
Storm流式計算入門
流式計算
實時獲取資料,實時資料儲存,實時資料計算,實時結果快取,持久化儲存(mysql)
代表技術:
Flume:實時獲取資料
Kafka:實時資料儲存
Storm/jstorm:實時資料計算
Redis:實時結果快取
總結:將源源不斷產生的資料實時收集並實時計算,迅速得到計算結果
關於storm
1、storm是twitter的開源流計算解決方案,因為對hadoop的mapreduce的高延遲缺點而出現
2、應用場景:
- 資訊流處理:聚合,分析
- 持續計算:如實時資料統計,監控
3、Storm的延遲性為毫秒級,而spark streaming為數十秒或分鐘,難度上storm遠大於spark
storm本質為逐行或逐批次計算,按行數處理
主要特性
- 使用場景廣泛
- 可伸縮性高:可以讓storm每秒可以處理的訊息量達到很高,擴充套件一個實時計算任務,只需要加機器並提高這個計算任務的並行度,storm使用zookeeper來協調叢集中的各種配置
- 保證無資料丟失:實時系統必須保證所有資料被成功處理,即失敗重發 異常健壯:storm叢集易於管理,輪流重啟節點不影響使用
- 容錯性好:訊息處理過程中出現異常,storm會重試 語言無關性:storm的拓撲和bolt訊息處理元件可以用任何語言來定義
storm叢集架構 ##’
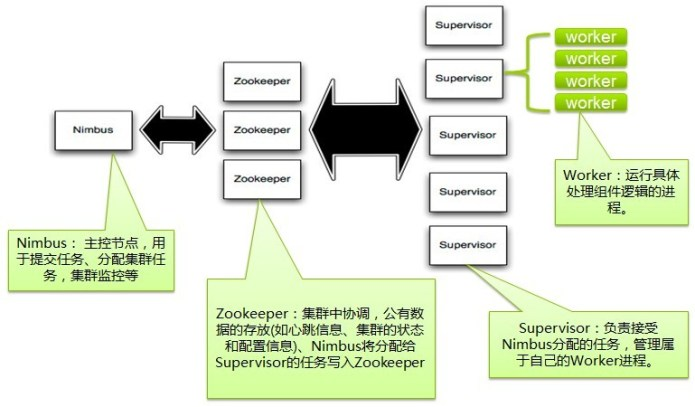
- 主節點:nimbus,工作節點:supervisor 兩者之間所有的協調工作通過zookeeper叢集
numbus程序和supervisor程序是無法直接連線的,同時他們都是無狀態的,所有的狀態維持在zookeeper中或儲存在本地磁碟上
啟動節點會從磁碟讀取到zookeeper叢集中,只要叢集是啟動的,永遠只從zookeeper拿資料,拿狀態,當關閉也會持久化到從磁碟上,這樣可以使用kill -9 numbus和supervisor程序,而不需要做備份!
- topo只能在nimbus機器上提交,將任務分配給其他節點
- supervisor監聽zookeepr叢集,根據numbus的委派在必要時啟動和關閉工作程序,每個工作程序執行topology的一個子集為程序~
- storm中資料來源為流stream的抽象,流是不間斷無界連續的tuple,storm建模事件流
工作原理
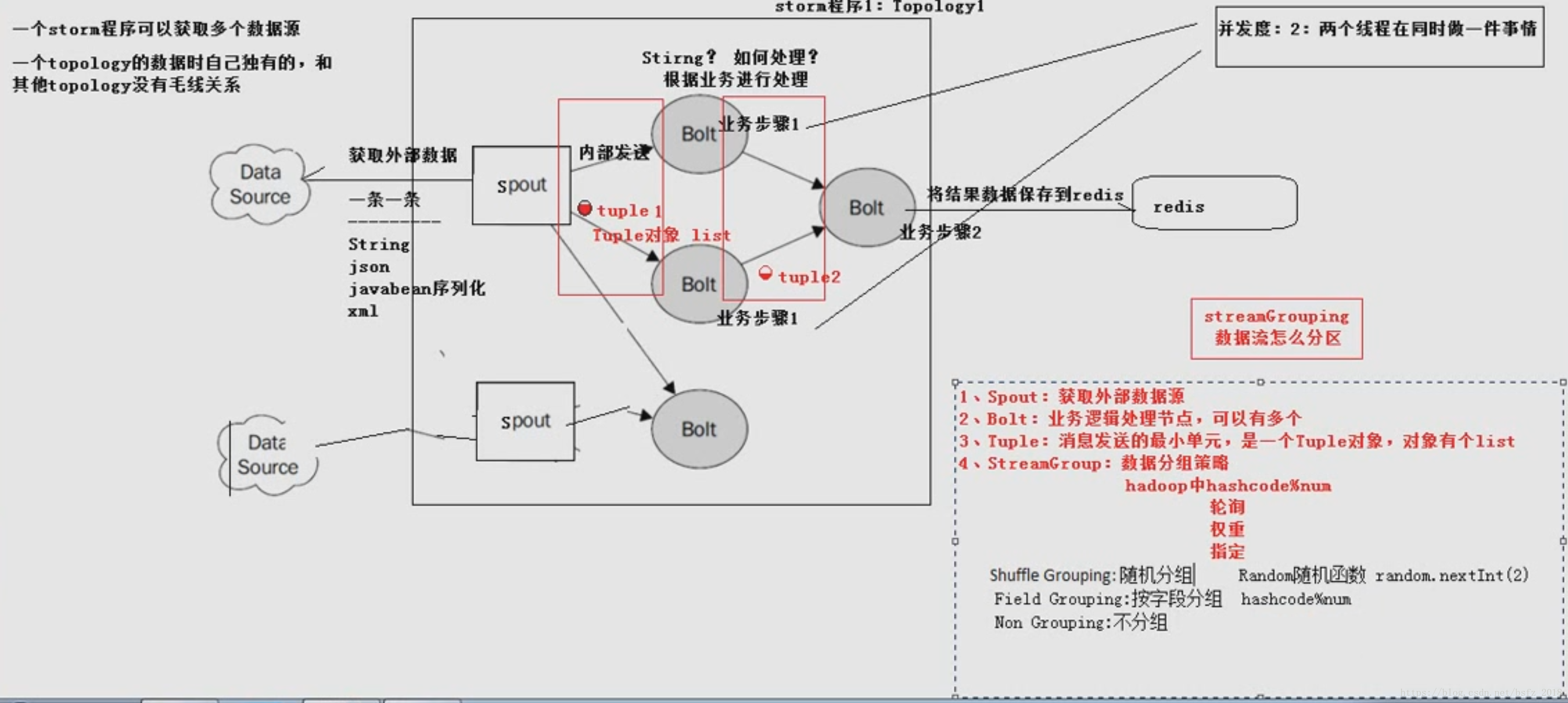
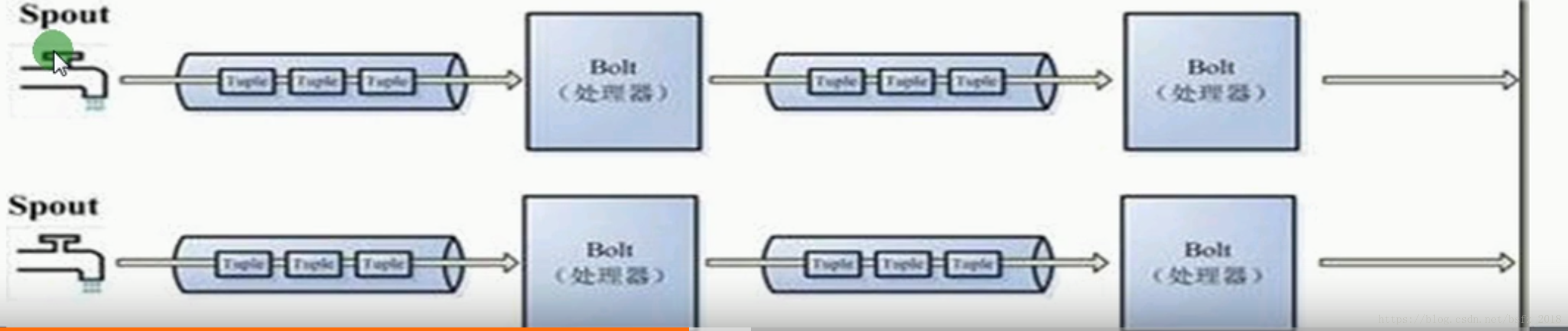
-》storm任務每個stream都有一個源頭,即spout:管口,水龍頭,即原始元祖的源頭
-》處理stream流中的tuple,這個處理器抽象為bolt(水處理器),可以消費任意數量的輸入流
它也可以傳送新的流給其他bolt使用,即只要開啟特定的spout再將spout中流出的tuple導向
特定的bolt,這個bolt對匯入的流做處理後在導向其他bolt或者目的地
-》spout為水龍頭,每個水龍頭流出水不同,我們想得到哪種水就擰開哪個水龍頭,然後使用
管道將水龍頭的水匯入到bolt,然後bolt處理器再使用管道導向另一個處理器或者存入容器
-》為了增大水處理效率,我們可以在同一個水源處接上多個水龍頭並使用多個水處理器
即拓撲toplogy結構,一個拓撲就是一個流轉換圖
-》每個同一級spout或者bolt如果拿到資料是10000行,那麼他們都是10000行,為廣播方式
-》spout到單個bolt有6種分組策略
spout通過分組策略將資料發到bolta和boltc,bolta處理完就發到boltb
-》streams:訊息流:沒有邊界的tuple序列,每個tuple可以包含多列,欄位型別可以是任意8種基本型別等
-》spout是topology訊息生產者,訊息源從訊息佇列讀取資料向topology發出tuple,訊息源spouts可以有多個
一個可靠的訊息源可以重新發射一個處理失敗的tuple,一個不可靠的訊息源spouts不會