
#匈牙利演算法和Kuhn-Munkres演算法
阿新 • • 發佈:2019-01-23
內容摘自高隨祥的《圖論與網路流理論》一書

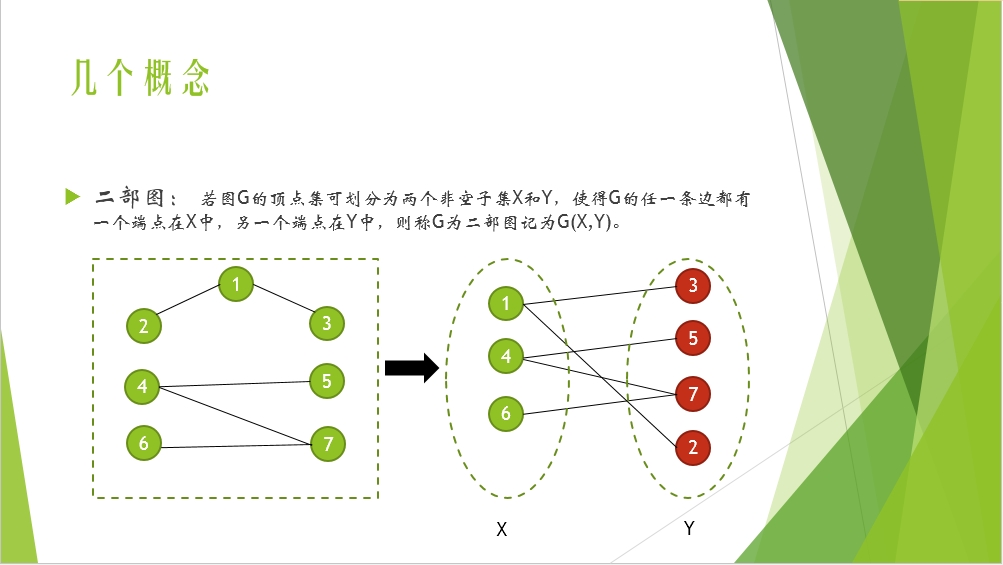

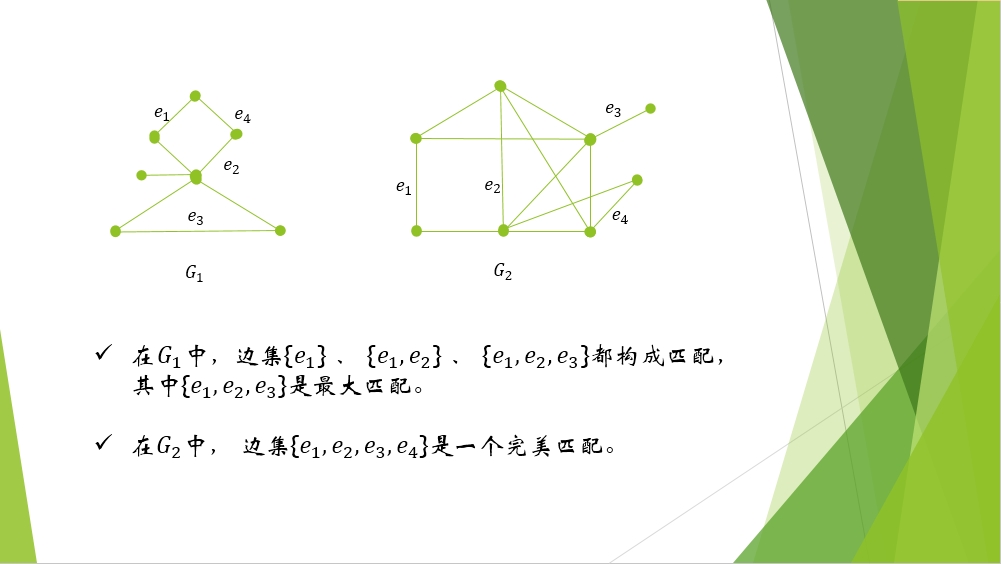
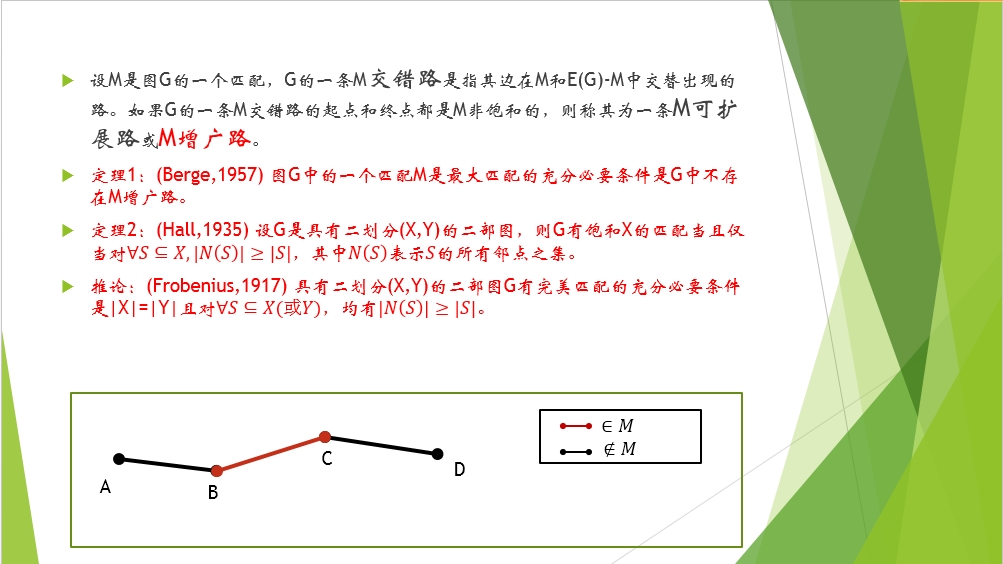
|N(S)|或者|X|或|Y|表示的是相應集合的元素的個數。
N(S)表示與S集合中的頂點相鄰接的頂點,例如,A-B-C-D中,B的鄰接點就是A和C。
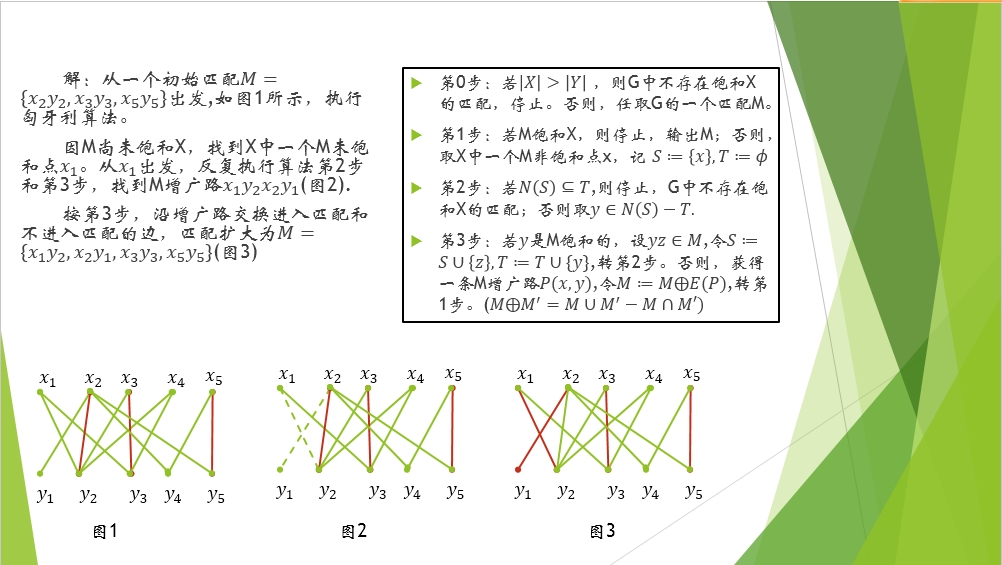
A-B-C-D是一條增廣路,紅色線表示屬於M匹配,黑色線表示不屬於,圖中,B,C兩點是M飽和的,A,D兩點是非M飽和的。

上面這個演算法只是針對飽和X的,意思就是,如果X中的每個頂點都已匹配上,那麼演算法終止,而不必管Y中的頂點是否都有匹配。
圓圈裡面一個加號的運算其實可以簡單理解為增廣路的取反,所謂取反就是把屬於M匹配的邊變成不屬於M的邊,把不屬於M的邊變為屬於M的邊,在那個A-B-C-D的增廣路的圖例中就是把A-B和C-D邊變成紅色而把B-C邊變成黑色。這樣做一個明顯的作用就是匹配的邊數增多了一條!
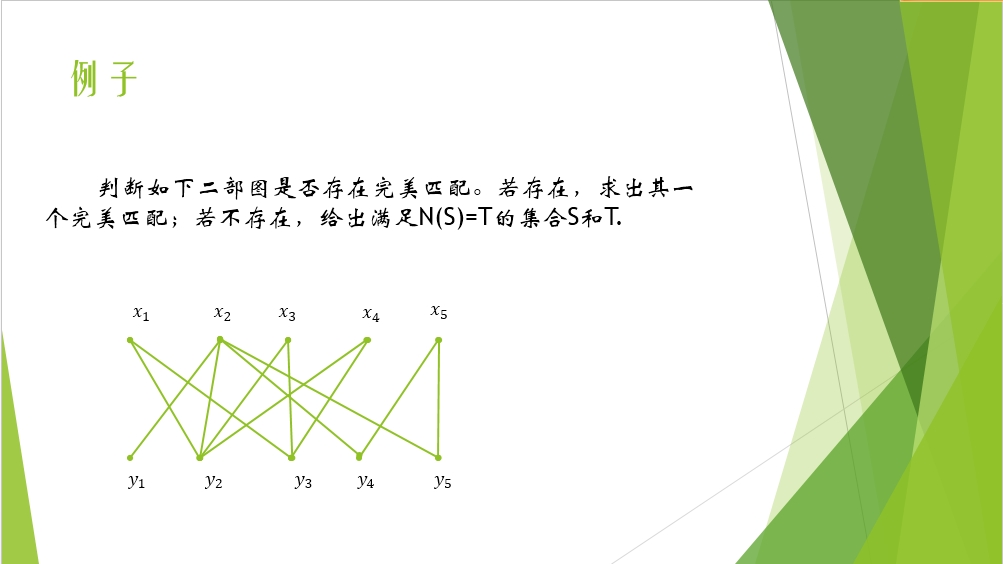
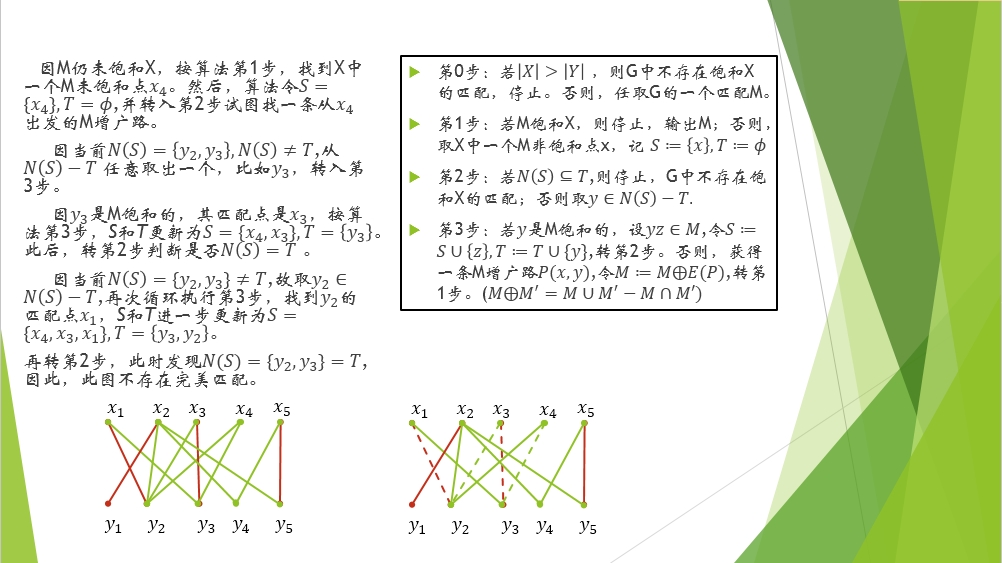
下面是求二部圖最大匹配的匈牙利演算法,就是不管X還是Y,我們求得是含匹配邊最多的匹配


一般的,我們會這樣取頂點標號的值:l(y)全部賦值為0,而l(x)取得是和頂點x相鄰接的所有的點之間的權重的最大值。下面有個例子用的就是這個方法。
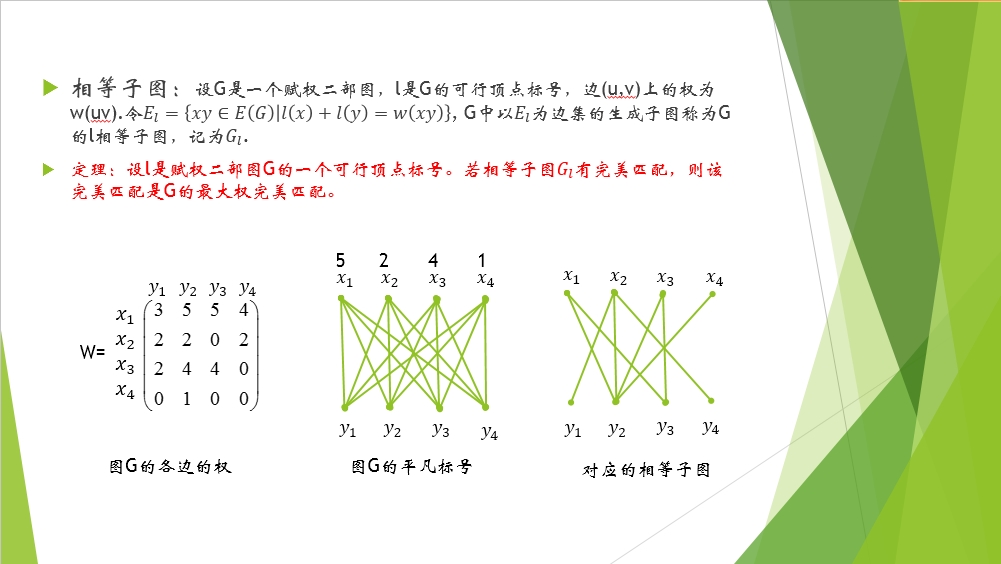
“圖G的平凡標號”那個圖上X集中的各頂點上的數字5,2,4,1就是頂點標號,Y集中的頂點標號全為0。

上面這個修改標號的過程是KM演算法區別於匈牙利演算法的地方。修改的目的是在目前找到的M匹配的基礎上增加可行頂點,從而得到增廣路。
