
吳恩達深度學習——優化演算法
1、mini-batch梯度下降法:
mini-batch size=m,就是我們平常用的梯度下降,即batch梯度下降
mini-batch size=1,則為隨機梯度下降:每次迭代,只對一個樣本進行梯度下降,大部分時間你向著全域性最小值靠近,但有時候會遠離最小值,因為那個樣本恰好指的方向不對,因此隨機下降是又很多噪聲的。平均看來,它最終會靠近最小值,因為隨機下降法永遠不會收斂,而是會在最小值附近波動,不會達到最小值而停留。
m相對來說太大,1又太小,因此需要選擇一個合適mini-batch尺寸,如果樣本集少於2000,可以直接用batch梯度下降法;若樣本集太大,一般可以用mini-batch尺寸為64~512(考慮到電腦記憶體設定和使用方式,用2的某次方會更好一些)

2、指數加權平均與指數加權平均的偏差修正
指數加權平均的關鍵函式:
vt是迭代得到的,最初令其為0,一步步迭代計算,但最後是一種平均數,我們用這種平均數來代替theta。可以認為我們由原來以往變化趨勢乘以一個權重beta,和當下的變化乘以權重1-beta,這樣可以兩者之和表現出一部分現在的變化,同時也更表現出了以往的一種應該發展的趨勢。
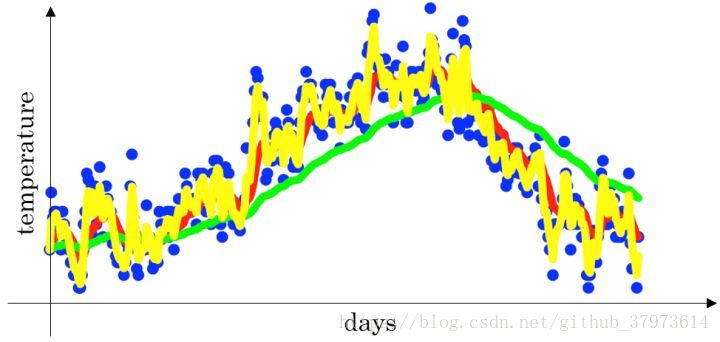
下面是一個關於溫度和天氣的散點圖:

- 當
時,指數加權平均最後的結果如圖中紅色線所示;比較合適的趨勢和上下波動
- 當
時,指數加權平均最後的結果如圖中綠色線所示;因為
較小,所以更多的體現了前面一部分趨勢
- 當
時,指數加權平均最後的結果如下圖中黃色線所示;因為
較大,所以波動較大,體現了一個變化
指數加權平局數公式的好處之一:它只佔用極少的記憶體,電腦記憶體只佔一行數字而已,不斷的覆蓋就可以了。當然它不是最好的,也不是最精確的。如果要計算移動窗,可以直接計算過去10天或者50天的和,再除以10或者50就好,如此往往得到更好的估測。但缺點是,必須佔用更多的記憶體,執行更加複雜。
來自吳恩達老師:
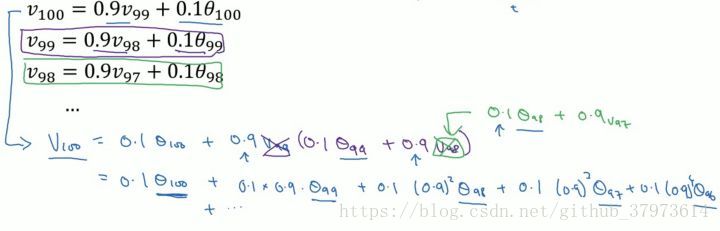
我們可以看到指數加權平均的求解過程實際上是一個遞推的過程,那麼這樣就會有一個非常大的好處,每當我要求從0到某一時刻(n)的平均值的時候,我並不需要像普通求解平均值的作為,保留所有的時刻值,類和然後除以n。而是只需要保留0-(n-1)時刻的平均值和n時刻的溫度值即可
3、momentum梯度下降
momentum梯度下降總是會比標準的梯度下降要快。基本的想法是,計算梯度的指數加權平均數,並利用該梯度更新你的權重。
如下圖:

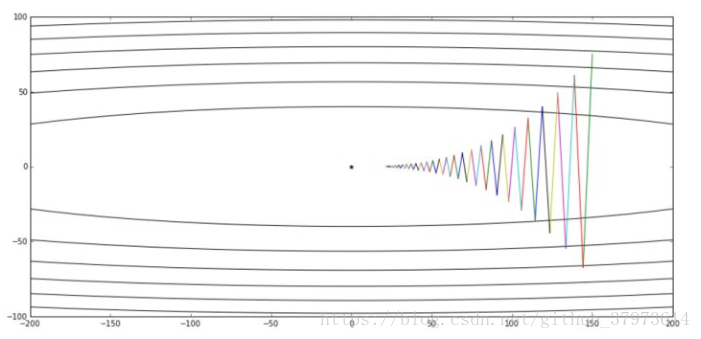
這個圖中,設初始點靠近橫軸,遠離縱軸,如果進行一次梯度下降的迭代,無論是batch還是mini-batch梯度下降法,都會計算很多步的迭代,在縱軸方向來回擺動很多次,慢慢的擺動到最小值。這種上下波動減慢了梯度下降法的速度,我們無法使用更大的學習率。因為如果使用了較大的學習率, 那麼結果可能會偏離函式的範圍。為了避免擺動過大,需要使用一個較小的學習率。
另一個角度來看:從縱軸上我們希望學習慢一點,而橫軸上我們希望學習的快一點,希望在橫軸上我們快速接近最小值點。所以使用momentum梯度下降,我們需要做的是,在每次迭代中,確切來說,是在第t次迭代中,我們會計算微分dw,db。用現有的mini-batch計算dw,db。
V_dW = β*V_dW + (1-β)*dW
V_db = β*V_db + (1-β)*db
更新引數:
W = W - α*V_dW
b = b - α*V_db
這樣就可以減緩梯度下降的幅度了,在縱軸上擺動變小,在橫軸上運動更快。
Momentum的一個本質,就是如果你要最小化碗狀函式,他們能夠最小化碗狀函式,這些微分項(dW,db),想象它們是你從山上往下滾的一個球,提供了加速度,Momentum項(V_dW,V_db)就相當於速度。微分給了這個球一個加速度,此時球正往山下滾,球因為加速度越滾越快,因為β稍小於1,表現出一些摩擦力,所以球不會無限加速下去,所以【不像梯度下降法每一步都獨立於之前的步驟】,你的球可以向下滾,獲得動量,可以從碗向下加速,獲得動量。
具體如何計算:
公式還是上面的四個公式,所以你有兩個超引數,學習率α以及引數β。β控制著指數加權平均數,β最常用的值是0.9,即我們之前平均了過去十天的溫度,所以在這裡就是【平均了前十次迭代的梯度】,實際上,β為0.9時效果不錯,你可以嘗試不同的值,可以做一些超引數的研究,不過0.9是很棒的魯棒數。

4、RMSprop:root mean square prop
該演算法也可以加速梯度下降。

這裡假設引數b的梯度處於縱軸方向,引數w的梯度處於橫軸方向(當然實際中是處於高維度的情況),利用RMSprop演算法,可以減小某些維度梯度更新波動較大的情況,如圖中藍色線所示,使其梯度下降的速度變得更快,如圖綠色線所示。
在如圖所示的實現中,RMSprop將微分項進行平方,然後使用平方根進行梯度更新,同時為了確保演算法不會除以0,平方根分母中在實際使用會加入一個很小的值如 。
5、Adam演算法
Adam (Adaptive Moment Estimation)優化演算法的基本思想就是將 Momentum 和 RMSprop 結合起來形成的一種適用於不同深度學習結構的優化演算法。
演算法實現
- 初始化:
- 第
次迭代:
- Compute
on the current mini-batch
----- “Momentum”
----- “RMSprop”
----- 偏差修正
----- 偏差修正
- Compute
超引數的選擇
:需要進行除錯;
:常用預設值為0.9,
的加權平均;
:推薦使用0.999,
的加權平均值;
:推薦使用
。
6、學習率衰減
實現:
- 常用:
- 指數衰減:
- 其他:
- 離散下降(不同階段使用不同的學習速率)
7、區域性最優
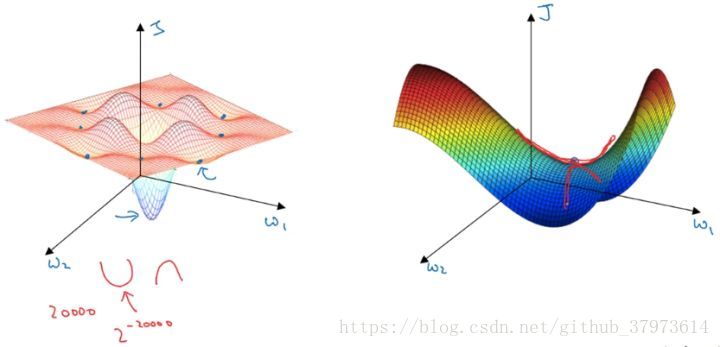
在低維度的情形下,我們可能會想象到一個Cost function 如左圖所示,存在一些區域性最小值點,在初始化引數的時候,如果初始值選取的不得當,會存在陷入區域性最優點的可能性。
但是,如果我們建立一個高維度的神經網路。通常梯度為零的點,並不是如左圖中的區域性最優點,而是右圖中的鞍點(叫鞍點是因為其形狀像馬鞍的形狀)。
在一個具有高維度空間的函式中,如果梯度為0,那麼在每個方向,Cost function可能是凸函式,也有可能是凹函式。但如果引數維度為2萬維,想要得到區域性最優解,那麼所有維度均需要是凹函式,其概率為 ,可能性非常的小。也就是說,在低維度中的區域性最優點的情況,並不適用於高維度,在梯度為0的點更有可能是鞍點,而不是區域性最小值點。
在高緯度的情況下:
- 幾乎不可能陷入區域性最小值點;
- 處於鞍點的停滯區會減緩學習過程,利用如Adam等演算法進行改善。