
深度學習中過擬合與防止過擬合的方法
1.什麼是過擬合?
過擬合(overfitting)是指在模型引數擬合過程中的問題,由於訓練資料包含抽樣誤差,訓練時,複雜的模型將抽樣誤差也考慮在內,將抽樣誤差也進行了很好的擬合。
具體表現就是最終模型在訓練集上效果好;在測試集上效果差。模型泛化能力弱。
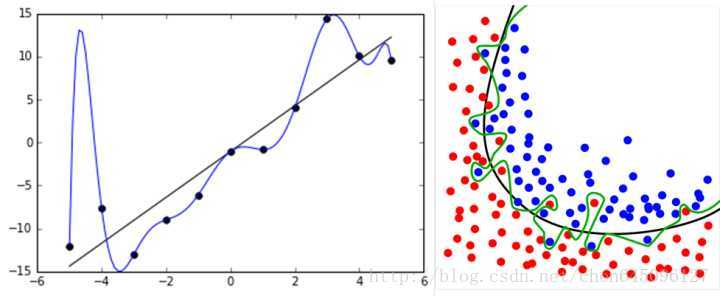
2.過擬合產生的原因?
(1)在對模型進行訓練時,有可能遇到訓練資料不夠,即訓練資料無法對整個資料的分佈進行估計的時候
(2)權值學習迭代次數足夠多(Overtraining),擬合了訓練資料中的噪聲和訓練樣例中沒有代表性的特徵.
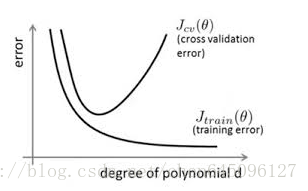
通過上圖可以看出,隨著模型訓練的進行,模型的複雜度會增加,此時模型在訓練資料集上的訓練誤差會逐漸減小,但是在模型的複雜度達到一定程度時,模型在驗證集上的誤差反而隨著模型的複雜度增加而增大。此時便發生了過擬合,即模型的複雜度升高,但是該模型在除訓練集之外的資料集上卻不work。
3.如何解決過擬合問題?
(1)Early stopping:
對模型進行訓練的過程即是對模型的引數進行學習更新的過程,這個引數學習的過程往往會用到一些迭代方法,如梯度下降(Gradient descent)學習演算法。Early stopping便是一種迭代次數截斷的方法來防止過擬合的方法,即在模型對訓練資料集迭代收斂之前停止迭代來防止過擬合。
Early stopping方法的具體做法是,在每一個Epoch結束時(一個Epoch集為對所有的訓練資料的一輪遍歷)計算validation data的accuracy,當accuracy不再提高時,就停止訓練。這種做法很符合直觀感受,因為accurary都不再提高了,在繼續訓練也是無益的,只會提高訓練的時間。那麼該做法的一個重點便是怎樣才認為validation accurary不再提高了呢?並不是說validation
accuracy一降下來便認為不再提高了,因為可能經過這個Epoch後,accuracy降低了,但是隨後的Epoch又讓accuracy又上去了,所以不能根據一兩次的連續降低就判斷不再提高。一般的做法是,在訓練的過程中,記錄到目前為止最好的validation accuracy,當連續10次Epoch(或者更多次)沒達到最佳accuracy時,則可以認為accuracy不再提高了。此時便可以停止迭代了(Early Stopping)。這種策略也稱為“No-improvement-in-n”,n即Epoch的次數,可以根據實際情況取,如10、20、30……
(2)資料集擴增:
這是解決過擬合最有效的方法,只要給足夠多的資料,讓模型「看見」儘可能多的「例外情況」,它就會不斷修正自己,從而得到更好的結果:
如何獲取更多資料,可以有以下幾個方法:
- 從資料來源頭獲取更多資料:這個是容易想到的,例如物體分類,我就再多拍幾張照片好了;但是,在很多情況下,大幅增加資料本身就不容易;另外,我們不清楚獲取多少資料才算夠;
- 根據當前資料集估計資料分佈引數,使用該分佈產生更多資料:這個一般不用,因為估計分佈引數的過程也會代入抽樣誤差。
- 資料增強(Data Augmentation):通過一定規則擴充資料。如在物體分類問題裡,物體在影象中的位置、姿態、尺度,整體圖片明暗度等都不會影響分類結果。我們就可以通過影象平移、翻轉、縮放、切割等手段將資料庫成倍擴充;
原理同上,但是這類方法直接將權值的大小加入到 Cost 裡,在訓練的時候限制權值變大。以 L2 regularization為例:
訓練過程需要降低整體的 Cost,這時候,一方面能降低實際輸出與樣本之間的誤差
,也能降低權值大小。
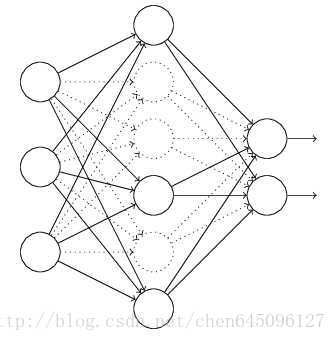
在訓練時,每次隨機(如50%概率)忽略隱層的某些節點;這樣,我們相當於隨機從2^H個模型中取樣選擇模型;同時,由於每個網路只見過一個訓練資料(每次都是隨機的新網路),所以類似 bagging 的做法,這就是我為什麼將它分類到「結合多種模型」中;
此外,而不同模型之間權值共享(共同使用這 H 個神經元的連線權值),相當於一種權值正則方法,實際效果比 L2 regularization 更好。
參考資料: https://www.zhihu.com/search?type=content&q=%E8%BF%87%E6%8B%9F%E5%90%88
http://blog.csdn.net/heyongluoyao8/article/details/49429629
http://blog.sina.com.cn/s/blog_64b046c70101f09r.html