
SLAM的開源以及在移動端AR的適用分析
當前的開源方案
當下部分總結引用自blog:http://blog.csdn.net/OnafioO/article/details/73175835文章總結很好沒本文關於其在移動端方面加以總結,希望大家參與討論,不足之處,請指正。
本講的前半部分將帶領讀者參觀一下當前的視覺SLAM方案,評述其歷史地位和優缺點。表1列舉了一些常見的開源SLAM方案,讀者可以選擇感興趣的方案進行研究和實驗。限於篇幅,我們只選了一部分有代表性的方案,這肯定是不全面的。在後半部分,我們將探討未來可能的一些發展方向,並給出當前的一些研究成果。
表1 常用開源 SLAM 方案
MonoSLAM
說到視覺SLAM,很多研究者第一個想到的是A. J. Davison的單目SLAM工作。Davison教授是視覺SLAM研究領域的先驅,他在2007年提出的MonoSLAM是第一個實時的單目視覺SLAM系統[2],被認為是許多工作的發源地。MonoSLAM以擴充套件卡爾曼濾波為後端,追蹤前端非常稀疏的特徵點。由於EKF在早期SLAM中佔據著明顯主導地位,所以MonoSLAM亦是建立在EKF的基礎之上,以相機的當前狀態和所有路標點為狀態量,更新其均值和協方差。
圖1所示是MonoSLAM在執行時的情形。可以看到,單目相機在一幅影象當中追蹤了非常稀疏的特徵點(且用到了主動追蹤技術)。在EKF中,每個特徵點的位置服從高斯分佈,所以我們能夠以一個橢球的形式表達它的均值和不確定性。在該圖的右半部分,我們可以找到一些在空間中分佈著的小球。它們在某個方向上顯得越長,說明在該方向的位置就越不確定。我們可以想象,如果一個特徵點收斂,我們應該能看到它從一個很長的橢球(相機Z方向上非常不確定)最後變成一個小點的樣子。

圖1 MonoSLAM的執行時截圖。左側:追蹤特徵點在影象中的表示; 右側:特徵點在三維空間中的表示。
這種做法在今天看來固然存在許多弊端,但在當時已經是里程碑式的工作了,因為在此之前的視覺SLAM系統基本不能線上執行,只能靠機器人攜帶相機採集資料,再離線地進行定位與建圖。計算機效能的進步,以及用稀疏的方式處理影象,加在一起才使得一個SLAM系統能夠線上地執行。從現代的角度來看,MonoSLAM存在諸如應用場景很窄,路標數量有限,稀疏特徵點非常容易丟失的情況,對它的開發也已經停止,取而代之的是更先進的理論和程式設計工具。不過這並不妨礙我們對前人工作的理解和尊敬。幾個月以後再來看當初入門時候的這篇文章 更加佩服這些先驅 參加過第一屆全國SLAM大會以後碰到很有優秀的人 ,respect砥礪前行!!!
PTAM
2007年,Klein等人提出了PTAM(Parallel Tracking and Mapping),這也是視覺SLAM發展過程中的重要事件。PTAM的重要意義在於以下兩點:
- PTAM提出並實現了跟蹤與建圖過程的並行化。我們現在已然清楚,跟蹤部分需要實時響應影象資料,而對地圖的優化則沒必要實時地計算。後端優化可以在後臺慢慢進行,然後在必要的時候進行執行緒同步即可。這是視覺SLAM中首次區分出前後端的概念,引領了後來許多視覺SLAM系統的設計(我們現在看到的SLAM多半都分前後端)。
- PTAM是第一個使用非線性優化,而不是使用傳統的濾波器作為後端的方案。它引入了關鍵幀機制:我們不必精細地處理每一幅影象,而是把幾個關鍵影象串起來,然後優化其軌跡和地圖。早期的SLAM大多數使用EKF濾波器或其變種,以及粒子濾波器等;在PTAM之後,視覺SLAM研究逐漸轉向了以非線性優化為主導的後端。由於之前人們未認識到後端優化的稀疏性,所以覺得優化後端無法實時處理那樣大規模的資料,而PTAM則是一個顯著的反例。
PTAM同時是一個增強現實軟體,演示了酷炫的AR效果(如所示)。根據PTAM估計的相機位姿,我們可以在一個虛擬的平面上放置虛擬物體,看起來就像在真實的場景中一樣。
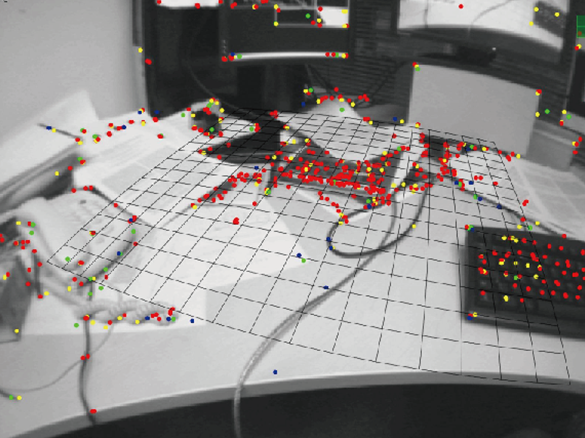
圖2 PTAM的演示截圖。它既可以提供實時的定位和建圖,也可以在虛擬平面上疊加虛擬物體。
不過,從現代的眼光看來,PTAM也算是早期的結合AR的SLAM工作之一。與許多早期工作相似,存在著明顯的缺陷:場景小,跟蹤容易丟失,等等。這些又在後續的方案中得以修正。
ptam可以經適當的改進適用於AR的移動端的開發,但是其還不是一種比較成熟的框架,具有先天缺陷,而這些則是手機端現階段的面臨的主要問題。有單個有待克服的問題以及演算法改進思路如下:1、計算能力不足的問題,需要改進演算法的效率兼顧精度,研究適合移動端的相關關演算法 (neon) 2、窄視野問題,導致外點的增加如何克服 3、捲簾快門旋轉問題等
ORB-SLAM
介紹了歷史上的幾種方案之後,我們來看現代的一些SLAM系統。ORB-SLAM是PTAM的繼承者中非常有名的一位(見圖3)。它提出於2015年,是現代SLAM系統中做得非常完善、非常易用的系統之一(如果不是最完善易用的話)。ORB-SLAM代表著主流的特徵點SLAM的一個高峰。相比於之前的工作,ORB-SLAM具有以下幾條明顯的優勢:
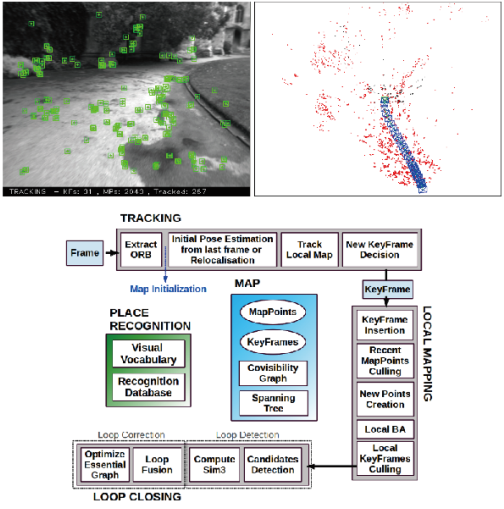
圖3 ORB-SLAM執行截圖。左側為影象與追蹤到的特徵點,右側為相機軌跡與建模的特徵點地圖。下方為其標誌性的三執行緒結構。
- 支援單目、雙目、RGB-D三種模式(17年發表 tansactions on robotics)。這使得無論我們拿到了哪種常見的感測器,都可以先放到ORB-SLAM上測試一下,它具有良好的泛用性。
- 整個系統圍繞ORB特徵進行計算,包括視覺里程計與回環檢測的ORB字典。它體現出ORB特徵是現階段計算平臺的一種優秀的效率與精度之間的折中方式。ORB不像SIFT或SURF那樣費時,在CPU上面即可實時計算;相比Harris角點等簡單角點特徵,又具有良好的旋轉和縮放不變性。並且,ORB提供描述子,使我們在大範圍運動時能夠進行迴環檢測和重定位(實際執行中國的效果還是不如SIFT,單純可靠性的按進度來說,SIFT是最好的,也是目前喝多研究者們的使用的特徵,是一種十分可靠的特徵提取和表達的方式)。
- ORB的迴環檢測是它的亮點。優秀的迴環檢測演算法保證了ORB-SLAM有效地防止累積誤差,並且在丟失之後還能迅速找回,這一點許多現有的SLAM系統都不夠完善。為此,ORB-SLAM在執行之前必須載入一個很大的ORB字典 。
- ORB-SLAM創新式地使用了三個執行緒完成SLAM:實時跟蹤特徵點的Tracking執行緒,區域性Bundle Adjustment的優化執行緒(Co-visibility Graph,俗稱小圖),以及全域性Pose Graph的迴環檢測與優化執行緒(Essential Graph俗稱大圖)。其中,Tracking執行緒負責對每幅新來的影象提取ORB特徵點,並與最近的關鍵幀進行比較,計算特徵點的位置並粗略估計相機位姿。小圖執行緒求解一個Bundle Adjustment問題,它包括區域性空間內的特徵點與相機位姿。這個執行緒負責求解更精細的相機位姿與特徵點空間位置。不過,僅有前兩個執行緒,只完成了一個比較好的視覺里程計。第三個執行緒,也就是大圖執行緒,對全域性的地圖與關鍵幀進行迴環檢測,消除累積誤差。由於全域性地圖中的地圖點太多,所以這個執行緒的優化不包括地圖點,而只有相機位姿組成的位姿圖。繼PTAM的雙執行緒結構之後,ORB-SLAM的三執行緒結構取得了非常好的跟蹤和建圖效果,能夠保證軌跡與地圖的全域性一致性。這種三執行緒結構也將被後續的研究者認同和採用。總之,沿用了前人的額思想將系統分別多執行緒併發處理,前端為資料的採集與實時的粗處理,後端沿用BA處理,區分實時性,小圖的處理使得系統可以實時的實現對空間特徵的位置求解和相機的位姿的求解;大圖的執行緒的到全域性優化,不追求實時處理,只需呼叫前的處理結果即可。
- ORB-SLAM圍繞特徵點進行了不少的優化。例如,在OpenCV的特徵提取基礎上保證了特徵點的均勻分佈,在優化位姿時使用了一種迴圈優化4遍以得到更多正確匹配的方法,比PTAM更為寬鬆的關鍵幀選取策略,等等。這些細小的改進使得ORB-SLAM具有遠超其他方案的穩健性:即使對於較差的場景,較差的標定內參,ORB-SLAM都能夠順利地工作。
上述這些優勢使得ORB-SLAM在特徵點SLAM中達到頂峰,許多研究工作都以ORB-SLAM作為標準,或者在它的基礎上進行後續的開發。它的程式碼以清晰易讀著稱,有著完善的註釋,可供後來的研究者進一步理解。
當然,ORB-SLAM也存在一些不足之處。首先,由於整個SLAM系統都採用特徵點進行計算,我們必須對每幅影象都計算一遍ORB特徵,這是非常耗時的。ORB-SLAM的三執行緒結構也給CPU帶來了較重的負擔,使得它只有在當前PC架構的CPU上才能實時運算,移植到嵌入式裝置上則有一定困難(近期,我又接著做了一些移動端的工作,結果顯示,移植後如果嫩能夠優化的不錯的話,還是可以實時執行的)。其次,ORB-SLAM的建圖為稀疏特徵點,目前還沒有開放儲存和讀取地圖後重新定位的功能(雖然從實現上來講並不困難)。根據我們在建圖部分的分析,稀疏特徵點地圖只能滿足我們對定位的需求,而無法提供導航、避障、互動等諸多功能。然而,如果我們僅用ORB-SLAM處理定位問題,似乎又顯得有些過於重量級了。相比之下,另外一些方案提供了更為輕量級的定位,使我們能夠在低端的處理器上執行SLAM,或者讓CPU有餘力處理其他的事務。
此法,在應用的實用性上面具有較好的可以拓展性,小編你正在學習的過程中
LSD-SLAM
LSD-SLAM(Large Scale Direct monocular SLAM)是J. Engle等人於2014年提出的SLAM工作。類比於ORB-SLAM之於特徵點,LSD-SLAM則標誌著單目直接法在SLAM中的成功應用。LSD-SLAM的核心貢獻是將直接法應用到了半稠密的單目SLAM中。它不僅不需要計算特徵點,還能構建半稠密的地圖——這裡半稠密的意思主要是指估計梯度明顯的畫素位置。它的主要優點如下:
- LSD-SLAM的直接法是針對畫素進行的。作者有創見地提出了畫素梯度與直接法的關係,以及畫素梯度與極線方向在稠密重建中的角度關係。這些在本書的第8講和第13講均有討論。不過,LSD-SLAM是在單目影象進行半稠密的跟蹤,實現原理要比本書的例程更加複雜。
- LSD-SLAM在CPU上實現了半稠密場景的重建,這在之前的方案中是很少見到的。基於特徵點的方法只能是稀疏的,而進行稠密重建的方案大多要使用RGB-D感測器,或者使用GPU構建稠密地圖。TUM計算機視覺組在多年對直接法研究的基礎上,實現了這種CPU上的實時半稠密SLAM。
- 之前也說過,LSD-SLAM的半稠密追蹤使用了一些精妙的手段來保證追蹤的實時性與穩定性。例如,LSD-SLAM既不是利用單個畫素,也不是利用影象塊,而是在極線上等距離取5個點,度量其SSD;在深度估計時,LSD-SLAM首先用隨機數初始化深度,在估計完後又把深度均值歸一化,以調整尺度;在度量深度不確定性時,不僅考慮三角化的幾何關係,而且考慮了極線與深度的夾角,歸納成一個光度不確定性項;關鍵幀之間的約束使用了相似變換群及與之對應的李代數ζ∈sim(3)顯式地表達出尺度,在後端優化中可以將不同尺度的場景考慮進來,減小了尺度飄移現象。
圖4顯示了LSD的執行情況。我們可以觀察一下這種微妙的半稠密地圖是怎樣一種介於稀疏地圖與稠密地圖之間的形式。半稠密地圖建模了灰度圖中有明顯梯度的部分,顯示在地圖中,很大一部分都是物體的邊緣或表面上帶紋理的部分。LSD-SLAM對它們進行跟蹤並建立關鍵幀,最後優化得到這樣的地圖。看起來比稀疏的地圖具有更多的資訊,但又不像稠密地圖那樣擁有完整的表面(稠密地圖一般認為無法僅用CPU實現實時性)。

圖4 LSD-SLAM執行圖片。上半部分為估計的軌跡與地圖,下半部分為影象中被建模的部分,即具有較好的畫素梯度的部分。
由於LSD-SLAM使用了直接法進行跟蹤,所以它既有直接法的優點(對特徵缺失區域不敏感),也繼承了直接法的缺點。例如,LSD-SLAM對相機內參和曝光非常敏感,並且在相機快速運動時容易丟失。另外,在迴環檢測部分,由於目前並沒有基於直接法實現的迴環檢測方式,因此LSD-SLAM必須依賴於特徵點方法進行迴環檢測,尚未完全擺脫特徵點的計算。
SVO
SVO是Semi-direct Visual Odoemtry的縮寫[56]。它是由Forster等人於2014年提出的一種基於稀疏直接法的視覺里程計。按作者的稱呼應該叫“半直接”法,然而按照本書的理念框架,稱為“稀疏直接法”可能更好一些。半直接在原文中的意思是指特徵點與直接法的混合使用:SVO跟蹤了一些關鍵點(角點,沒有描述子),然後像直接法那樣,根據這些關鍵點周圍的資訊估計相機運動及其位置(如圖4所示)。在實現中,SVO使用了關鍵點周圍的4×4的小塊進行塊匹配,估計相機自身的運動。
相比於其他方案,SVO的最大優勢是速度極快。由於使用稀疏的直接法,它既不必費力去計算描述子,也不必處理像稠密和半稠密那麼多的資訊,因此,即使在低端計算平臺上也能達到實時性,而在PC平臺上則可以達到每秒100多幀的速度。在後續的SVO 2.0中,速度更達到了驚人的每秒400幀。這使得SVO非常適用於計算平臺受限的場合,例如無人機、手持AR/VR裝置的定位。無人機也是作者開發SVO的目標應用平臺。

圖5 SVO跟蹤關鍵點的圖片。
SVO的另一創新之處是提出了深度濾波器的概念,並推導了基於均勻−高斯混合分佈的深度濾波器。這在本書的第13講有提及,但由於原理較為複雜,我們沒有詳細解釋。SVO將這種濾波器用於關鍵點的位置估計,並使用了逆深度作為引數化形式,使之能夠更好地計算特徵點位置。
開源版的SVO程式碼清晰易讀,十分適合讀者作為第一個SLAM例項進行分析。不過,開源版SVO也存在一些問題:
- 由於目標應用平臺為無人機的俯視相機,其視野內的物體主要是地面,而且相機的運動主要為水平和上下的移動,SVO的許多細節是圍繞這個應用設計的,這使得它在平視相機中表現不佳。例如,SVO在單目初始化時,使用了分解H矩陣而不是傳統的F或E矩陣的方式,這需要假設特徵點位於平面上。該假設對俯視相機是成立的,但對平視相機通常是不成立的,可能導致初始化失敗。再如,SVO在關鍵幀選擇時,使用了平移量作為確定新的關鍵幀的策略,而沒有考慮旋轉量。這同樣在無人機俯視配置下是有效的,但在平視相機中則會容易丟失。所以,如果讀者想要在平視相機中使用SVO,必須自己加以修改。
- SVO為了速度和輕量化,捨棄了後端優化和迴環檢測部分,也基本沒有建圖功能。這意味著SVO的位姿估計必然存在累積誤差,而且丟失後不太容易進行重定位(因為沒有描述子用來回環檢測)。所以,我們稱它為一個VO,而不是稱它為完整的SLAM。
RTAB-MAP
介紹了幾款單目SLAM方案後,我們再來看一些RGB-D感測器上的SLAM方案。相比於單目和雙目,RGB-D SLAM的原理要簡單很多(儘管實現上不一定),而且能夠在CPU上實時建立稠密的地圖。
RTAB-MAP(Real Time Appearance-Based Mapping)是RGB-D SLAM中比較經典的一個方案。它實現了RGB-D SLAM中所有應該有的東西:基於特徵的視覺里程計、基於詞袋的迴環檢測、後端的位姿圖優化,以及點雲和三角網格地圖。因此,RTAB-MAP給出了一套完整的(但有些龐大的)RGB-D SLAM方案。目前我們已經可以直接從ROS中獲得其二進位制程式,此外,在Google Project Tango上也可以獲取其App使用(如圖6所示)。

圖6 RTAB-MAP在Google Project Tango上的執行樣例。
RTAB-MAP支援一些常見的RGB-D和雙目感測器,像Kinect、Xtion等,且提供實時的定位和建圖功能。不過由於整合度較高,使得其他開發者在它的基礎上進行二次開發變得困難,所以RTAB-MAP更適合作為SLAM應用而非研究使用。
其他
除了這些開源方案之外,讀者還能在openslam.org之類的網站上找到許多其他的研究,例如,DVO-SLAM、RGBD-SLAM-V2、DSO,以及一些Kinect Fusion相關的工作,等等。隨著時代發展,更新穎、更優秀的開源SLAM作品亦將出現在人們的視野中,限於篇幅這裡就不逐一介紹了。
未來的AR-SLAM話題
看過了現有的方案,我們再來討論一些未來的發展方向。大體上講,SLAM將來的發展趨勢有兩大類:一是朝輕量級、小型化方向發展,讓SLAM能夠在嵌入式或手機等小型裝置上良好執行,然後考慮以它為底層功能的應用。畢竟,大部分場合中,我們的真正目的都是實現機器人、AR/VR裝置的功能,比如說運動、導航、教學、娛樂,而SLAM是為上層應用提供自身的一個位姿估計。在這些應用中,我們不希望SLAM佔用所有計算資源,所以對SLAM的小型化和輕量化有非常強烈的需求,當然,這也是我研究的重心所在,如果有感興趣的朋友,希望有機會和各位多交流。另一方面則是利用高效能運算裝置,實現精密的三維重建、場景理解等功能。在這些應用中,我們的目的是完美地重建場景,而對於計算資源和裝置的便攜性則沒有多大限制。由於可以利用GPU,這個方向和深度學習亦有結合點。未來的一個曉得趨勢就是整合在輕便快捷的普遍持有的裝置的應用上,可以結合各個領域的特點做出,高精度整合系統系的的開發和相關的拓展。
視覺+慣性導航SLAM
首先,我們要談一個有很強應用背景的方向:視覺−慣性導航融合SLAM方案。實際的機器人也好,硬體裝置也好,通常都不會只攜帶一種感測器,往往是多種感測器的融合。可以將slam理解為一個多感測器融合的問題,很控制。學術界的研究人員喜愛“大而且乾淨的問題”(Big Clean Problem),比如說僅用單個攝像頭實現視覺SLAM。但產業界的朋友們則更注重讓演算法更加實用,不得不面對一些複雜而瑣碎的場景。在這種應用背景下,用視覺與慣性導航融合進行SLAM成為了一個關注熱點。
慣性感測器(IMU)能夠測量感測器本體的角速度和加速度,被認為與相機感測器具有明顯的互補性,而且十分有潛力在融合之後得到更完善的SLAM系統(VIN港科大大牛沈老師團隊研發)。為什麼這麼說呢?
- IMU雖然可以測得角速度和加速度,但這些量都存在明顯的漂移(Drift),使得積分兩次得到的位姿資料非常不可靠。好比說,我們將IMU放在桌上不動,用它的讀數積分得到的位姿也會漂出十萬八千里。但是,對於短時間內的快速運動,IMU能夠提供一些較好的估計。這正是相機的弱點。當運動過快時,(捲簾快門的)相機會出現運動模糊,或者兩幀之間重疊區域太少以至於無法進行特徵匹配,所以純視覺SLAM非常害怕快速的運動。而有了IMU,即使在相機資料無效的那段時間內,我們也能保持一個較好的位姿估計,這是純視覺SLAM無法做到的。
- 相比於IMU,相機資料基本不會有漂移。如果相機放在原地固定不動,那麼(在靜態場景下)視覺SLAM的位姿估計也是固定不動的。所以,相機資料可以有效地估計並修正IMU讀數中的漂移,使得在慢速運動後的位姿估計依然有效。
- 當影象發生變化時,本質上我們沒法知道是相機自身發生了運動,還是外界條件發生了變化,所以純視覺SLAM難以處理動態的障礙物。而IMU能夠感受到自己的運動資訊,從某種程度上減輕動態物體的影響。
總而言之,我們看到IMU為快速運動提供了較好的解決方式,而相機又能在慢速運動下解決IMU的漂移問題——在這個意義下,它們二者是互補的。

圖7 越來越多的相機開始整合IMU裝置。
當然,雖然說得很好聽,不管是理論還是實踐,VIO(Visual Inertial Odometry)都是相當複雜的。其複雜性主要來源於IMU測量加速度和角速度這兩個量的事實,所以不得不引入運動學計算。目前VIO的框架已經定型為兩大類:鬆耦合(Loosely Coupled)和緊耦合(Tightly Coupled)。鬆耦合是指IMU和相機分別進行自身的運動估計,然後對其位姿估計結果進行融合。緊耦合是指把IMU的狀態與相機的狀態合併在一起,共同構建運動方程和觀測方程,然後進行狀態估計——這和我們之前介紹的理論非常相似。我們可以預見,緊耦合理論也必將分為基於濾波和基於優化兩個方向。在濾波方面,傳統的EKF以及改進的MSCKF(Multi-State Constraint KF)都取得了一定的成果,研究者對EKF也進行了深入的討論(例如能觀性);優化方面亦有相應的方案。值得一提的是,儘管在純視覺SLAM中優化方法已經佔了主流,但在VIO中,由於IMU的資料頻率非常高,對狀態進行優化需要的計算量就更大,因此目前仍處於濾波與優化並存的階段。由於過於複雜,限於篇幅,這裡就只能大概地介紹一下這個方向了。
VIO為將來SLAM的小型化與低成本化提供了一個非常有效的方向。而且結合稀疏直接法,我們有望在低端硬體上取得良好的SLAM或VO效果,是非常有前景的,這成為眾多同行努力的焦點之一。
語義SLAM
SLAM的另一個大方向就是和深度學習技術結合。到目前為止,SLAM的方案都處於特徵點或者畫素的層級。關於這些特徵點或畫素到底來自於什麼東西???,我們一無所知。這使得計算機視覺中的SLAM與我們人類的做法不怎麼相似,至少我們自己從來看不到特徵點,也不會去根據特徵點判斷自身的運動方向。我們看到的是一個個物體,通過左右眼判斷它們的遠近,然後基於它們在影象當中的運動推測相機的移動,總是深度學習也是一種基於生物啟發式的仿生的基於經驗的演算法,雖然取得很好的效果,但是器裡面的激勵不是很清晰,對於具體的問題沒有一個清晰的定義和數學表達,一個和盒子不利於我們對問題的進一步理解和分析。
很久之前,研究者就試圖將物體資訊結合到SLAM中。很多文章曾把物體識別與視覺SLAM結合起來,基於深度學習的影象分割、識別與三位重建會成為下一個熱點,能力解決是什麼的重要問題和在哪兒的問題,物體標籤的地圖。另一方面,把標籤資訊引入到BA或優化端的目標函式和約束中,我們可以結合特徵點的位置與標籤資訊進行優化。這些工作都可以稱為語義SLAM。綜合來說,SLAM和語義的結合點主要有兩個方面:
- 語義幫助SLAM。傳統的物體識別、分割演算法往往只考慮一幅圖,而在SLAM中我們擁有一臺移動的相機。如果我們把運動過程中的圖片都帶上物體標籤,就能得到一個帶有標籤的地圖。另外,物體資訊亦可為迴環檢測、BA優化帶來更多的條件。
- SLAM幫助語義。物體識別和分割都需要大量的訓練資料。要讓分類器識別各個角度的物體,需要從不同視角採集該物體的資料,然後進行人工標定,非常辛苦。而SLAM中,由於我們可以估計相機的運動,可以自動地計算物體在影象中的位置,節省人工標定的成本。如果有自動生成的帶高質量標註的樣本資料,能夠很大程度上加速分類器的訓練過程。
圖8 語義SLAM的一些結果,左圖和右圖分別來自文獻色sematic slam。

在深度學習廣泛應用之前,我們只能利用支援向量機、條件隨機場等傳統工具對物體或場景進行分割和識別,或者直接將觀測資料與資料庫中的樣本進行比較,嘗試構建語義地圖。由於這些工具本身在分類正確率上存在限制,所以效果也往往不盡如人意。隨著深度學習的發展,我們開始使用網路,越來越準確地對影象進行識別、檢測和分割。這為構建準確的語義地圖打下了更好的基礎。我們正看到,逐漸開始有學者將神經網路方法引入到SLAM中的物體識別和分割,甚至SLAM本身的位姿估計與迴環檢測中。雖然這些方法目前還沒有成為主流,但將SLAM與深度學習結合來處理影象,亦是一個很有前景的研究方向。未來的發展一定會結合語義資訊,加上場景理解,這才是人們認識世界的和理解世界的邏輯。幾何+語義似乎更加符合人類認知的特點。隨著計算能力的增強,這些資訊的新增會使得計算機更好的處理世界,就像生物的最初的條件反射一樣的系統,相信,那才是最完美的系統或者仿生系統。