
ros+科大迅飛語音包+圖靈機器人(二)在ros上使用科大迅飛
阿新 • • 發佈:2019-01-23
在工作空間catkin_ws下建立一個包
$ cd catkin_ws/src/
$ catkin_create_pkg voice_system std_msgs rospy roscpp
把科大迅飛包裡的程式碼複製到你建立的包裡,並重命名為xf_tts.cpp
- $ cd SoftWare/samples/tts_sample/
- $ cp tts_sample.c ~/catkin_ws/src/voice_system/src/
- $ cd catkin_ws/src/voice_system/src/
- $ mv tts_sample.c xf_tts.cpp
到SoftWare/include目錄下把include拷貝到voice_system包下
- $ cd SoftWare/include
- $ cp * ~/catkin_ws/src/voice_system/include
修改xf_tts.cpp檔案(注意要把appid改為自己的appid,gtts.h等路徑要改為自己該檔案的路徑)
- xf_tts.cpp的程式碼如下
/* * 語音合成(Text To Speech,TTS)技術能夠自動將任意文字實時轉換為連續的 * 自然語音,是一種能夠在任何時間、任何地點,向任何人提供語音資訊服務的 * 高效便捷手段,非常符合資訊時代海量資料、動態更新和個性化查詢的需求。 */ #include <stdlib.h> #include <stdio.h> #include <unistd.h> #include <errno.h> #include <ros/ros.h> #include <std_msgs/String.h> #include "/home/fan/SoftWare/include/qtts.h" #include "/home/fan/SoftWare/include/msp_cmn.h" #include "/home/fan/SoftWare/include/msp_errors.h" const char* fileName="/home/fan/music/voice.wav"; const char* playPath="play /home/fan/music/voice.wav"; typedef int SR_DWORD; typedef short int SR_WORD ; /* wav音訊頭部格式 */ typedef struct _wave_pcm_hdr { char riff[4]; // = "RIFF" int size_8; // = FileSize - 8 char wave[4]; // = "WAVE" char fmt[4]; // = "fmt " int fmt_size; // = 下一個結構體的大小 : 16 short int format_tag; // = PCM : 1 short int channels; // = 通道數 : 1 int samples_per_sec; // = 取樣率 : 8000 | 6000 | 11025 | 16000 int avg_bytes_per_sec; // = 每秒位元組數 : samples_per_sec * bits_per_sample / 8 short int block_align; // = 每取樣點位元組數 : wBitsPerSample / 8 short int bits_per_sample; // = 量化位元數: 8 | 16 char data[4]; // = "data"; int data_size; // = 純資料長度 : FileSize - 44 } wave_pcm_hdr; /* 預設wav音訊頭部資料 */ wave_pcm_hdr default_wav_hdr = { { 'R', 'I', 'F', 'F' }, 0, {'W', 'A', 'V', 'E'}, {'f', 'm', 't', ' '}, 16, 1, 1, 16000, 32000, 2, 16, {'d', 'a', 't', 'a'}, 0 }; /* 文字合成 */ int text_to_speech(const char* src_text, const char* des_path, const char* params) { int ret = -1; FILE* fp = NULL; const char* sessionID = NULL; unsigned int audio_len = 0; wave_pcm_hdr wav_hdr = default_wav_hdr; int synth_status = MSP_TTS_FLAG_STILL_HAVE_DATA; if (NULL == src_text || NULL == des_path) { printf("params is error!\n"); return ret; } fp = fopen(des_path, "wb"); if (NULL == fp) { printf("open %s error.\n", des_path); return ret; } /* 開始合成 */ sessionID = QTTSSessionBegin(params, &ret); if (MSP_SUCCESS != ret) { printf("QTTSSessionBegin failed, error code: %d.\n", ret); fclose(fp); return ret; } ret = QTTSTextPut(sessionID, src_text, (unsigned int)strlen(src_text), NULL); if (MSP_SUCCESS != ret) { printf("QTTSTextPut failed, error code: %d.\n",ret); QTTSSessionEnd(sessionID, "TextPutError"); fclose(fp); return ret; } printf("正在合成 ...\n"); fwrite(&wav_hdr, sizeof(wav_hdr) ,1, fp); //新增wav音訊頭,使用取樣率為16000 while (1) { /* 獲取合成音訊 */ const void* data = QTTSAudioGet(sessionID, &audio_len, &synth_status, &ret); if (MSP_SUCCESS != ret) break; if (NULL != data) { fwrite(data, audio_len, 1, fp); wav_hdr.data_size += audio_len; //計算data_size大小 } if (MSP_TTS_FLAG_DATA_END == synth_status) break; } printf("\n"); if (MSP_SUCCESS != ret) { printf("QTTSAudioGet failed, error code: %d.\n",ret); QTTSSessionEnd(sessionID, "AudioGetError"); fclose(fp); return ret; } /* 修正wav檔案頭資料的大小 */ wav_hdr.size_8 += wav_hdr.data_size + (sizeof(wav_hdr) - 8); /* 將修正過的資料寫回檔案頭部,音訊檔案為wav格式 */ fseek(fp, 4, 0); fwrite(&wav_hdr.size_8,sizeof(wav_hdr.size_8), 1, fp); //寫入size_8的值 fseek(fp, 40, 0); //將檔案指標偏移到儲存data_size值的位置 fwrite(&wav_hdr.data_size,sizeof(wav_hdr.data_size), 1, fp); //寫入data_size的值 fclose(fp); fp = NULL; /* 合成完畢 */ ret = QTTSSessionEnd(sessionID, "Normal"); if (MSP_SUCCESS != ret) { printf("QTTSSessionEnd failed, error code: %d.\n",ret); } return ret; } int makeTextToWav(const char* text, const char* filename){ int ret = MSP_SUCCESS; const char* login_params = "appid = 5b090780, work_dir = .";//登入引數,appid與msc庫繫結,請勿隨意改動 /* * rdn: 合成音訊數字發音方式 * volume: 合成音訊的音量 * pitch: 合成音訊的音調 * speed: 合成音訊對應的語速 * voice_name: 合成發音人 * sample_rate: 合成音訊取樣率 * text_encoding: 合成文字編碼格式 * */ const char* session_begin_params = "engine_type = local,voice_name=xiaofeng, text_encoding = UTF8, tts_res_path = fo|res/tts/xiaofeng.jet;fo|res/tts/common.jet, sample_rate = 16000, speed = 50, volume = 50, pitch = 50, rdn = 0"; /* 使用者登入 */ ret = MSPLogin(NULL, NULL, login_params); //第一個引數是使用者名稱,第二個引數是密碼,第三個引數是登入引數,使用者名稱和密碼可在http://www.xfyun.cn註冊獲取 if (MSP_SUCCESS != ret) { printf("MSPLogin failed, error code: %d.\n", ret); } else{ printf("開始合成 ...\n"); ret = text_to_speech(text,filename, session_begin_params); if (MSP_SUCCESS != ret) { printf("text_to_speech failed, error code: %d.\n", ret); } printf("合成完畢\n"); } MSPLogout(); return 0; } void playWav() { system(playPath); } void topicCallBack(const std_msgs::String::ConstPtr& msg) { std::cout<<"get topic text:" << msg->data.c_str(); makeTextToWav(msg->data.c_str(),fileName); playWav(); } int main(int argc, char* argv[]) { const char* start= "科大迅飛線上語音合成模組啟動"; makeTextToWav(start,fileName); playWav(); ros::init(argc,argv, "xf_tts_node"); ros::NodeHandle n; ros::Subscriber sub = n.subscribe("/voice/xf_tts_topic", 3,topicCallBack); ros::spin(); return 0; }在CMakeList檔案的“include_directories”後加入“include”,在檔案末尾加入
add_executable(xf_tts_node src/xf_tts.cpp) target_link_libraries(xf_tts_node ${catkin_LIBRARIES} -lmsc -lrt -ldl -lpthread)- CMakeList程式碼
cmake_minimum_required(VERSION 2.8.3) project(voice_system) find_package(catkin REQUIRED COMPONENTS roscpp rospy std_msgs ) include_directories( include ${catkin_INCLUDE_DIRS} ) add_executable(xf_tts_node src/xf_tts.cpp) target_link_libraries(xf_tts_node ${catkin_LIBRARIES} -lmsc -lrt -ldl -lpthread)
- 在此時到catkin_ws下進行編譯
- $ catkin_make
- 編譯完後,roscore一下,重新開啟視窗到catkin_ws下執行xf_tts_node節點
- $ cd catkin_ws
- $ rosrun voice_system xf_tts_node
- 此時,你能聽到,“科大迅飛語音模組啟動”的聲音“
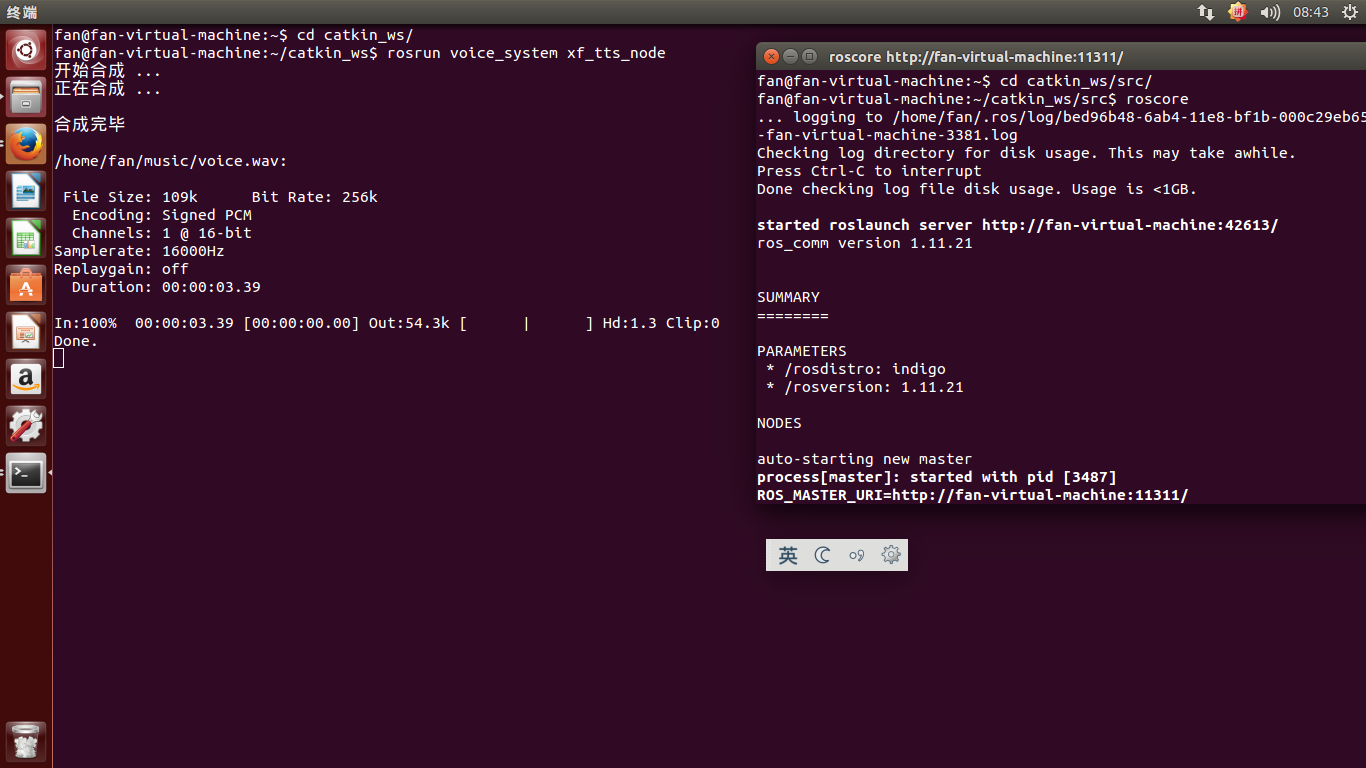
- 重新開啟一個命令視窗,在catkin_ws下發佈一個話題
- $ cd catkin_ws
- $ rostopic pub /voice/xf_tts_topic std_msgs/String 你好
- 此時,你會聽到”你好的聲音“
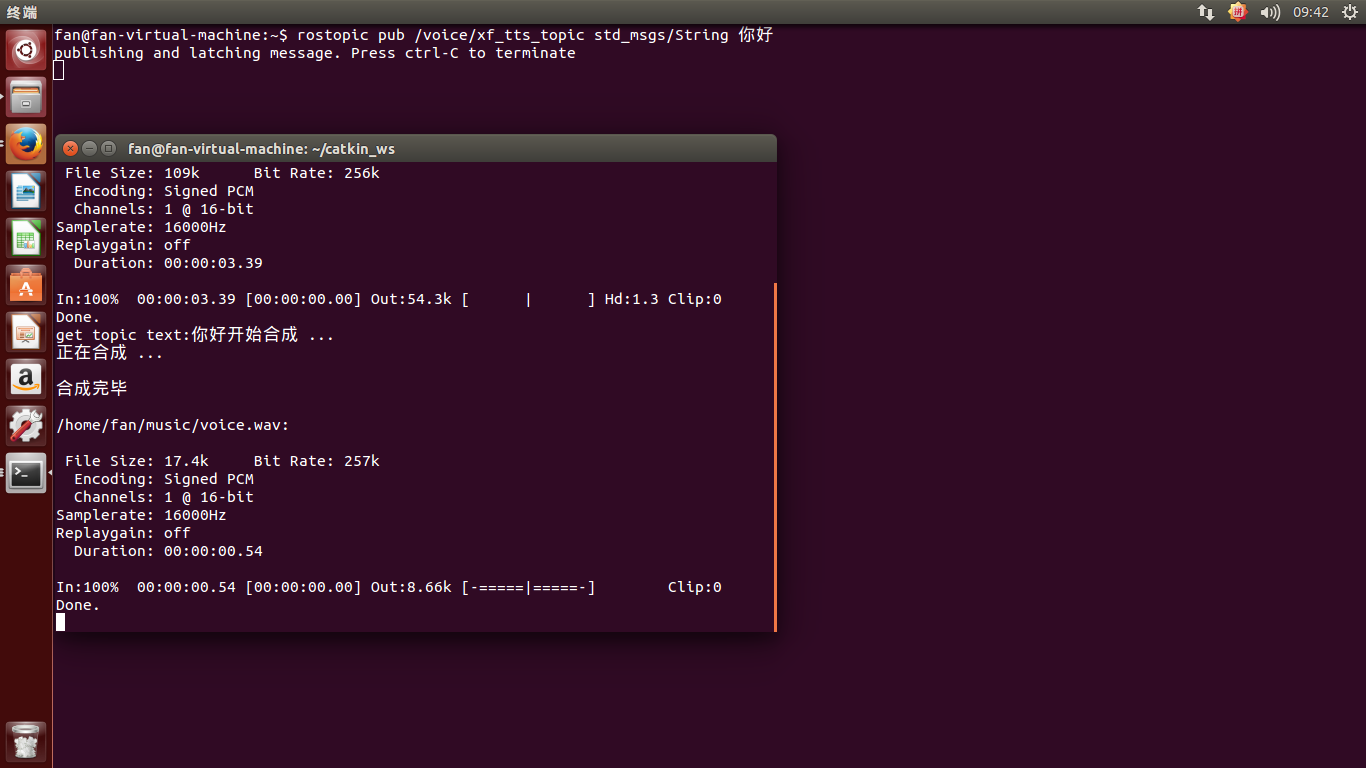
- 證明ros上執行科大迅飛語音模組成功
以下是我在實現過程中遇到的的一些錯誤
- 10102錯誤顯示如下
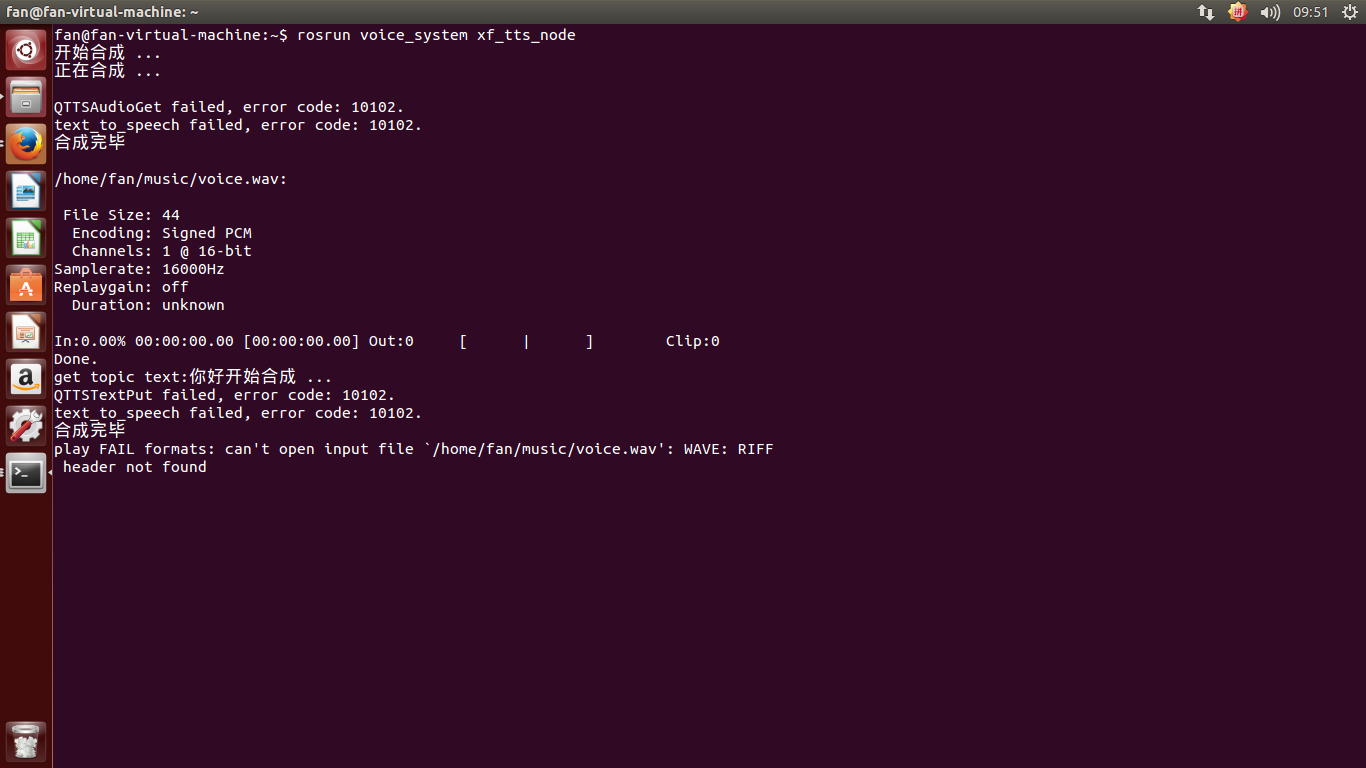
該文章主要是對自己學習的一些總結,方便以後學習,也對學習該方面的人提供一些幫助,如有問題請指出。
同時該文章也借鑑了ros小課堂的一些內容。