
HashMap,HashSet,HashTable,LinkedHashMap,LinkedHashSet,ArrayList,LinkedList,ConcurrentHashMap,Vector
HashMap相關問題
1、你用過HashMap嗎?什麼是HashMap?你為什麼用到它?
用過,HashMap是基於雜湊表的Map介面的非同步實現,它允許null鍵和null值,且HashMap依託於它的資料結構的設計,儲存效率特別高,這是我用它的原因
2、你知道HashMap的工作原理嗎?你知道HashMap的get()方法的工作原理嗎?
上面兩個問題屬於同一答案的問題
HashMap是基於hash演算法實現的,通過put(key,value)儲存物件到HashMap中,也可以通過get(key)從HashMap中獲取物件。當我們使用put的時候,首先HashMap會對key的hashCode()的值進行hash計算,根據hash值得到這個元素在陣列中的位置,將元素儲存在該位置的連結串列上。當我們使用get的時候,首先HashMap會對key的hashCode()的值進行hash計算,根據hash值得到這個元素在陣列中的位置,將元素從該位置上的連結串列中取出
3、當兩個物件的hashcode相同會發生什麼?
hashcode相同,說明兩個物件HashMap陣列的同一位置上,接著HashMap會遍歷連結串列中的每個元素,通過key的equals方法來判斷是否為同一個key,如果是同一個key,則新的value會覆蓋舊的value,並且返回舊的value。如果不是同一個key,則儲存在該位置上的連結串列的鏈頭
4、如果兩個鍵的hashcode相同,你如何獲取值物件?
遍歷HashMap連結串列中的每個元素,並對每個key進行hash計算,最後通過get方法獲取其對應的值物件
5、如果HashMap的大小超過了負載因子(load factor)定義的容量,怎麼辦?
負載因子預設是0.75,HashMap超過了負載因子定義的容量,也就是說超過了(HashMap的大小*負載因子)這個值,那麼HashMap將會建立為原來HashMap大小兩倍的陣列大小,作為自己新的容量,這個過程叫resize或者rehash
6、你瞭解重新調整HashMap大小存在什麼問題嗎?
當多執行緒的情況下,可能產生條件競爭。當重新調整HashMap大小的時候,確實存在條件競爭,如果兩個執行緒都發現HashMap需要重新調整大小了,它們會同時試著調整大小。在調整大小的過程中,儲存在連結串列中的元素的次序會反過來,因為移動到新的陣列位置的時候,HashMap並不會將元素放在LinkedList的尾部,而是放在頭部,這是為了避免尾部遍歷(tail traversing)。如果條件競爭發生了,那麼就死迴圈了
7、我們可以使用自定義的物件作為鍵嗎?
可以,只要它遵守了equals()和hashCode()方法的定義規則,並且當物件插入到Map中之後將不會再改變了。如果這個自定義物件時不可變的,那麼它已經滿足了作為鍵的條件,因為當它建立之後就已經不能改變了。
HashSet與HashMap區別
HashMap實現了Map介面
HashSet實現了Set介面HashMap儲存鍵值對
HashSet僅僅儲存物件HashMap使用put()方法將元素放入map中
HashSet使用add()方法將元素放入set中HashMap中使用鍵物件來計算hashcode值
HashSet使用成員物件來計算hashcode值HashMap比較快,因為是使用唯一的鍵來獲取物件
HashSet較HashMap來說比較慢
HashTable與HashMap的區別
Hashtable方法是同步的
HashMap方法是非同步的Hashtable基於Dictionary類
HashMap基於AbstractMap,而AbstractMap基於Map介面的實現Hashtable中key和value都不允許為null,遇到null,直接返回 NullPointerException
HashMap中key和value都允許為null,遇到key為null的時候,呼叫putForNullKey方法進行處理,而對value沒有處理Hashtable中hash陣列預設大小是11,擴充方式是old*2+1
HashMap中hash陣列的預設大小是16,而且一定是2的指數
LinkedHashMap的有序性
LinkedHashMap底層使用雜湊表與雙向連結串列來儲存所有元素,它維護著一個運行於所有條目的雙向連結串列(如果學過雙向連結串列的同學會更好的理解它的原始碼),此連結串列定義了迭代順序,該迭代順序可以是插入順序或者是訪問順序
1.按插入順序的連結串列:在LinkedHashMap呼叫get方法後,輸出的順序和輸入時的相同,這就是按插入順序的連結串列,預設是按插入順序排序2.按訪問順序的連結串列:在LinkedHashMap呼叫get方法後,會將這次訪問的元素移至連結串列尾部,不斷訪問可以形成按訪問順序排序的連結串列。簡單的說,按最近最少訪問的元素進行排序(類似LRU演算法)
我們可以通過例子來理解我們上面所說的LinkedHashMap的插入順序和訪問順序
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("apple", "蘋果");
map.put("watermelon", "西瓜");
map.put("banana", "香蕉");
map.put("peach", "桃子");
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}上面是簡單的HashMap程式碼,通過控制檯的輸出,我們可以看到HashMap是沒有順序的
banana=香蕉
apple=蘋果
peach=桃子
watermelon=西瓜
我們現在將HashMap換成LinkedHashMap,其他程式碼不變
Map<String, String> map = new LinkedHashMap<String, String>();看一下控制檯的輸出
apple=蘋果
watermelon=西瓜
banana=香蕉
peach=桃子
我們可以看到,其輸出順序是完成按照插入順序的,也就是我們上面所說的保留了插入的順序。下面我們修改一下程式碼,通過訪問順序進行排序
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<String, String>(16,0.75f,true);
map.put("apple", "蘋果");
map.put("watermelon", "西瓜");
map.put("banana", "香蕉");
map.put("peach", "桃子");
map.get("banana");
map.get("apple");
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}程式碼與之前的相比
1.替換了LinkedHashMap的建構函式,使用三個引數的建構函式,第三個引數傳進true就是表明用訪問順序來排序,預設是false(即插入順序)
2.增加了兩句LinkedHashMap的get方法,來表示最近已經訪問過這兩個元素了
//修改的程式碼
Map<String, String> map = new LinkedHashMap<String, String>(16,0.75f,true);
......
map.get("banana");
map.get("apple");看一下控制檯的輸出結果
watermelon=西瓜
peach=桃子
banana=香蕉
apple=蘋果我們可以看到,順序是先從最少訪問的元素開始遍歷(西瓜、桃子),而香蕉、蘋果是因為分別呼叫了get方法,香蕉是最先訪問的,所以它的比蘋果更少用一些。這也就是我們之前提到過的,LinkedHashMap可以選擇按照訪問順序進行排序
LinkedHashMap與HashMap的區別
LinkedHashMap有序的,有插入順序和訪問順序
HashMap無序的LinkedHashMap內部維護著一個運行於所有條目的雙向連結串列
HashMap內部維護著一個單鏈表
什麼是ArrayList
ArrayList可以理解為動態陣列,它的容量能動態增長,該容量是指用來儲存列表元素的陣列的大小,隨著向ArrayList中不斷新增元素,其容量也自動增長
ArrayList允許包括null在內的所有元素
ArrayList是List介面的非同步實現
ArrayList是有序的
定義如下:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
}ArrayList實現了List介面、底層使用陣列儲存所有元素,其操作基 本上是對陣列的操作
ArrayList繼承了AbstractList抽象類,它是一個數組佇列,提供了相關的新增、刪除、修改、遍歷等功能
ArrayList實現了RandmoAccess介面,即提供了隨機訪問功能,RandmoAccess是java中用來被List實現,為List提供快速訪問功能的,我們可以通過元素的序號快速獲取元素物件,這就是快速隨機訪問
ArrayList實現了Cloneable介面,即覆蓋了函式clone(),能被克隆
ArrayList實現了java.io.Serializable介面,意味著ArrayList支援序列化
什麼是LinkedList
LinkedList基於連結串列的List介面的非同步實現
LinkedList允許包括null在內的所有元素
LinkedList是有序的
LinkedList是fail-fast的
LinkedList與ArrayList的區別
LinkedList底層是雙向連結串列
ArrayList底層是可變陣列LinkedList不允許隨機訪問,即查詢效率低
ArrayList允許隨機訪問,即查詢效率高LinkedList插入和刪除效率快
ArrayList插入和刪除效率低
解釋一下:
對於隨機訪問的兩個方法,get和set,ArrayList優於LinkedList,因為LinkedList要移動指標
對於新增和刪除兩個方法,add和remove,LinedList比較佔優勢,因為ArrayList要移動資料
什麼是ConcurrentHashMap
ConcurrentHashMap基於雙陣列和連結串列的Map介面的同步實現
ConcurrentHashMap中元素的key是唯一的、value值可重複
ConcurrentHashMap不允許使用null值和null鍵
ConcurrentHashMap是無序的
為什麼使用ConcurrentHashMap
我們都知道HashMap是非執行緒安全的,當我們只有一個執行緒在使用HashMap的時候,自然不會有問題,但如果涉及到多個執行緒,並且有讀有寫的過程中,HashMap就會fail-fast。要解決HashMap同步的問題,我們的解決方案有
Hashtable
Collections.synchronizedMap(hashMap)
這兩種方式基本都是對整個hash表結構加上同步鎖,這樣在鎖表的期間,別的執行緒就需要等待了,無疑效能不高,所以我們引入ConcurrentHashMap,既能同步又能多執行緒訪問
ConcurrentHashMap的資料結構
ConcurrentHashMap的資料結構為一個Segment陣列,Segment的資料結構為HashEntry的陣列,而HashEntry存的是我們的鍵值對,可以構成連結串列。可以簡單的理解為數組裡裝的是HashMap
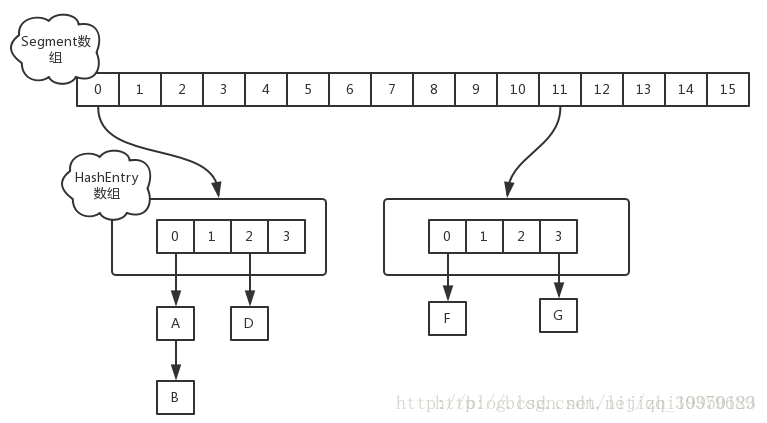
從上面的結構我們可以瞭解到,ConcurrentHashMap定位一個元素的過程需要進行兩次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的連結串列的頭部,因此,這一種結構的帶來的副作用是Hash的過程要比普通的HashMap要長,但是帶來的好處是寫操作的時候可以只對元素所在的Segment進行加鎖即可,不會影響到其他的Segment。正是因為其內部的結構以及機制,ConcurrentHashMap在併發訪問的效能上要比Hashtable和同步包裝之後的HashMap的效能提高很多。在理想狀態下,ConcurrentHashMap 可以支援 16 個執行緒執行併發寫操作(如果併發級別設定為 16),及任意數量執行緒的讀操作
什麼是Vector
Vector是基於可變陣列的List介面的同步實現
Vector是有序的
Vector允許null鍵和null值
Vector已經不建議使用了
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
Vector實現了List介面、底層使用陣列儲存所有元素,其操作基本上是對陣列的操作
Vector繼承了AbstractList抽象類,它是一個數組佇列,提供了相關的新增、刪除、修改、遍歷等功能
Vector實現了RandmoAccess介面,即提供了隨機訪問功能,RandmoAccess是java中用來被List實現,為List提供快速訪問功能的,我們可以通過元素的序號快速獲取元素物件,這就是快速隨機訪問
Vector實現了Cloneable介面,即覆蓋了函式clone(),能被克隆
Vector實現了java.io.Serializable介面,意味著ArrayList支援序列化
Vector和ArrayList的區別
Vector同步、執行緒安全的
ArrayList非同步、執行緒不安全Vector 需要額外開銷來維持同步鎖,效能慢
ArrayList 效能快Vector 可以使用Iterator、foreach、Enumeration輸出
ArrayList 只能使用Iterator、foreach輸出