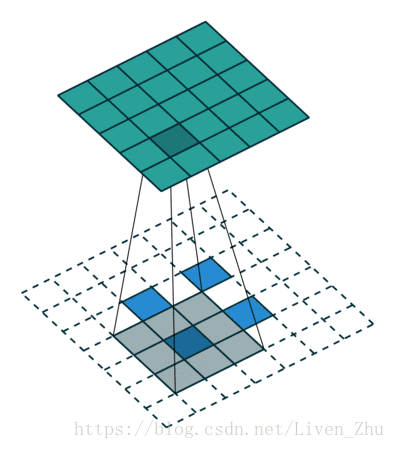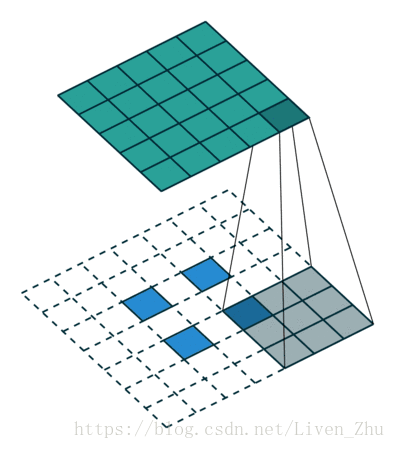
感受域主要取決於卷積和池化的kernel和stride的大小。如上動圖,在kernel大小為3*3,stride為1時,經過一個卷積層後,每一個畫素的感受域即為9。所以在經過更多層卷積和池化後,圖片的維度越來越小,每個元素的感受域也就會越來越大。
2.2 SegNet
SegNet是基於FCNN的架構提出的。下面先來看一下SegNet的結構:
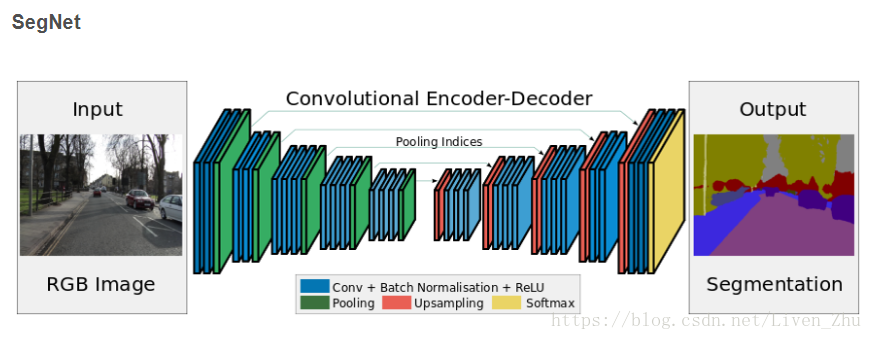
FCNN的缺點就是得到的分割圖的解析度較低,因此SegNet在FCNN的基礎上增加了上池化層。

上池化層相對於池化層與反捲積相對於卷積層類似,也是將低維資料擴充套件到高維。在SegNet前半段進行池化時,記住每一個池化輸出在池化輸入中的位置,然後在上池化時,將該輸出周圍相應的位置填0,即完成了資料維度的放大。
SegNet採用了一種完全對稱的結構,卷積與反捲積對稱,池化和上池化對稱,由此構成了一個encoder-decoder的結構。
2.3 Dilated Convolutions
在利用CNN進行影象分類時,pooling可以通過增加感受域的大小,從而對影象的巨集觀特徵有更好的描述,有助於進行分類。而在進行影象分割任務時,我們關注的是影象的畫素級,使用pooling增加了感受域的大小,但是卻使影象的很多細小特徵丟失了,這樣導致分割出來的影象解析度很低,於是有學者就提出了基於稀疏卷積核的卷積網路。
那麼什麼是基於稀疏卷積核的卷積呢?我們用下面的圖來簡單介紹一下:

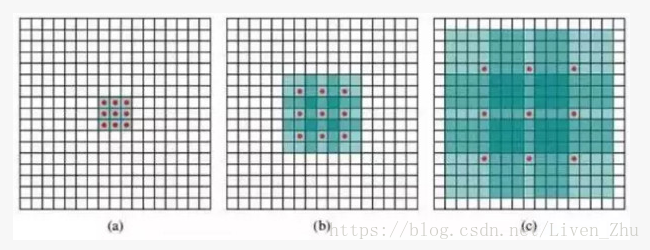
紅點表示卷積核的元素,綠色表示感受域,黑線框表示輸入影象。
(a) 為原始卷積核計算時覆蓋的感受域,(b)和(c) 為當卷積核覆蓋的元素間距離增大的情況,不再在連續的空間內去做卷積,跳著做,當這個距離增加的越大時,單次計算覆蓋的感受域面積越大。
這種卷積的好處就是,在不增加訓練引數的情況下(中間的空格用0填入,不需訓練,但是也要參與計算,因此會增加計算量,後文會提到),增大了輸出影象中每一個元素的感受域。
Dilated Convolutions的思路就是將用於分類的神經網路(論文裡為VGG)的最後兩個池化層去掉,用這種基於稀疏卷積核的卷積網路代替。這樣,我們在不降低感受域大小的同時,使輸出的資料的維度更大,保留了更多的原始影象的細小特徵,避免了池化層降低資料維度造成的細小特徵丟失的問題。
請繼續檢視後面的語義分割演算法總結(二)