
行人檢測“Pedestrian detection at 100 frames per second”
文章使用的特徵是ICF,並在訓練階段進行多尺度的模型訓練,將檢測時間轉移到訓練上進行提速。
ChnFtrs檢測器
Dollar提出的ICF與DPM的效果可以媲美,ICF對濾波器響應進行簡單的矩形加和,行人檢測使用了6 quantized orientations, 1 gradient magnitude 和 3 LUV color channels,如下圖所示:
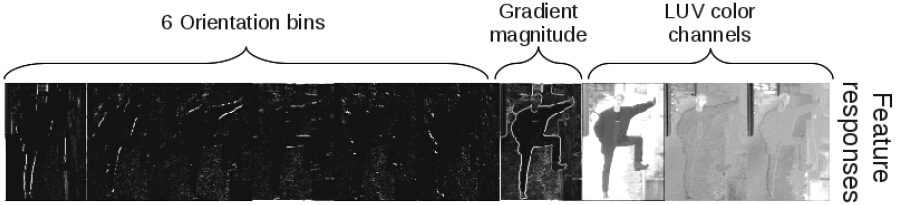
使用矩形特徵構建決策樹,之後加權成一個強分類器,決策樹及其權值使用AdaBoost學習。強分類器包含2000個弱分類器,特徵從30000個矩形特徵池中篩選,訓練開始時有5000個負樣本並bootstrap兩次,每次增加5000個困難負樣本。
ChnFtrs方法能與DPM媲美的原因:特徵是學來的。
改進的多尺度檢測方法

1.原始的目標檢測方法是對每個尺度和位置都訓練一個分類器,對於一個待檢測位置,計算每個分類器的響應,選擇相應最大的之後進行NMS,但尺度的數量通常有50個之多,訓練量很大。
2.傳統的方法是訓練一個模型,縮放N次影象進行檢測,缺點是訓練模型的尺度不好選取,且在檢測時需縮放影象多次。
3.FPDW:縮放N/K次影象,計算對應尺度的特徵,之後用這些尺度的特徵估計剩餘N-N/K個尺度的特徵。臨近尺度的響應使用下式進行擬合:
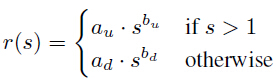
s是縮放因子(新檢測視窗的高度是老視窗高度乘以s),r(s)是特徵響應比,其餘引數均為經驗值。
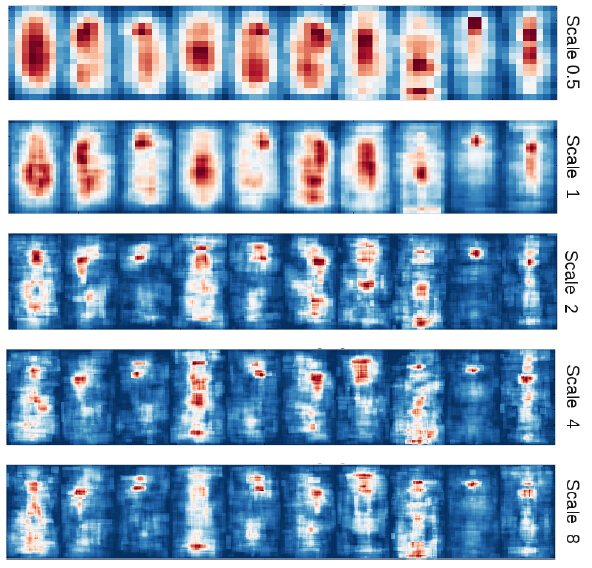
4.本文的方法VeryFast,將FPDW反過來。由於可以估計尺度間的特徵響應,可以調整stump分類器。強分類器由決策樹構建,每個決策樹包含3個stump分類器,每個stump分類器由一個通道索引,一個矩形和一個決策閾值定義。當用s縮放stump分類器時,通道索引固定,縮放矩形s倍,更新閾值t=t*r(s)。根據這個思想,可以訓練一個典型分類器,之後轉換成K個分類器,之後只需訓練N/K(~5)個分類器,測試時把N/K個分類器轉換為N個分類器,計算ICF後使用N個分類器計算響應。訓練的五個模型如下圖所示:
Soft cascade加速
AdaBoost分類器有2000個弱分類器,傳統方法每個弱分類都要通過,Dollar使用了soft cascade在檢測時進行加速,即當某級的響應低於給定閾值時停止檢測。
stixels
stixel world model”的本質是檢測出影象上的柱狀物(column,行人也算是柱狀物),並且估計出柱狀物的低端畫素(bottom pixel)和頂端畫素(top pixel),將這些畫素點標記出來就圍成了行人出現的可能區域,作者之前在《Stixels esitimation without depth information》這篇文章中就希望可以將這種思想與物體的檢測結合起來,但當時並沒有實現,作者在本文中將“stixel world model”與行人檢測完美的結合在了一起,這是其中一個貢獻。