
防止過擬合的幾種常見方法
防止過擬合的處理方法
何時會發生過擬合?
我們都知道,在進行資料探勘或者機器學習模型建立的時候,因為在統計學習中,假設資料滿足獨立同分布(i.i.d,independently and identically distributed),即當前已產生的資料可以對未來的資料進行推測與模擬,因此都是使用歷史資料建立模型,即使用已經產生的資料去訓練,然後使用該模型去擬合未來的資料。但是一般獨立同分布的假設往往不成立,即資料的分佈可能會發生變化(distribution drift),並且可能當前的資料量過少,不足以對整個資料集進行分佈估計,因此往往需要防止模型過擬合,提高模型泛化能力。而為了達到該目的的最常見方法便是:正則化,即在對模型的目標函式(objective function)或代價函式(cost function)加上正則項。
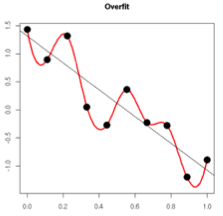
在對模型進行訓練時,有可能遇到訓練資料不夠,即訓練資料無法對整個資料的分佈進行估計的時候,或者在對模型進行過度訓練(overtraining)時,常常會導致模型的過擬合(overfitting)。如下圖所示:
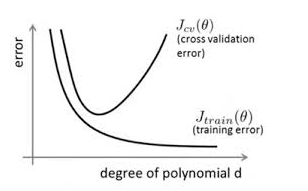
通過上圖可以看出,隨著模型訓練的進行,模型的複雜度會增加,此時模型在訓練資料集上的訓練誤差會逐漸減小,但是在模型的複雜度達到一定程度時,模型在驗證集上的誤差反而隨著模型的複雜度增加而增大。此時便發生了過擬合,即模型的複雜度升高,但是該模型在除訓練集之外的資料集上卻不work。
為了防止過擬合,我們需要用到一些方法,如:early stopping、資料增強(Data augmentation)、正則化(Regularization)、Dropout等。
Early stopping
對模型進行訓練的過程即是對模型的引數進行學習更新的過程,這個引數學習的過程往往會用到一些迭代方法,如梯度下降(Gradient descent)學習演算法。Early stopping便是一種迭代次數(epochs)截斷的方法來防止過擬合,即在模型對訓練資料集迭代收斂之前停止迭代來防止過擬合。
Early stopping方法的具體做法是,在每一個Epoch結束時(一個Epoch集為對所有的訓練資料的一輪遍歷)計算validation data的accuracy,當accuracy不再提高時,就停止訓練。這種做法很符合直觀感受,因為accurary都不再提高了,在繼續訓練也是無益的,只會提高訓練的時間。那麼該做法的一個重點便是怎樣才認為validation accurary不再提高了呢?並不是說validation accuracy一降下來便認為不再提高了,因為可能經過這個Epoch後,accuracy降低了,但是隨後的Epoch又讓accuracy又上去了,所以不能根據一兩次的連續降低就判斷不再提高。一般的做法是,在訓練的過程中,記錄到目前為止最好的validation accuracy,當連續10次Epoch(或者更多次)沒達到最佳accuracy時,則可以認為accuracy不再提高了。此時便可以停止迭代了(Early Stopping)。這種策略也稱為“No-improvement-in-n”,n即Epoch的次數,可以根據實際情況取,如10、20、30……
資料集擴增
在資料探勘領域流行著這樣的一句話,“有時候往往擁有更多的資料勝過一個好的模型”。因為我們在使用訓練資料訓練模型,通過這個模型對將來的資料進行擬合,而在這之間又一個假設便是,訓練資料與將來的資料是獨立同分布的。即使用當前的訓練資料來對將來的資料進行估計與模擬,而更多的資料往往估計與模擬地更準確。因此,更多的資料有時候更優秀。但是往往條件有限,如人力物力財力的不足,而不能收集到更多的資料,如在進行分類的任務中,需要對資料進行打標,並且很多情況下都是人工得進行打標,因此一旦需要打標的資料量過多,就會導致效率低下以及可能出錯的情況。所以,往往在這時候,需要採取一些計算的方式與策略在已有的資料集上進行手腳,以得到更多的資料。
通俗得講,資料機擴增即需要得到更多的符合要求的資料,即和已有的資料是獨立同分布的,或者近似獨立同分布的。
一般有以下方法:
從資料來源採集更多資料
複製原有資料並加上隨機噪聲
重取樣
根據當前資料集估計資料分佈引數,使用該分佈產生更多資料等
正則化方法
正則化方法是指在進行目標函式或代價函式優化時,在目標函式或代價函式後面加上一個正則項,一般有L1正則與L2正則等。
L1正則
L1正則是基於L1範數,即在目標函式後面加上引數的L1範數和項,即引數絕對值和與引數的積項,即:
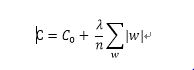
其中C0代表原始的代價函式,n是樣本的個數,λ就是正則項係數,權衡正則項與C0項的比重。後面那一項即為L1正則項。 在計算梯度時,w的梯度變為:
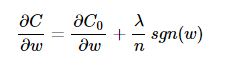
其中,sgn是符號函式,那麼便使用下式對引數進行更新:
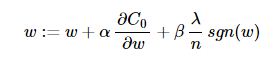
對於有些模型,如線性迴歸中(L1正則線性迴歸即為Lasso迴歸),常數項b的更新方程不包括正則項,即:
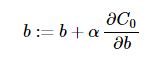
其中,梯度下降演算法中,α<0,β<0,而在梯度上升演算法中則相反。
從上式可以看出,當w為正時,更新後w會變小;當w為負時,更新後w會變大;因此L1正則項是為了使得那些原先處於零(即|w|≈0)附近的引數w往零移動,使得部分引數為零,從而降低模型的複雜度(模型的複雜度由引數決定),從而防止過擬合,提高模型的泛化能力。
其中,L1正則中有個問題,便是L1範數在0處不可導,即|w|在0處不可導,因此在w為0時,使用原來的未經正則化的更新方程來對w進行更新,即令sgn(0)=0,這樣即:
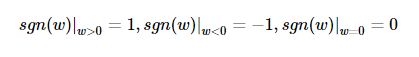
L2正則
L2正則是基於L2範數,即在目標函式後面加上引數的L2範數和項,即引數的平方和與引數的積項,即:
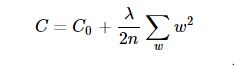
其中C0代表原始的代價函式,n是樣本的個數,與L1正則化項前面的引數不同的是,L2項的引數乘了12,是為了便於計算以及公式的美感性,因為平方項求導有個2,λ就是正則項係數,權衡正則項與C0項的比重。後面那一項即為L2正則項。
L2正則化中則使用下式對模型引數進行更新:
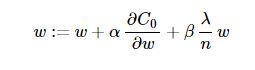
對於有些模型,如線性迴歸中(L2正則線性迴歸即為Ridge迴歸,嶺迴歸),常數項b的更新方程不包括正則項,即:
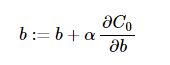
其中,梯度下降演算法中,α<0,β<0,而在梯度上升演算法中則相反。
從上式可以看出,L2正則項起到使得引數w變小加劇的效果,但是為什麼可以防止過擬合呢?一個通俗的理解便是:更小的引數值w意味著模型的複雜度更低,對訓練資料的擬合剛剛好(奧卡姆剃刀),不會過分擬合訓練資料,從而使得不會過擬合,以提高模型的泛化能力。
在這裡需要提到的是,在對模型引數進行更新學習的時候,有兩種更新方式,mini-batch (部分增量更新)與 full-batch(全增量更新),即在每一次更新學習的過程中(一次迭代,即一次epoch),在mini-batch中進行分批處理,先使用一部分樣本進行更新,然後再使用一部分樣本進行更新。直到所有樣本都使用了,這次epoch的損失函式值則為所有mini batch的平均損失值。設每次mini batch中樣本個數為m,那麼引數的更新方程中的正則項要改成:
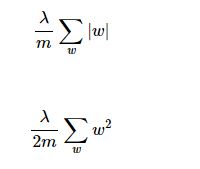
而full-batch即每一次epoch中,使用全部的訓練樣本進行更新,那麼每次的損失函式值即為全部樣本的誤差之和。更新方程不變。
總結
正則項是為了降低模型的複雜度,從而避免模型區過分擬合訓練資料,包括噪聲與異常點(outliers)。從另一個角度上來講,正則化即是假設模型引數服從先驗概率,即為模型引數新增先驗,只是不同的正則化方式的先驗分佈是不一樣的。這樣就規定了引數的分佈,使得模型的複雜度降低(試想一下,限定條件多了,是不是模型的複雜度降低了呢),這樣模型對於噪聲與異常點的抗干擾性的能力增強,從而提高模型的泛化能力。還有個解釋便是,從貝葉斯學派來看:加了先驗,在資料少的時候,先驗知識可以防止過擬合;從頻率學派來看:正則項限定了引數的取值,從而提高了模型的穩定性,而穩定性強的模型不會過擬合,即控制模型空間。
另外一個解釋,規則化項的引入,在訓練(最小化cost)的過程中,當某一維的特徵所對應的權重過大時,而此時模型的預測和真實資料之間距離很小,通過規則化項就可以使整體的cost取較大的值,從而,在訓練的過程中避免了去選擇那些某一維(或幾維)特徵的權重過大的情況,即過分依賴某一維(或幾維)的特徵(引用知乎)。
L2與L1的區別在於,L1正則是拉普拉斯先驗,而L2正則則是高斯先驗。它們都是服從均值為0,協方差為1λ。當λ=0時,即沒有先驗)沒有正則項,則相當於先驗分佈具有無窮大的協方差,那麼這個先驗約束則會非常弱,模型為了擬合所有的訓練集資料, 引數w可以變得任意大從而使得模型不穩定,即方差大而偏差小。λ越大,標明先驗分佈協方差越小,偏差越大,模型越穩定。即,加入正則項是在偏差bias與方差variance之間做平衡tradeoff(來自知乎)。下圖即為L2與L1正則的區別:
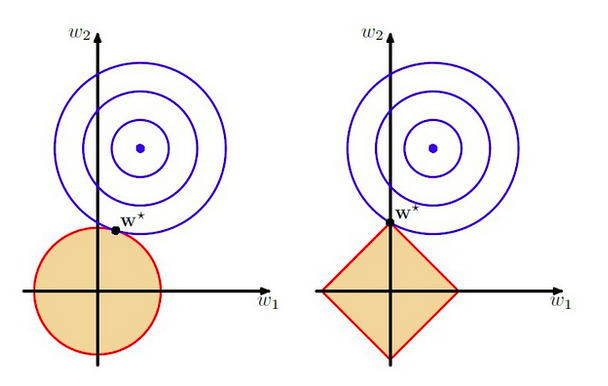
上圖中的模型是線性迴歸,有兩個特徵,要優化的引數分別是w1和w2,左圖的正則化是L2,右圖是L1。藍色線就是優化過程中遇到的等高線,一圈代表一個目標函式值,圓心就是樣本觀測值(假設一個樣本),半徑就是誤差值,受限條件就是紅色邊界(就是正則化那部分),二者相交處,才是最優引數。可見右邊的最優引數只可能在座標軸上,所以就會出現0權重引數,使得模型稀疏。
其實拉普拉斯分佈與高斯分佈是數學家從實驗中誤差服從什麼分佈研究中得來的。一般直觀上的認識是服從應該服從均值為0的對稱分佈,並且誤差大的頻率低,誤差小的頻率高,因此拉普拉斯使用拉普拉斯分佈對誤差的分佈進行擬合,如下圖:
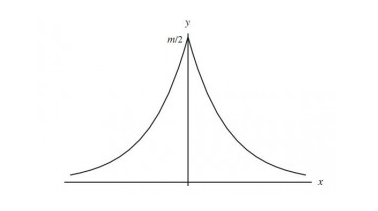
而拉普拉斯在最高點,即自變數為0處不可導,因為不便於計算,於是高斯在這基礎上使用高斯分佈對其進行擬合,如下圖:
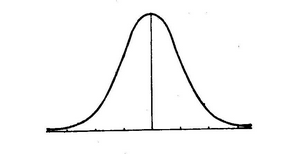
Dropout
正則是通過在代價函式後面加上正則項來防止模型過擬合的。而在神經網路中,有一種方法是通過修改神經網路本身結構來實現的,其名為Dropout。該方法是在對網路進行訓練時用一種技巧(trick),對於如下所示的三層人工神經網路:
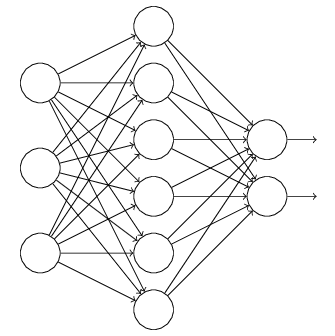
對於上圖所示的網路,在訓練開始時,隨機得刪除一些(可以設定為一半,也可以為1/3,1/4等)隱藏層神經元,即認為這些神經元不存在,同時保持輸入層與輸出層神經元的個數不變,這樣便得到如下的ANN:
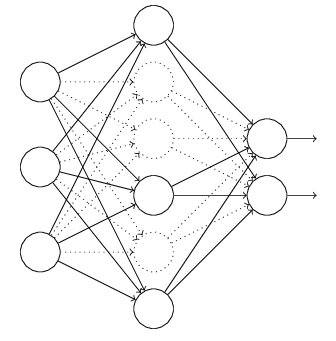
然後按照BP學習演算法對ANN中的引數進行學習更新(虛線連線的單元不更新,因為認為這些神經元被臨時刪除了)。這樣一次迭代更新便完成了。下一次迭代中,同樣隨機刪除一些神經元,與上次不一樣,做隨機選擇。這樣一直進行瑕疵,直至訓練結束。
Dropout方法是通過修改ANN中隱藏層的神經元個數來防止ANN的過擬合。