
流式計算之Storm簡介
Storm目前存在的問題
1. 目前的開源版本中只是單節點Nimbus,掛掉只能自動重啟,可以考慮實現一個雙nimbus的佈局。
2. Clojure是一個在JVM平臺執行的動態函數語言程式設計語言,優勢在於流程計算, Storm的部分核心內容由Clojure編寫,雖然效能上提高不少但同時也提升了維護成本。
Storm架構
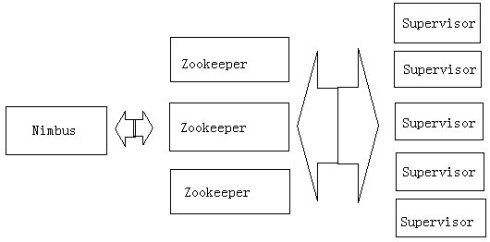
Storm叢集由一個主節點和多個工作節點組成。主節點運行了一個名為“Nimbus”的守護程序,用於分配程式碼、佈置任務及故障檢測。每個工作節點都運行了一個名為“Supervisor”的守護程序,用於監聽工作,開始並終止工作程序。Nimbus和Supervisor
Storm術語解釋
Storm的術語包括Stream、Spout、Bolt、Task、Worker、Stream Grouping和Topology。Stream是被處理的資料。Sprout是資料來源。Bolt處理資料。Task是運行於Spout或Bolt中的 執行緒。Worker
- Topologies 用於封裝一個實時計算應用程式的邏輯,類似於Hadoop的MapReduce Job。

- Stream 訊息流,是一個沒有邊界的tuple序列,這些tuples會被以一種分散式的方式並行地建立和處理
- Spouts 訊息源,是訊息生產者,他會從一個外部源讀取資料並向topology裡面發出訊息:tuple
- Bolts 訊息處理者,所有的訊息處理邏輯被封裝在bolts裡面,處理輸入的資料流併產生輸出的新資料流,可執行過濾,聚合,查詢資料庫等操作
- Task 每一個Spout和Bolt會被當作很多task在整個叢集裡面執行,每一個task對應到一個執行緒.
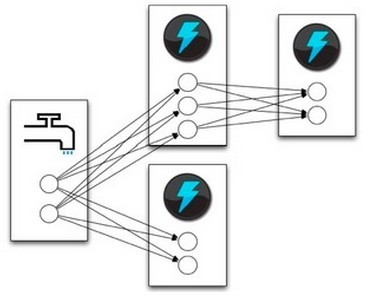
- Stream groupings 訊息分發策略,定義一個Topology的其中一步是定義每個tuple接受什麼樣的流作為輸入,stream grouping就是用來定義一個stream應該如果分配給Bolts們。
stream grouping分類
1. Shuffle Grouping: 隨機分組, 隨機派發stream裡面的tuple, 保證每個bolt接收到的tuple數目相同.
2. Fields Grouping:按欄位分組, 比如按userid來分組, 具有同樣userid的tuple會被分到相同的Bolts, 而不同的userid則會被分配到不同的Bolts.
3. All Grouping: 廣播發送, 對於每一個tuple, 所有的Bolts都會收到.
4. Global Grouping: 全域性分組,這個tuple被分配到storm中的一個bolt的其中一個task.再具體一點就是分配給id值最低的那個task.
5. Non Grouping: 不分組,意思是說stream不關心到底誰會收到它的tuple.目前他和Shuffle
grouping是一樣的效果,有點不同的是storm會把這個bolt放到這個bolt的訂閱者同一個執行緒去執行.
6. Direct Grouping: 直接分組,這是一種比較特別的分組方法,用這種分組意味著訊息的傳送者舉鼎由訊息接收者的哪個task處理這個訊息.只有被宣告為Direct
Stream的訊息流可以宣告這種分組方法.而且這種訊息tuple必須使用emitDirect方法來發射.訊息處理者可以通過TopologyContext來或者處理它的訊息的taskid
(OutputCollector.emit方法也會返回taskid)
Storm如何保證訊息被處理
storm保證每個tuple會被topology完整的執行。storm會追蹤由每個spout tuple所產生的tuple樹(一個bolt處理一個tuple之後可能會發射別的tuple從而可以形成樹狀結構), 並且跟蹤這棵tuple樹什麼時候成功處理完。每個topology都有一個訊息超時的設定, 如果storm在這個超時的時間內檢測不到某個tuple樹到底有沒有執行成功, 那麼topology會把這個tuple標記為執行失敗,並且過一會會重新發射這個tuple。
一個tuple能根據新獲取到的spout而觸發建立基於此的上千個tuple
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(1, new KestrelSpout("kestrel.backtype.com",22133,"sentence_queue",new StringScheme()));
builder.setBolt(2, new SplitSentence(), 10).shuffleGrouping(1);
builder.setBolt(3, new WordCount(), 20).fieldsGrouping(2, new Fields("word"));
這個topology從kestrel queue讀取句子,並把句子劃分成單詞,然後彙總每個單詞出現的次數,一個tuple負責讀取句子,每一個tuple分別對應計算每一個單詞出現的次數,大概樣子如下所示:
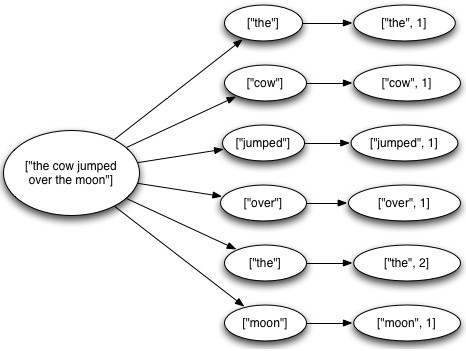
一個tuple的生命週期:
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
首先storm通過呼叫spout的nextTuple方法來獲取下一個tuple, Spout通過open方法引數裡面提供的SpoutOutputCollector來發射新tuple到它的其中一個輸出訊息流, 發射tuple的時候spout會提供一個message-id, 後面我們通過這個tuple-id來追蹤這個tuple。舉例來說, KestrelSpout從kestrel佇列裡面讀取一個訊息,並且把kestrel提供的訊息id作為message-id, 看例子:
collector.emit(new Values("field1", "field2", 3) , msgId);
接下來, 這個發射的tuple被傳送到訊息處理者bolt那裡, storm會跟蹤這個訊息的樹形結構是否建立,根據messageid呼叫Spout裡面的ack函式以確認tuple是否被完全處理。如果tuple超時就會呼叫spout的fail方法。由此看出同一個tuple不管是acked還是fail都是由建立它的那個spout發出的,所以即使spout在叢集環境中執行了很多的task,這個tule也不會被不同的task去acked或failed。
當kestrelspout從kestrel佇列中得到一個訊息後會開啟這個它,這意味著它並不會把此訊息拿走,訊息的狀態會顯示為pending,直到等待確認此訊息已經處理完成,處於pending狀態直到ack或者fail被呼叫,處於"Pending"的訊息不會再被其他佇列消費者使用.如果在這過程中spout中處理此訊息的task斷開連線或失去響應則此pending的訊息會回到"等待處理"狀態。
Storm的一些常用應用場景
1.流聚合流聚合把兩個或者多個數據流聚合成一個數據流 — 基於一些共同的tuple欄位。
builder.setBolt(5, new MyJoiner(), parallelism)
.fieldsGrouping(1, new Fields("joinfield1", "joinfield2"))
.fieldsGrouping(2, new Fields("joinfield1", "joinfield2"))
.fieldsGrouping(3, new Fields("joinfield1", "joinfield2"))
2.批處理有時候為了效能或者一些別的原因, 你可能想把一組tuple一起處理, 而不是一個個單獨處理。
3.BasicBolt
1. 讀一個輸入tuple
2. 根據這個輸入tuple發射一個或者多個tuple
3. 在execute的方法的最後ack那個輸入tuple
遵循這類模式的bolt一般是函式或者是過濾器, 這種模式太常見,storm為這類模式單獨封裝了一個介面:
IbasicBolt
4.記憶體內快取+Fields grouping組合在bolt的記憶體裡面快取一些東西非常常見。快取在和fields grouping結合起來之後就更有用了。比如,你有一個bolt把短連結變成長連結(bit.ly, t.co之類的)。你可以把短連結到長連結的對應關係利用LRU演算法快取在記憶體裡面以避免重複計算。比如元件一發射短連結,元件二把短連結轉化成長連結並快取在記憶體裡面。看一下下面兩段程式碼有什麼不一樣:
builder.setBolt(2, new ExpandUrl(), parallelism).shuffleGrouping(1);
builder.setBolt(2, new ExpandUrl(), parallelism).fieldsGrouping(1, new Fields("url"));
5.計算top N
比如你有一個bolt發射這樣的tuple: "value", "count"並且你想一個bolt基於這些資訊算出top N的tuple。最簡單的辦法是有一個bolt可以做一個全域性的grouping的動作並且在記憶體裡面保持這top N的值。這個方式對於大資料量的流顯然是沒有擴充套件性的, 因為所有的資料會被髮到同一臺機器。一個更好的方法是在多臺機器上面並行的計算這個流每一部分的top N, 然後再有一個bolt合併這些機器上面所算出來的top N以算出最後的top N, 程式碼大概是這樣的:
builder.setBolt(2, new RankObjects(), parallellism).fieldsGrouping(1, new Fields("value"));
builder.setBolt(3, new MergeObjects()).globalGrouping(2);
這個模式之所以可以成功是因為第一個bolt的fields grouping使得這種並行演算法在語義上是正確的。
用TimeCacheMap來高效地儲存一個最近被更新的物件的快取
6.用TimeCacheMap來高效地儲存一個最近被更新的物件的快取有時候你想在記憶體裡面儲存一些最近活躍的物件,以及那些不再活躍的物件。 TimeCacheMap是一個非常高效的資料結構,它提供了一些callback函式使得我們在物件不再活躍的時候我們可以做一些事情.
7.分散式RPC:CoordinatedBolt和KeyedFairBolt
用storm做分散式RPC應用的時候有兩種比較常見的模式:它們被封裝在CoordinatedBolt和KeyedFairBolt裡面.
CoordinatedBolt包裝你的bolt,並且確定什麼時候你的bolt已經接收到所有的tuple,它主要使用Direct
Stream來做這個.
KeyedFairBolt同樣包裝你的bolt並且保證你的topology同時處理多個DRPC呼叫,而不是序列地一次只執行一個。