
HashMap 、Hashtable、TreeMap、LinkedHashMap、ConcurrentHashMap 、WeakHashMap
Map是用來儲存鍵值對的資料結構,鍵值對在陣列中通過陣列下標來對其內容索引的,而鍵值對在Map中,則是通過物件來進行索引,用來索引的物件叫做key,其對應的物件叫value。
Map與Collection在集合框架中屬並列存在
Map是一次新增一對元素(儲存的是夫妻,哈哈)。Collection是一次新增一個元素(儲存的是光棍,哈哈)。
Map儲存的是鍵值對。
Map儲存元素使用put方法, Collection使用add方法。
Map集合沒有直接取出元素的方法, 而是先轉成Set集合, 再通過迭代獲取元素。
Map集合中鍵要保證唯一性。
Map的兩種取值方式keySet、entrySet
keySet
先獲取所有鍵的集合, 再根據鍵獲取對應的值。(即先找到丈夫,去找妻子)
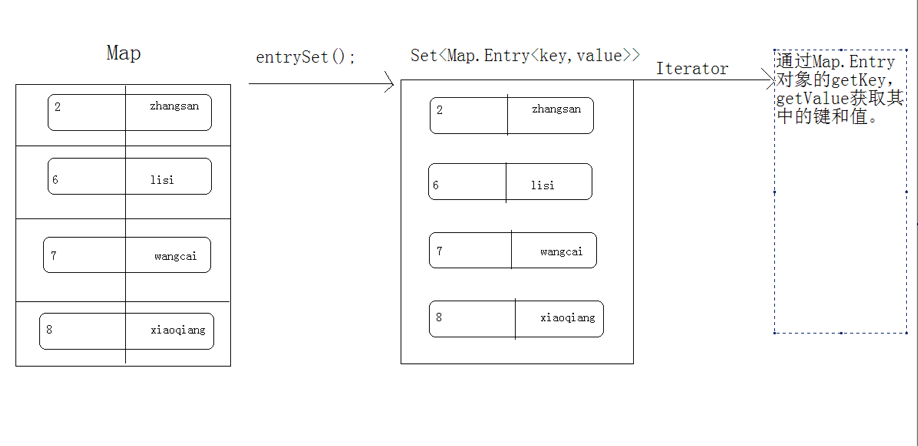
entrySet
先獲取map中的鍵值關係封裝成一個個的entry物件, 儲存到一個Set集合中,再迭代這個Set集合, 根據entry獲取對應的key和value。
向集合中儲存自定義物件 (entry類似於是結婚證)
HashMap : 內部結構是雜湊表,不是同步的。允許null作為鍵,null作為值。
TreeMap : 內部結構是二叉樹,不是同步的。可以對Map集合中的鍵進行排序。
keySet的演示圖解:

entrySet的演示圖解:
HashMap概述
HashMap是基於雜湊表的Map介面的非同步實現,此實現提供所有可選的對映操作,並允許使用null值和null鍵
它不保證對映的順序,HashMap是Hashtable的輕量級實現(非執行緒安全的實現),它們都完成了Map介面。
HashMap的資料結構
雜湊表是由陣列+連結串列組成的,(注意,這是jdk1.8之前的)陣列的預設長度為16。
為什麼是陣列+連結串列?
陣列對於資料的訪問如查詢和讀取非常方便,連結串列對於資料插入非常方便。
連結串列可以解決hash值衝突(即對於不同的key值可能會得到相同的hash值)
數組裡每個元素儲存的是一個連結串列的頭結點。而組成連結串列的結點其實就是hashmap內部定義的一個類:Entity
Entity包含三個元素:key,value和指向下一個Entity的next

若是,jdk1.8,則
HashMap的存取
HashMap的儲存--put : null key總是存放在Entry[]陣列的第一個元素
元素需要儲存在陣列中的位置。先判斷該位置上有沒有存有Entity,沒有的話就建立一個Entity<k,v>物件,新的Entity插入(put)的位置永遠是在連結串列的最前面。
HashMap的讀取--get : 先定位到陣列元素,再遍歷該元素處的連結串列.
覆蓋了equals方法之後一定要覆蓋hashCode方法,原因很簡單,比如,String a = new String(“abc”); String b = new String(“abc”); 如果不覆蓋hashCode的話,那麼a和b的hashCode就會不同。
HashMap是基於hashing的原理,我們使用put(key, value)儲存物件到HashMap中,使用get(key)從HashMap中獲取物件。當我們給put()方法傳遞鍵和值時,我們先對鍵呼叫hashCode()方法,返回的hashCode用於找到bucket位置來儲存Entry物件。
解決雜湊(HASH)衝突的主要方法
開放地址法
再hash法
鏈地址法
雜湊表及處理衝突的方法 http://blog.sina.com.cn/s/blog_6fd335bb0100v1ks.html
見
同步方法:ConcurrentHashMap
Hashtable的put和get方法均為synchronized的是執行緒安全的。
將HashMap預設劃分為了16個Segment,減少了鎖的爭用。
寫時加鎖讀時不加鎖減少了鎖的持有時間。
volatile特性約束變數的值在本地執行緒副本中修改後會立即同步到主執行緒中,保證了其他執行緒的可見性。
value外,其他的屬性都是final的,value是volatile型別的,都修飾為final表明不允許在此連結串列結構的中間或者尾部做新增刪除操作,每次只允許操作連結串列的頭部。
見
HashMap 的 hashcode 的作用?什麼時候需要重寫?如何解決雜湊衝突?查詢的時候流程是如何?
為什麼這麼說呢?考慮一種情況,當向集合中插入物件時,如何判別在集合中是否已經存在該物件了?(注意:集合中不允許重複的元素存在)
也許大多數人都會想到呼叫equals方法來逐個進行比較,這個方法確實可行。但是如果集合中已經存在一萬條資料或者更多的資料,如果採用equals方法去逐一比較,效率必然是一個問題。此時hashCode方法的作用就體現出來了,當集合要新增新的物件時,先呼叫這個物件的hashCode方法,得到對應的hashcode值。實際上在HashMap的具體實現中會用一個table儲存已經存進去的物件的hashcode值,如果table中沒有該hashcode值,它就可以直接存進去,不用再進行任何比較了;如果存在該hashcode值, 就呼叫它的equals方法與新元素進行比較,相同的話就不存了,不相同就雜湊其它的地址,所以這裡存在一個衝突解決的問題,這樣一來實際呼叫equals方法的次數就大大降低了。
HashMap有一個叫做Entry的內部類,它用來儲存key-value對。上面的Entry物件是儲存在一個叫做table的Entry陣列中。table的索引在邏輯上叫做“桶”(bucket),它儲存了連結串列的第一個元素。key的hashcode()方法用來找到Entry物件所在的桶。如果兩個key有相同的hash值(即衝突),他們會被放在table陣列的同一個桶裡面(以連結串列方式儲存)。key的equals()方法用來確保key的唯一性。key的value物件的equals()和hashcode()方法根本一點用也沒有。
Hashtable 概述
也是一個散列表,它儲存的內容是鍵值對(key-value)對映。
Hashtable 繼承於Dictionary,實現了Map、Cloneable、java.io.Serializable介面
Hashtable 的函式都是同步的,這意味著它是執行緒安全的。它的key、value都不可以為null。
Hashtable中的對映不是有序的。
Hashtable繼承於Dictionary類,實現了Map介面。Map是"key-value鍵值對"介面,Dictionary是聲明瞭操作"鍵值對"函式介面的抽象類。
hashtable與hashmap區別(筆試面試必考)
HashMap和Hashtable都實現了Map介面,但決定用哪一個之前先要弄清楚它們之間的分別。主要的區別有:執行緒安全性,同步(synchronization),以及速度。
HashMap幾乎可以等價於Hashtable,除了HashMap是非synchronized的,並可以接受null(HashMap可以接受為null的鍵值(key)和值(value),而Hashtable則不行)。
HashMap是非synchronized,而Hashtable是synchronized,這意味著Hashtable是執行緒安全的,多個執行緒可以共享一個Hashtable;而如果沒有正確的同步的話,多個執行緒是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的擴充套件性更好。
另一個區別是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以當有其它執行緒改變了HashMap的結構(增加或者移除元素),將會丟擲ConcurrentModificationException,但迭代器本身的remove()方法移除元素則不會丟擲ConcurrentModificationException異常。但這並不是一個一定發生的行為,要看JVM。這條同樣也是Enumeration和Iterator的區別。
由於Hashtable是執行緒安全的也是synchronized,所以在單執行緒環境下它比HashMap要慢。如果你不需要同步,只需要單一執行緒,那麼使用HashMap效能要好過Hashtable。
HashMap不能保證隨著時間的推移Map中的元素次序是不變的。
我們先看HashMap和Hashtable這兩個類的定義
public class Hashtable
extends Dictionary
implements Map, Cloneable, <a href="http://lib.csdn.net/base/javase" class='replace_word' title="Java SE知識庫" target='_blank' style='color:#df3434; font-weight:bold;'>Java</a>.io.Serializable public class HashMap
extends AbstractMap
implements Map, Cloneable, Serializable 可見Hashtable 繼承自 Dictiionary, 而 HashMap繼承自AbstractMap。
1) HashMap允許null鍵值的key,注意最多隻允許一條記錄的鍵為null,不允許多條記錄的值為null。
HashMap允許將null作為一個entry的key或者value,而Hashtable不允許。
2) HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因為contains方法容易讓人引起誤解。
Hashtable則保留了contains,containsValue和containsKey三個方法,其中contains和containsValue功能相同。
3) Hashtable的方法是執行緒安全的,而HashMap不支援執行緒的同步。
4) Hashtable使用Enumeration,HashMap使用Iterator。
4)hash值的使用不同,Hashtable直接使用物件的hashCode,而HashMap是
(1)繼承的父類不同
Hashtable繼承自Dictionary類,而HashMap繼承自AbstractMap類。但二者都實現了Map介面。
(2)執行緒安全性不同
Hashtable 中的方法是Synchronize的,而HashMap中的方法在預設情況下是非Synchronize的。在多執行緒併發的環境下,可以直接使用Hashtable,不需要自己為它的方法實現同步,但使用HashMap時就必須要自己增加同步處理。
(3)是否提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因為contains方法容易讓人引起誤解。
Hashtable則保留了contains,containsValue和containsKey三個方法,其中contains和containsValue功能相同。
(4)key和value是否允許null值
其中key和value都是物件,並且不能包含重複key,但可以包含重複的value。
Hashtable中,key和value都不允許出現null值。
HashMap中,null可以作為鍵,這樣的鍵只有一個;可以有一個或多個鍵所對應的值為null。當get()方法返回null值時,可能是 HashMap中沒有該鍵,也可能使該鍵所對應的值為null。因此,在HashMap中不能由get()方法來判斷HashMap中是否存在某個鍵, 而應該用containsKey()方法來判斷。
(5)兩個遍歷方式的內部實現上不同
Hashtable、HashMap都使用了 Iterator。而由於歷史原因,Hashtable還使用了Enumeration的方式 。
(6)hash值不同
雜湊值的使用不同,HashTable直接使用物件的hashCode。而HashMap重新計算hash值。
(7)內部實現使用的陣列初始化和擴容方式不同
Hashtable和HashMap它們兩個內部實現方式的陣列的初始大小和擴容的方式。HashTable中hash陣列預設大小是11,增加的方式是 old*2+1。
HashMap中hash陣列的預設大小是16,而且一定是2的指數。
hashmap與currenthashmap區別
Hashtable中採用的鎖機制是一次鎖住整個hash表,從而同一時刻只能由一個執行緒對其進行操作;
而ConcurrentHashMap中則是一次鎖住一個桶。
ConcurrentHashMap預設將hash表分為16個段,諸如get,put,remove等常用操作只鎖當前需要用到的桶。
Hashtable是執行緒安全的,它的方法是同步了的,可以直接用在多執行緒環境中。
而HashMap則不是執行緒安全的。在多執行緒環境中,需要手動實現同步機制。
Hashmap與Linkedhashmap區別
Linkedhashmap是hashmap子類多了after和behind方法。
LinkedHashMap比HashMap多維護了一個連結串列。
TreeMap
TreeMap的底層使用了紅黑樹來實現,像TreeMap物件中放入一個key-value 鍵值對時,就會生成一個Entry物件,這個物件就是紅黑樹的一個節點,其實這個和HashMap是一樣的,一個Entry物件作為一個節點,只是這些節點存放的方式不同。
存放每一個Entry物件時都會按照key鍵的大小按照二叉樹的規範進行存放,所以TreeMap中的資料是按照key從小到大排序的。
Arraylist 和 HashMap 如何擴容?負載因子有什麼作用?如何保證讀寫程序安全?
HashTable預設初始11個大小,預設每次擴容的因子為0.75,
HashMap預設初始16個大小(必須是2的次方),預設每次擴容的因子為0.75。
ArrayList,預設初始10個大小,每次擴容是原容量的一半。
Vector,預設初始10個大小,每次擴容是原容量的兩倍,
StringBuffer、StringBuilder預設初始化是16個字元,預設增容為(原長度+1)*2。
負載因子有什麼作用,必須在 "衝突的機會"與"空間利用率"之間尋找一種平衡與折衷。這種平衡與折衷本質上是資料結構中有名的"時-空"矛盾的平衡與折衷。
HashMap、LinkedHashMap、TreeMap、WeakHashMap
HashMap裡面存入的鍵值對在取出時沒有固定的順序,是隨機的。
一般而言,在Map中插入、刪除和定位元素,HashMap是最好的選擇。
由於TreeMap實現了SortMap介面,能夠把它儲存的記錄根據鍵排序,因此,取出來的是排序後的鍵值對,如果需要按自然順序或自定義順序遍歷鍵,那麼TreeMap會更好。
LinkedHashMap是HashMap的一個子類,如果需要輸出的順序和輸入相同,那麼用LinkedHashMap可以實現、它還可以按讀取順序來排列。
WeakHashMap中key採用的是“弱引用”的方式,只要WeakHashMap中的key不再被外部引用,它就可以被垃圾回收器回收。
而HashMap中key採用的是“強引用的方式”,當HashMap中的key沒有被外部引用時,只有在這個key從HashMap中刪除後,才可以被垃圾回收器回收。
“你用過HashMap嗎?” “什麼是HashMap?你為什麼用到它?”
幾乎每個人都會回答“是的”,然後回答HashMap的一些特性,譬如HashMap可以接受null鍵值和值,而Hashtable則不能;HashMap是非synchronized;HashMap很快;以及HashMap儲存的是鍵值對等等。這顯示出你已經用過HashMap,而且對它相當的熟悉。但是面試官來個急轉直下,從此刻開始問出一些刁鑽的問題,關於HashMap的更多基礎的細節。
面試官可能會問出下面的問題:
你知道HashMap的工作原理嗎? 你知道HashMap的get()方法的工作原理嗎?
你也許會回答“我沒有詳查標準的Java API,你可以看看Java原始碼或者Open JDK。”“我可以用Google找到答案。”
但一些面試者可能可以給出答案,“HashMap是基於hashing的原理,我們使用put(key,value)儲存物件到HashMap中,使用get(key)從HashMap中獲取物件(其實就是得到value,在java裡嘛,萬物皆物件)。當我們給put()方法傳遞鍵和值時,我們先對鍵呼叫hashCode()方法,返回的hashCode用於找到bucket位置來儲存Entry物件。”這裡關鍵點在於指出,HashMap是在bucket中儲存鍵物件和值物件,作為Map.Entry。這一點有助於理解獲取物件的邏輯。
如果你沒有意識到這一點,或者錯誤的認為僅僅只在bucket中儲存值的話,你將不會回答如何從HashMap中獲取物件的邏輯。這個答案相當的正確,也顯示出面試者確實知道hashing以及HashMap的工作原理。但是這僅僅是故事的開始,當面試官加入一些Java程式設計師每天要碰到的實際場景的時候,錯誤的答案頻現。
當兩個物件的hashcode相同會發生什麼?
從這裡開始,真正的困惑開始了,一些面試者會回答因為hashcode相同,所以兩個物件(即value)是相等的,HashMap將會丟擲異常,或者不會儲存它們。然後面試官可能會提醒他們有equals()和hashCode()兩個方法,並告訴他們兩個物件就算hashcode相同,但是它們可能並不相等。一些面試者可能就此放棄,而另外一些還能繼續挺進,他們回答“因為hashcode相同,所以它們的bucket位置相同,‘碰撞’會發生。因為HashMap使用連結串列儲存物件,這個Entry(包含有鍵值對的Map.Entry物件)會儲存在連結串列中。”這個答案非常的合理,雖然有很多種處理碰撞的方法,這種方法是最簡單的,也正是HashMap的處理方法。
如果兩個key的hashcode相同,你如何獲取值物件?
當我們呼叫get()方法,HashMap會使用鍵物件的hashcode找到bucket位置,找到bucket位置之後,會呼叫keys.equals()方法去找到連結串列中正確的節點,最終找到要找的值物件。
注意:面試官會問因為你並沒有值物件去比較,你是如何確定確定找到值物件的?除非面試者直到HashMap在連結串列中儲存的是鍵值對,否則他們不可能回答出這一題。
一些優秀的開發者會指出使用不可變的、宣告作final的物件,並且採用合適的equals()和hashCode()方法的話,將會減少碰撞的發生,提高效率。不可變性使得能夠快取不同鍵的hashcode,這將提高整個獲取物件的速度,使用String,Interger這樣的wrapper類作為鍵是非常好的選擇。
hashmap的儲存過程?
HashMap內部維護了一個儲存資料的Entry陣列,HashMap採用連結串列解決衝突,每一個Entry本質上是一個單向連結串列。當準備新增一個key-value對時,首先通過hash(key)方法計算hash值,然後通過indexFor(hash,length)求該key-value對的儲存位置,計算方法是先用hash&0x7FFFFFFF後,再對length取模,這就保證每一個key-value對都能存入HashMap中,當計算出的位置相同時,由於存入位置是一個連結串列,則把這個key-value對插入連結串列頭。
HashMap中key和value都允許為null。key為null的鍵值對永遠都放在以table[0]為頭結點的連結串列中。
hashMap擴容問題?
擴容是是新建了一個HashMap的底層陣列,而後呼叫transfer方法,將就HashMap的全部元素新增到新的HashMap中(要重新計算元素在新的陣列中的索引位置)。 很明顯,擴容是一個相當耗時的操作,因為它需要重新計算這些元素在新的陣列中的位置並進行復制處理。因此,我們在用HashMap的時,最好能提前預估下HashMap中元素的個數,這樣有助於提高HashMap的效能。
HashMap共有四個構造方法。構造方法中提到了兩個很重要的引數:初始容量和載入因子。這兩個引數是影響HashMap效能的重要引數,其中容量表示雜湊表中槽的數量(即雜湊陣列的長度),初始容量是建立雜湊表時的容量(從建構函式中可以看出,如果不指明,則預設為16),載入因子是雜湊表在其容量自動增加之前可以達到多滿的一種尺度,當雜湊表中的條目數超出了載入因子與當前容量的乘積時,則要對該雜湊表進行 resize 操作(即擴容)。
預設載入因子為0.75,如果載入因子越大,對空間的利用更充分,但是查詢效率會降低(連結串列長度會越來越長);如果載入因子太小,那麼表中的資料將過於稀疏(很多空間還沒用,就開始擴容了),對空間造成嚴重浪費。如果我們在構造方法中不指定,則系統預設載入因子為0.75,這是一個比較理想的值,一般情況下我們是無需修改的。
HashMap的複雜度
HashMap整體上效能都非常不錯,但是不穩定,為O(N/Buckets),N就是以陣列中沒有發生碰撞的元素。
