
《機器學習實戰》學習筆記之第五章—— Logistic迴歸
第五章 Logistic迴歸
Logistic迴歸的一般過程:
(1) 收集資料:採用任意方法收集資料。
(2) 準備資料:由於需要進行距離計算,因此要求資料型別為數值型。另外,結構化資料
格式則最佳。
(3) 分析資料:採用任意方法對資料進行分析。
(4) 訓練演算法:大部分時間將用於訓練,訓練的目的是為了找到最佳的分類迴歸係數。
(5) 測試演算法:一旦訓練步驟完成,分類將會很快。
(6) 使用演算法:首先,我們需要輸入一些資料,並將其轉換成對應的結構化數值;
接著,基於訓練好的迴歸係數就可以對這些數值進行簡單的迴歸計算,判定它們屬於
哪個類別,在這之後,我們就可以在輸出的類別上做一些其他分析工作。Logistic迴歸優缺點:
優點:計算代價不高,易於理解和實現。
缺點:容易欠擬合,分類精度可能不高。 .
適用資料型別:數值型和標稱型資料。
迴歸:對一些資料點,演算法訓練出直線引數,得到最佳擬合直線,能夠對這些點很好的擬合。
訓練分類器主要是尋找最佳擬合引數,故為最優化演算法。
5.1 基於Logistic迴歸和sigmoid函式的分類
實現Logistic迴歸分類器:在每個特徵上都乘以一個迴歸係數,然後把所有的結果值相加,總和帶入sigmoid函式,其結果大於0.5分為第0類,結果小於0.5分為第0類。
Sigmoid函式公式:
sigmoid函式具有很好的性質,如其導數可以用其本身表示等等。

5.2 基於最優化方法的最佳迴歸係數確定
sigmoid函式輸入z:
其可以寫成z=w.T*x,向量x為分類器的輸入資料, w為訓練器尋找的最佳引數。
梯度上升法:
思想:要找到某函式的最大值,最好的方法是沿著該函式的梯度方向探尋。
函式f(x,y)的梯度:
沿x的方向移動
,沿y的方向移動
,最後能夠到達最優點,但是f(x,y)在待計算點需要有定義並且可微。
梯度運算元總是指向函式值增長最快的方向。移動方向為梯度方向,移動量大小需要乘以一個引數,稱之為步長。引數迭代公式為:
公式可一直執行,直到某個條件停止為止。如迭代次數或者演算法達到某個可以允許的誤差範圍。
訓練演算法:使用梯度上升找到最佳引數。
梯度上升法虛擬碼:
基於上面的內容,我們來看一個Logistic迴歸分類器的應用例子,從圖5-3可以看到我們採的資料集。
資料點:
5.2.2訓練演算法:使用梯度上升找到最佳引數(python):
# -*- coding: utf-8 -*-
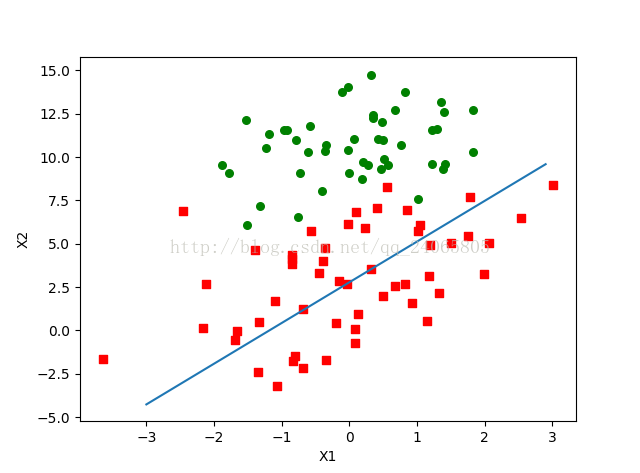
from numpy import * #下載資料 def loadDataSet(): dataMat = []; labelMat = [] fr = open('testSet.txt') for line in fr.readlines(): lineArr = line.strip().split() #刪除空格 dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #X0=1,X1,X2 #print(dataMat) labelMat.append(int(lineArr[2])) #label #print (labelMat) #print(dataMat,labelMat) return dataMat, labelMatdef sigmoid(inX): return longfloat(1.0/(1+exp(-inX))) #梯度上升 def gradAscent(dataMatIn, classLabels): dataMatrix = mat(dataMatIn) #convert to NumPy matrix labelMat = mat(classLabels).transpose() #convert to NumPy matrix,and 轉置 m, n = shape(dataMatrix) #行數m=100,列數n=3 alpha = 0.001 #步長 maxCycles = 500 #迭代次數 weights = ones((n,1)) for k in range(maxCycles): #heavy on matrix operations h = sigmoid(dataMatrix*weights) #matrix mult error = (labelMat - h) #vector subtraction weights = weights + alpha * dataMatrix.transpose() * error #matrix mult # 梯度上升 return weights #3*1def plotBestFit(weights): import matplotlib.pyplot as plt dataMat, labelMat = loadDataSet() dataArr = array(dataMat) n = shape(dataArr)[0] #行數n xcord1 = []; ycord1 = [] xcord2 = []; ycord2 = [] #統計label for i in range(n): if int(labelMat[i]) == 1: xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) else: xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) fig = plt.figure() ax = fig.add_subplot(111) #將畫布分成一行一列第一個圖 ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') ax.scatter(xcord2, ycord2, s=30, c='green') x = arange(-3.0, 3.0, 0.1) #(-3,3)之間間隔0.1 # 擬合曲線為0 = w0*x0+w1*x1+w2*x2, 故x2 = (-w0*x0-w1*x1)/w2, x0為1,x1為x, x2為y,故有 y = (-weights[0]-weights[1]*x)/weights[2] #z等於0,是sigmiod函式的分界線 ax.plot(x, y) plt.xlabel('X1') plt.ylabel('X2') plt.show()#測試程式 datamat, labels = loadDataSet() weights = gradAscent(datamat, labels) #x為array格式,weights為matrix格式,故需要呼叫getA()方法,其將matrix()格式矩陣轉為array()格式 #getA()方法,其將matrix()格式矩陣轉為array()格式,type(weights),type(weights.getA())可觀察到。 plotBestFit(weights.getA())輸出結果,最優分界線:
訓練演算法:隨機梯度上升
梯度上升演算法中,每次更新迴歸係數需要遍歷整個資料集。資料量若是大了,計算複雜度較高。
改進方法:一次僅用一個樣本點更新迴歸係數,這便是隨機梯度上升演算法。
虛擬碼:
程式碼:
#隨機梯度上升 def stocGradAscent0(dataMatrix, classLabels): m,n = shape(dataMatrix) alpha = 0.01 weights = ones(n) #initialize to all ones for i in range(m): h = sigmoid(sum(dataMatrix[i]*weights)) error = classLabels[i] - h weights = weights + alpha * error * dataMatrix[i] return weights weights0 = stocGradAscent0(array(datamat),labels) plotBestFit(weights0)程式碼結果顯示:
Figure 5-4: 隨機梯度上升演算法分割線
結果顯示其效果還不如梯度上升演算法,不過不一樣,梯度上升演算法,500次迭代每次都用上了所有資料,而隨機梯度上升演算法總共也只用了500次。需要對其進行改進:
#改進的隨機梯度上升 def stocGradAscent1(dataMatrix, classLabels, numIter=150): m, n = shape(dataMatrix) weights = ones(n) #initialize to all ones for j in range(numIter): dataIndex = range(m) for i in range(m): alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant h = sigmoid(sum(dataMatrix[randIndex]*weights)) #print(dataMatrix[randIndex], weights) error = classLabels[randIndex] - h weights = weights + alpha * error * dataMatrix[randIndex] del(dataIndex[randIndex]) return weights weights1 = stocGradAscent1(array(datamat), labels) plotBestFit(weights1)
Figure 5-5: 改進的隨機梯度上升演算法分割線


5.3 示例:從疝氣病症預測病馬的死亡率
準備資料:處理資料中的缺失值
可選做法:
- 使用可用特徵的均值來填補缺失值
- 使用特殊值來填補缺失值,如-1
- 忽略有缺失值的樣本
- 使用相似樣本的均值添補缺失值
- 使用另外的機器學習演算法預測缺失值
測試演算法:用Logistic迴歸進行分類
def classifyVector(inX, weights): prob = sigmoid(sum(inX*weights)) if prob > 0.5: return 1.0 else: return 0.0 def colicTest(): frTrain = open('horseColicTraining.txt') frTest = open('horseColicTest.txt') trainingSet = []; trainingLabels = [] for line in frTrain.readlines(): currLine = line.strip().split('\t') lineArr =[] for i in range(21): #21個特徵,1個label lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[21])) #print(trainingSet) trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000) errorCount = 0; numTestVec = 0.0 for line in frTest.readlines(): numTestVec += 1.0 #統計測試樣本數量 currLine = line.strip().split('\t') lineArr =[] for i in range(21): lineArr.append(float(currLine[i])) if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]): errorCount += 1 errorRate = (float(errorCount)/numTestVec) print "the error rate of this test is: %f" % errorRate return errorRate#多次測試def multiTest(): numTests = 10; errorSum=0.0 for k in range(numTests): errorSum += colicTest() print "after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests)) multiTest()
Figure 5-7: 測試結果
5.4 小結
Logistic迴歸:
Logistic迴歸目的是尋找一個非線性函式Sigmoid 的最佳擬合引數,求解過程可以由最優化演算法來完成。在最優化演算法中,最常用的就是梯度上升演算法,而梯度上升演算法又可以簡化為隨機梯度上升演算法。
隨機梯度上升演算法與梯度上升演算法的效果相當,但佔用更少的計算資源。此外,隨機梯度上升是一個線上演算法,它可以在新資料到來時就完成引數更新,而不需要重新讀取整個資料集來進行批處理運算。