
數學建模演算法總結(一)
§1 線性規劃
在人們的生產實踐中,經常會遇到如何利用現有資源來安排生產,以取得最大經濟效益的問題。此類問題構成了運籌學的一個重要分支—數學規劃,而線性規劃(Linear
Programming 簡記 LP)則是數學規劃的一個重要分支。
1.1 線性規劃的 Matlab 標準形式
線性規劃的目標函式可以是求最大值,也可以是求最小值,約束條件的不等號可以是小於號也可以是大於號。為了避免這種形式多樣性帶來的不便,Matlab 中規定線性
規劃的標準形式為
其中 c 和 x 為 n 維列向量, A 、 Aeq 為適當維數的矩陣, b 、 beq 為適當維數的列向量。
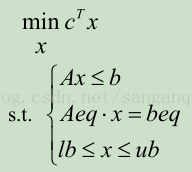
1.2相關問題
運輸問題(產銷平衡)、指派問題(匈牙利演算法)、對偶理論與靈敏度分析、投資的收益和風險
§2 整數規劃
2.1 定義
規劃中的變數(部分或全部)限制為整數時,稱為整數規劃。若在線性規劃模型中,變數限制為整數,則稱為整數線性規劃。目前所流行的求解整數規劃的方法,往往只適
用於整數線性規劃。目前還沒有一種方法能有效地求解一切整數規劃。
2.2 整數規劃的分類
如不加特殊說明,一般指整數線性規劃。對於整數線性規劃模型大致可分為兩類:
1 變數全限制為整數時,稱純(完全)整數規劃。
2 變數部分限制為整數的,稱混合整數規劃。
2.3 整數規劃特點
(i) 原線性規劃有最優解,當自變數限制為整數後,其整數規劃解出現下述情況:
①原線性規劃最優解全是整數,則整數規劃最優解與線性規劃最優解一致。
②整數規劃無可行解。
③有可行解(當然就存在最優解),但最優解值變差。
(ii) 整數規劃最優解不能按照實數最優解簡單取整而獲得。
2.4 求解方法分類:
(i)分枝定界法—可求純或混合整數線性規劃。
(ii)割平面法—可求純或混合整數線性規劃。
(iii)隱列舉法—求解“0-1”整數規劃:
①過濾隱列舉法;
②分枝隱列舉法。
(iv)匈牙利法—解決指派問題(“0-1”規劃特殊情形)。
(v)蒙特卡洛法—求解各種型別規劃。
§3 非線性規劃
如果目標函式或約束條件中包含非線性函式,就稱這種規劃問題為非線性規劃問題。一般說來,解非線性規劃要比解線性規劃問題困難得多。而且,也不象線性規劃有
單純形法這一通用方法,非線性規劃目前還沒有適於各種問題的一般演算法,各個方法都有自己特定的適用範圍。
3.1 線性規劃與非線性規劃的區別
如果線性規劃的最優解存在,其最優解只能在其可行域的邊界上達到(特別是可行域的頂點上達到);而非線性規劃的最優解(如果最優解存在)則可能在其可行域的任
意一點達到。
3.2 非線性規劃的 Matlab 解法
Matlab 中非線性規劃的數學模型寫成以下形式
其中f(x)是標量函式, Beq,Aeq,B,A 是相應維數的矩陣和向量, Ceq(x),C(x) 是非線性向量函式。
Matlab 中的命令是
X=FMINCON(FUN,X0,A,B,Aeq,Beq,LB,UB,NONLCON,OPTIONS)
它的返回值是向量 x ,其中 FUN 是用 M 檔案定義的函式f(x);X0 是 x 的初始值;A,B,Aeq,Beq 定義了線性約束 Beq= X *Aeq , A*x≤ B,如果沒有線性約束,則A=[],B=[],Aeq=[],Beq=[];LB 和 UB 是變數 x 的下界和上界,如果上界和下界沒有約束,則 LB=[],UB=[],如果 x 無下界,則 LB 的各分量都為-inf,如果 x 無上界,則 UB的各分量都為 inf;NONLCON 是用 M 檔案定義的非線性向量函式Ceq(x),C(x)
;OPTIONS定義了優化引數,可以使用 Matlab 預設的引數設定。
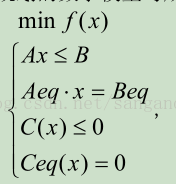
3.3 相應問題
無約束問題(一維搜尋方法、二次插值法、無約束極值問題的解法)、約束極值問題(二次規劃、罰函式法)、飛行管理問題
§4 動態規劃(搞ACM的較熟)
動態規劃(dynamic programming)是運籌學的一個分支,是求解決策過程(decisionprocess)最優化的數學方法。例如最短路線、庫存管理、資源分配、裝置更新、排序、裝載等問題,用動態規劃方法比用其它方法求解更為方便。
雖然動態規劃主要用於求解以時間劃分階段的動態過程的優化問題,但是一些與時間無關的靜態規劃(如線性規劃、非線性規劃),只要人為地引進時間因素,把它視為多階段決策過程,也可以用動態規劃方法方便地求解。應指出,動態規劃是求解某類問題的一種方法,是考察問題的一種途徑,而不是一種特殊演算法(如線性規劃是一種演算法)。因而,它不象線性規劃那樣有一個標準的數學表示式和明確定義的一組規則,而必須對具體問題進行具體分析處理。因此,在學習時,除了要對基本概念和方法正確理解外,應以豐富的想象力去建立模型,用創造性的技巧去求解。
§5 與網路模型及方法(搞ACM的較熟)
圖論中所謂的“圖”是指某類具體事物和這些事物之間的聯絡。如果我們用點表示這些具體事物,用連線兩點的線段(直的或曲的)表示兩個事物的特定的聯絡,就得到了描述這個“圖”的幾何形象。圖論為任何一個包含了一種二元關係的離散系統提供了一個數學模型,藉助於圖論的概念、理論和方法,可以對該模型求解。哥尼斯堡七橋問題就是一個典型的例子。在哥尼斯堡有七座橋將普萊格爾河中的兩個島及島與河岸聯結起來,問題是要從這四塊陸地中的任何一塊開始通過每一座橋正好一次,再回到起點。
圖與網路是運籌學(Operations Research)中的一個經典和重要的分支,所研究的問題涉及經濟管理、工業工程、交通運輸、電腦科學與資訊科技、通訊與網路技術等諸多領域。主要包括最短路問題、最大流問題、最小費用流問題和匹配問題等。
§6 排隊論模型(2017年美賽B題,2005年美賽B題主要涉及排隊論)
排隊是在日常生活中經常遇到的現象,如顧客到商店購買物品、病人到醫院看病常常要排隊。此時要求服務的數量超過服務機構(服務檯、服務員等)的容量。也就是說,到達的顧客不能立即得到服務,因而出現了排隊現象。這種現象不僅在個人日常生活中出現,電話局的佔線問題,車站、碼頭等交通樞紐的車船堵塞和疏導,故障機器的停機待修,水庫的存貯調節等都是有形或無形的排隊現象。由於顧客到達和服務時間的隨機性。可以說排隊現象幾乎是不可避免的。
排隊論(Queuing Theory)也稱 隨機服務系統理論,就是為解決上述問題而發展的一門學科。它研究的內容有下列三部分:
(i)性態問題,即研究各種排隊系統的概率規律性,主要是研究隊長分佈、等待時間分佈和忙期分佈等,包括了瞬態和穩態兩種情形。
(ii)最優化問題,又分靜態最優和動態最優,前者指最優設計。後者指現有排隊系統的最優運營。
(iii)排隊系統的統計推斷,即判斷一個給定的排隊系統符合於哪種模型,以便根據排隊理論進行分析研究。
6.1 排隊系統的組成和特徵
一般的排隊過程都由輸入過程、排隊規則、服務過程三部分組成,現分述如下:
6.1.1 輸入過程
輸入過程是指顧客到來時間的規律性,可能有下列不同情況:
(i)顧客的組成可能是有限的,也可能是無限的。
(ii)顧客到達的方式可能是一個—個的,也可能是成批的。
(iii)顧客到達可以是相互獨立的,即以前的到達情況對以後的到達沒有影響;否則是相關的。
(iv)輸入過程可以是平穩的,即相繼到達的間隔時間分佈及其數學期望、方差等數字特徵都與時間無關,否則是非平穩的。
6.1.2 排隊規則
排隊規則指到達排隊系統的顧客按怎樣的規則排隊等待,可分為損失制,等待制和混合制三種。
(i)損失制(消失制)。當顧客到達時,所有的服務檯均被佔用,顧客隨即離去。
(ii)等待制。當顧客到達時,所有的服務檯均被佔用,顧客就排隊等待,直到接受完服務才離去。例如出故障的機器排隊等待維修就是這種情況。
(iii)混合制。介於損失制和等待制之間的是混合制,即既有等待又有損失。有佇列長度有限和排隊等待時間有限兩種情況,在限度以內就排隊等待,超過一定限度就離去。
排隊方式還分為單列、多列和迴圈佇列。
6.1.3 服務過程
(i)服務機構。主要有以下幾種型別:單服務檯;多服務檯並聯(每個服務檯同時為不同顧客服務);多服務檯串聯(多服務檯依次為同一顧客服務);混合型。
(ii)服務規則。按為顧客服務的次序採用以下幾種規則:
①先到先服務,這是通常的情形。
②後到先服務,如情報系統中,最後到的情報資訊往往最有價值,因而常被優先處理。
③隨機服務,服務檯從等待的顧客中隨機地取其一進行服務,而不管到達的先後。
④優先服務,如醫療系統對病情嚴重的病人給予優先治療。
§7 對策論(搞ACM的較熟)
對策論亦稱競賽論或博弈論。是研究具有鬥爭或競爭性質現象的數學理論和方法。一般認為,它既是現代數學的一個新分支,也是運籌學中的一個重要學科。對策論發展的歷史並不長,但由於它所研究的現象與人們的政治、經濟、軍事活動乃至一般的日常生活等有著密切的聯絡,並且處理問題的方法又有明顯特色。所以日益引起廣泛的注意。
在日常生活中,經常看到一些具有相互之間鬥爭或競爭性質的行為。具有競爭或對抗性質的行為稱為 對策行為。在這類行為中。參加鬥爭或競爭的各方各自具有不同的目標和利益。為了達到各自的目標和利益,各方必須考慮對手的各種可能的行動方案,併力圖選取對自己最為有利或最為合理的方案。對策論就是研究對策行為中鬥爭各方是否存在著最合理的行動方案,以及如何找到這個合理的行動方案的數學理論和方法。
§8 層次分析法
層次分析法(Analytic Hierarchy Process,簡稱 AHP)是對一些較為複雜、較為模糊的問題作出決策的簡易方法,它特別適用於那些難於完全定量分析的問題。
層次分析法的基本原理與步驟
人們在進行社會的、經濟的以及科學管理領域問題的系統分析中,面臨的常常是一個由相互關聯、相互制約的眾多因素構成的複雜而往往缺少定量資料的系統。層次分析法為這類問題的決策和排序提供了一種新的、簡潔而實用的建模方法。運用層次分析法建模,大體上可按下面四個步驟進行:
(i)建立遞階層次結構模型;
(ii)構造出各層次中的所有判斷矩陣;
(iii)層次單排序及一致性檢驗;
(iv)層次總排序及一致性檢驗。
下面分別說明這四個步驟的實現過程。
8.1 遞階層次結構的建立與特點
應用 AHP 分析決策問題時,首先要把問題條理化、層次化,構造出一個有層次的結構模型。在這個模型下,複雜問題被分解為元素的組成部分。這些元素又按其屬性及關係形成若干層次。上一層次的元素作為準則對下一層次有關元素起支配作用。
這些層次可以分為三類:
(i)最高層:這一層次中只有一個元素,一般它是分析問題的預定目標或理想結果,因此也稱為目標層。
(ii)中間層:這一層次中包含了為實現目標所涉及的中間環節,它可以由若干個層次組成,包括所需考慮的準則、子準則,因此也稱為準則層。
(iii)最底層:這一層次包括了為實現目標可供選擇的各種措施、決策方案等,因此也稱為措施層或方案層。
遞階層次結構中的層次數與問題的複雜程度及需要分析的詳盡程度有關,一般地層次數不受限制。每一層次中各元素所支配的元素一般不要超過 9 個。這是因為支配的元素過多會給兩兩比較判斷帶來困難。
層次分析法的應用
在應用層次分析法研究問題時,遇到的主要困難有兩個:(i)如何根據實際情況抽象出較為貼切的層次結構;(ii)如何將某些定性的量作比較接近實際定量化處理。
層次分析法對人們的思維過程進行了加工整理,提出了一套系統分析問題的方法,為科學管理和決策提供了較有說服力的依據。但層次分析法也有其侷限性,主要表現在:
(i)它在很大程度上依賴於人們的經驗,主觀因素的影響很大,它至多隻能排除思維過程中的嚴重非一致性,卻無法排除決策者個人可能存在的嚴重片面性。(ii)比較、判斷過程較為粗糙,不能用於精度要求較高的決策問題。AHP 至多隻能算是一種半定量(或定性與定量結合)的方法。
在應用層次分析法時,建立層次結構模型是十分關鍵的一步。
§9 插值與擬合
插值:求過已知有限個數據點的近似函式。
擬合:已知有限個數據點,求近似函式,不要求過已知資料點,只要求在某種意義下它在這些點上的總偏差最小。
插值和擬合都是要根據一組資料構造一個函式作為近似,由於近似的要求不同,二者的數學方法上是完全不同的。而面對一個實際問題,究竟應該用插值還是擬合,有時容易確定,有時則並不明顯。
插值方法
幾種基本的、常用的插值:拉格朗日多項式插值、牛頓插值、分段線性插值、Hermite 插值和三次樣條插值。
曲線擬合的線性最小二乘法(線性最小二乘法)
最小二乘優化(lsqlin 函式、lsqcurvefit 函式、lsqnonlin 函式、lsqnonneg 函式)
§10 資料的統計描述和分析
數理統計研究的物件是受隨機因素影響的資料,以下數理統計就簡稱統計,統計是以概率論為基礎的一門應用學科。資料樣本少則幾個,多則成千上萬,人們希望能用少數幾個包含其最多相關資訊的數值來體現資料樣本總體的規律。描述性統計就是蒐集、整理、加工和分析統計資料,使之系統化、條理化,以顯示出資料資料的趨勢、特徵和數量關。它是統計推斷的基礎,實用性較強,在統計工作中經常使用。面對一批資料如何進行描述與分析,需要掌握引數估計和假設檢驗這兩個數理統計的最基本方法。我們將用Matlab
的統計工具箱(Statistics Toolbox)來實現資料的統計描述和分析。