
【mahout筆記】初步理解itemCF(基於物品的推薦演算法)在mahout的實現
之前分析了基於使用者的CF的原理。今天嘗試除錯一下基於物品的CF演算法。
感謝大佬的整理為我指明方向。
基於物品的CF的原理和基於使用者的CF類似,只是在計算鄰居時採用物品本身,而不是從使用者的角度,即基於使用者對物品的偏好找到相似的物品,然後根據使用者的歷史偏好,推薦相似的物品給他。從計算的角度看,就是將所有使用者對某個物品的偏好作為一個向量來計算物品之間的相似度,得到物品的相似物品後,根據使用者歷史的偏好預測當前使用者還沒有表示偏好的物品,計算得到一個排序的物品列表作為推薦。圖3給出了一個例子,對於物品A,根據所有使用者的歷史偏好,喜歡物品A的使用者都喜歡物品C,得出物品A和物品C比較相似,而使用者C喜歡物品A,那麼可以推斷出使用者C可能也喜歡物品C.
雖然都是基於使用者偏好來做計算的演算法,但是UserCF是基於使用者的相似度,而ItemCF更多的是計算物品的相似度。
因為部分演算法都是一樣的,請允許我跳過讀取資料的階段,有需要可以看我的上一篇部落格和上上篇部落格。
我的演示是根據大佬的部落格做的,程式碼如下:
public static void itemCF(DataModel dataModel) throws TasteException { ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel); RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true); RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7); RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2); LongPrimitiveIterator iter = dataModel.getUserIDs(); while (iter.hasNext()) { long uid = iter.nextLong(); List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM); RecommendFactory.showItems(uid, list, true); } }
1.生成itemSimilarity物件
其實根據我們的傳參可以看出我們還是要建一個歐幾里得距離的相似度的物件,如果我們手動回憶一下上一篇UserCF的內容,你會發現這裡生成的ItemSimilarity和上一篇裡生成的UserSimilarity物件實際上都是一個EuclideanDistanceSimilarity物件,一毛一樣。
所以請允許我鄭重跳過這一步,各種校驗和賦值,然後把引數放了進去。
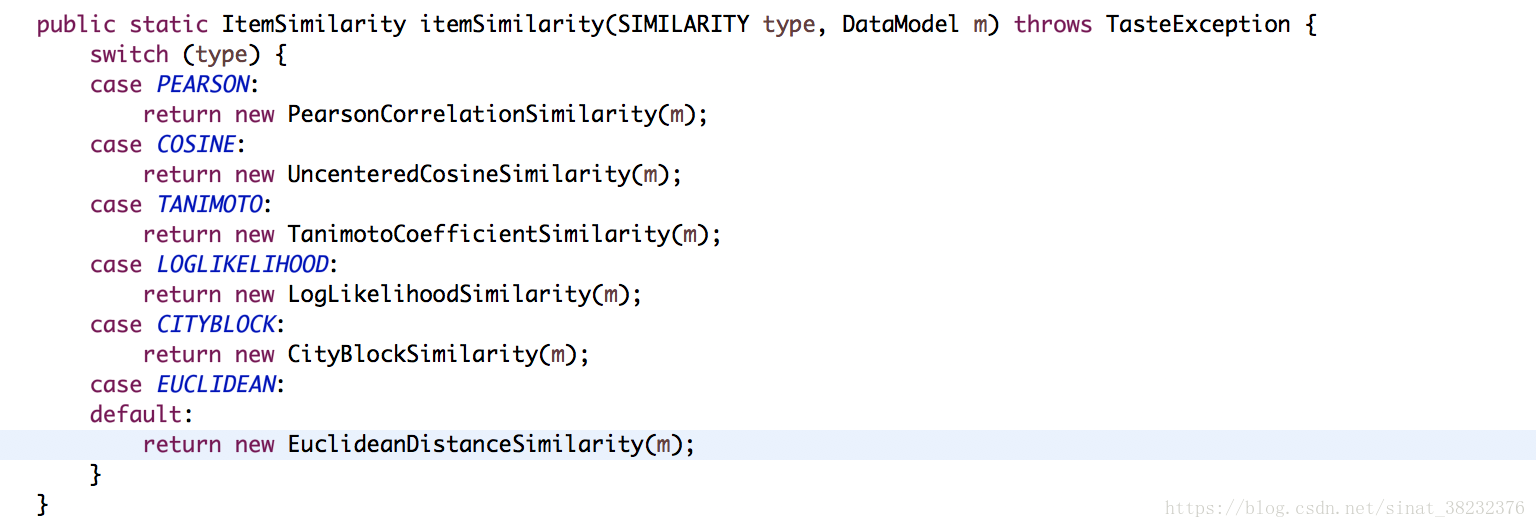
2.生成一個RecommenderBuilder物件
實際上根據傳入用引數,我們是建立了一個GenericItemBasedRecommender物件,新建這個物件的操作也和UserCF那個沒有多大差別,看了原始碼,基本上就是現有的資料進行各種校驗和賦值,EMM,賦值賦值賦值......如下三張圖所示,沒有任何計算和處理資料過程:

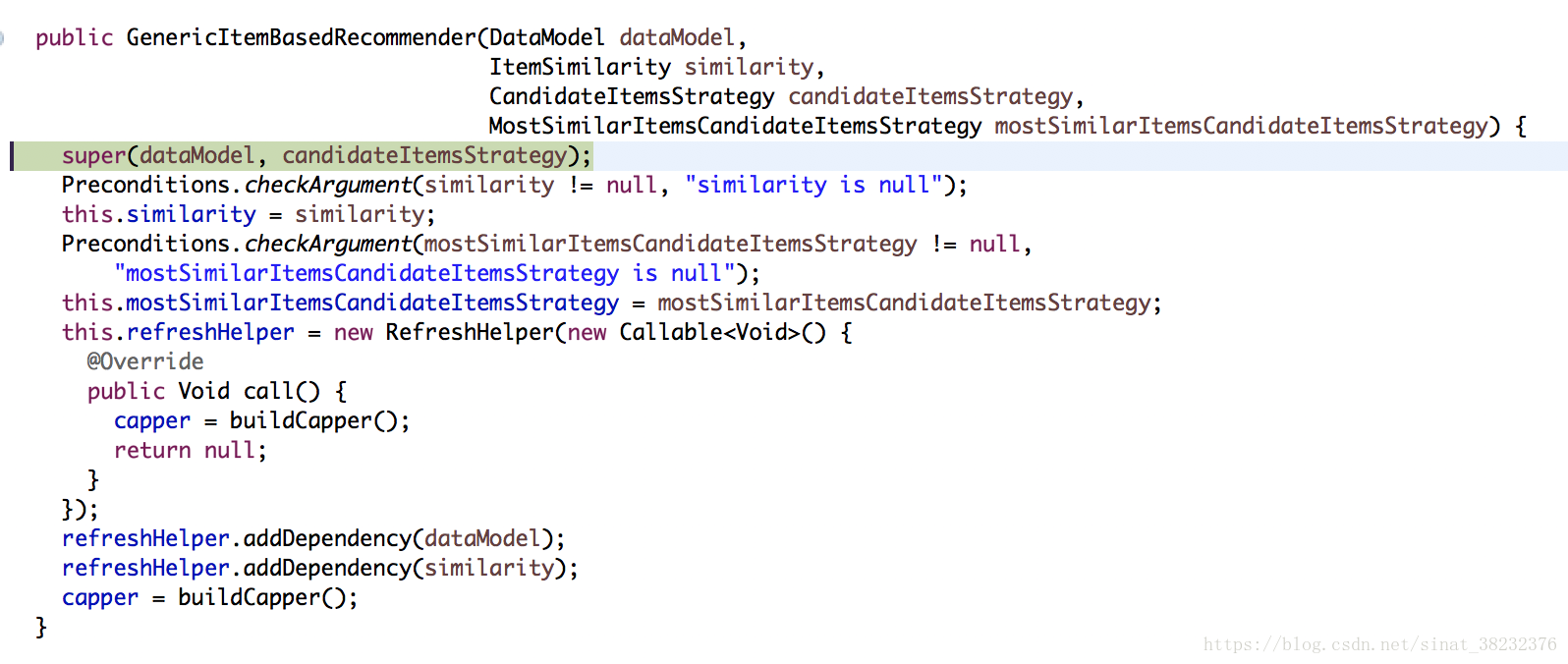

3.評價
實際上,從UserCF的原始碼可以看出,從這裡開始終於有開始計算的邏輯了,痛哭。終於可以讓我認認真真的看看邏輯了。
和之前一樣,我們建立了一個基於平均絕對距離的評價器:

包括初始化了一些屬性,生成了一個專用的隨機數生成器,然後過,用這個評價器進入評價環節。

評價方法用的和userCF是同一個,先是對資料集進行分組,將資料分為訓練集和測試集,到生成訓練模型這一步都是用的和UserCF一樣的方法。

之後生成一個GenericItemBasedRecommender,並使用這個導購物件進行評價計算,也就是getEvaluation()方法。
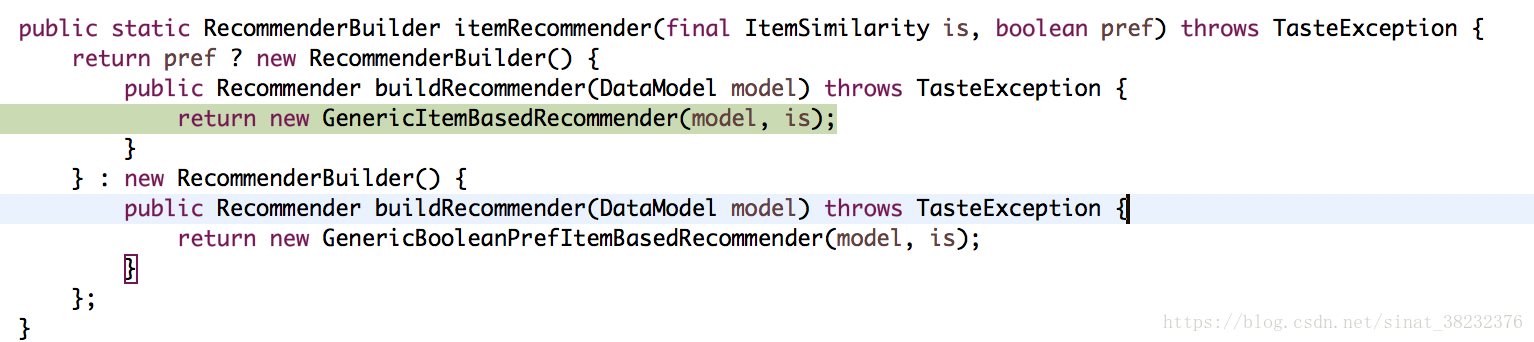
計算評價分數的這一步同樣是使用了多執行緒:
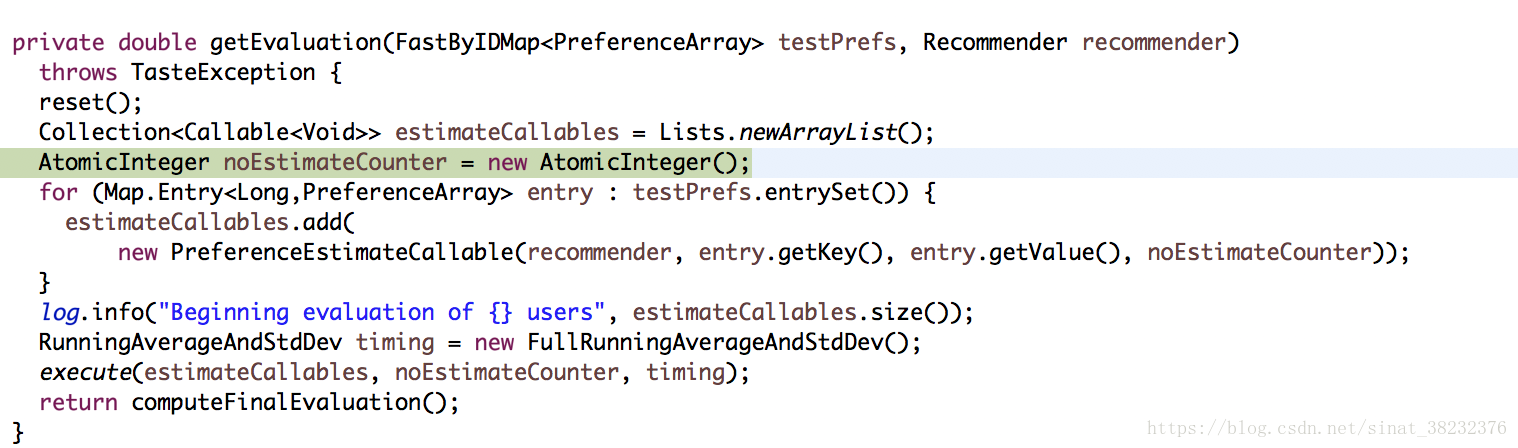

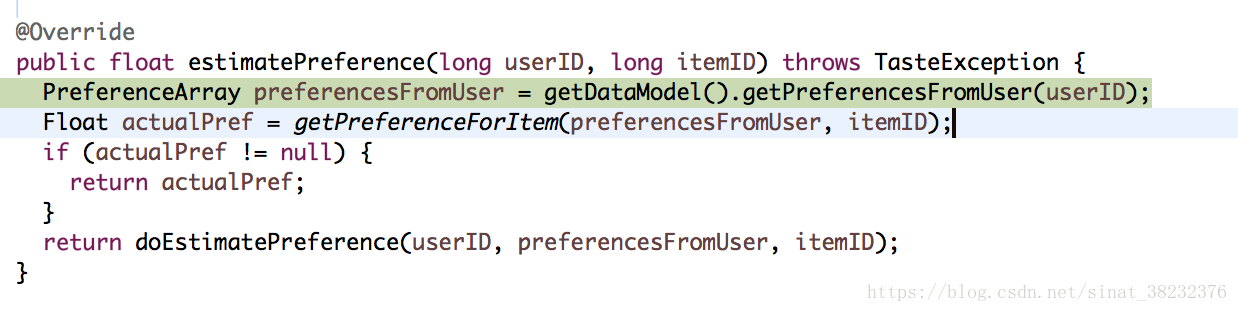
但是因為我們的Recommender類是GenericItemBasedRecommender,這個類的doEstimatePreference()方法和以使用者為基礎的推薦類完全不同了,他同樣是判斷了訓練資料集中沒有該使用者對該物品的真實評分(也就是這個資料確實在測試集中而不是在訓練集中,不然預測就沒有意義),然後進行了評分預測。從這一步開始,計算的步驟會和UserCF有很大的差別。
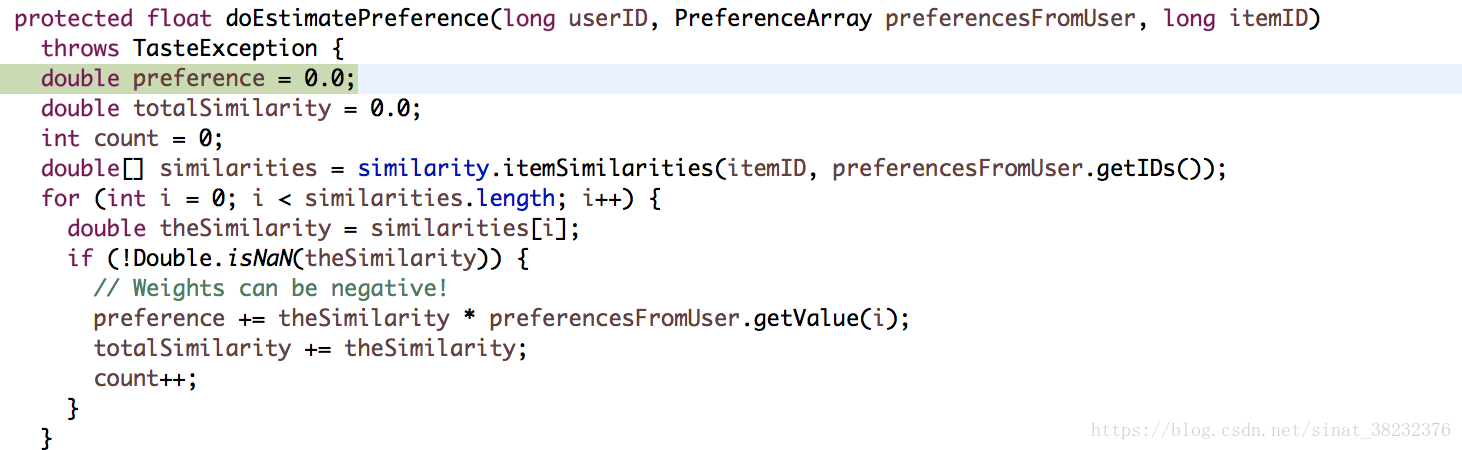
從上圖可以看出,我們這次不會再進行使用者的相似度計算,而是計算物品的相似度,是繼承讓這個兩個完全不同的方法可以在同一套流程中順利進行。這種寫法還真是教科書般的寫法。
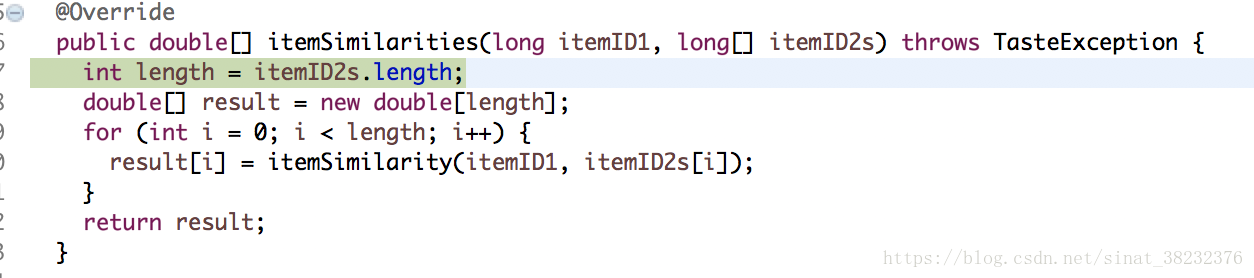
@Override
public final double itemSimilarity(long itemID1, long itemID2) throws TasteException {
DataModel dataModel = getDataModel();
PreferenceArray xPrefs = dataModel.getPreferencesForItem(itemID1);
PreferenceArray yPrefs = dataModel.getPreferencesForItem(itemID2);
int xLength = xPrefs.length();
int yLength = yPrefs.length();
if (xLength == 0 || yLength == 0) {
return Double.NaN;
}
long xIndex = xPrefs.getUserID(0);
long yIndex = yPrefs.getUserID(0);
int xPrefIndex = 0;
int yPrefIndex = 0;
double sumX = 0.0;
double sumX2 = 0.0;
double sumY = 0.0;
double sumY2 = 0.0;
double sumXY = 0.0;
double sumXYdiff2 = 0.0;
int count = 0;
// No, pref inferrers and transforms don't appy here. I think.
while (true) {
int compare = xIndex < yIndex ? -1 : xIndex > yIndex ? 1 : 0;
if (compare == 0) {
// Both users expressed a preference for the item
double x = xPrefs.getValue(xPrefIndex);
double y = yPrefs.getValue(yPrefIndex);
sumXY += x * y;
sumX += x;
sumX2 += x * x;
sumY += y;
sumY2 += y * y;
double diff = x - y;
sumXYdiff2 += diff * diff;
count++;
}
if (compare <= 0) {
if (++xPrefIndex == xLength) {
break;
}
xIndex = xPrefs.getUserID(xPrefIndex);
}
if (compare >= 0) {
if (++yPrefIndex == yLength) {
break;
}
yIndex = yPrefs.getUserID(yPrefIndex);
}
}
double result;
if (centerData) {
// See comments above on these computations
double n = (double) count;
double meanX = sumX / n;
double meanY = sumY / n;
// double centeredSumXY = sumXY - meanY * sumX - meanX * sumY + n * meanX * meanY;
double centeredSumXY = sumXY - meanY * sumX;
// double centeredSumX2 = sumX2 - 2.0 * meanX * sumX + n * meanX * meanX;
double centeredSumX2 = sumX2 - meanX * sumX;
// double centeredSumY2 = sumY2 - 2.0 * meanY * sumY + n * meanY * meanY;
double centeredSumY2 = sumY2 - meanY * sumY;
result = computeResult(count, centeredSumXY, centeredSumX2, centeredSumY2, sumXYdiff2);
} else {
result = computeResult(count, sumXY, sumX2, sumY2, sumXYdiff2);
}
if (similarityTransform != null) {
result = similarityTransform.transformSimilarity(itemID1, itemID2, result);
}
if (!Double.isNaN(result)) {
result = normalizeWeightResult(result, count, cachedNumUsers);
}
return result;
}
計算相似度的方法和UserCF非常接近(這句話我不知道說了多少次了),取出兩個物品的評分矩陣,如果訓練集中兩個矩陣有一個為空矩陣,則直接返回Double.NaN。如果兩個矩陣都不為空,則分別取出第一個user的id,如果id相同,則分別取出各自的評分算出各種值和差值,如果各自矩陣的userId沒有取完,則分別取下一個;如果id不同,則保留較大的那個,較小的跳過取下一個userId,直到其中一個矩陣的userId被取空。相似度的計算公式為1/(1+sqrt((x1-y1)^2+(x2-y2)^2+...+(xn-yn)^2))/sqrt(n)。x y分別是不同使用者的分值。其實sqrt(n)更像一個正則量,我在上一篇也說過。
歐幾里得距離計算的程式碼截圖我就不放出了。
最後根據和UserCF一樣的公式出預測分數: 計假設使用者對物品a的評分為x,a與該物品相似度為sa, 對物品b的評分為y,b與該物品相似度為sb,則使用者對本物品的預測評分公式為, (x*sa+y*sb)/(sa+sb).停留的那一句程式碼,目的是為了控制住評分的範圍,不會因為相似物品有很多就評分爆表。
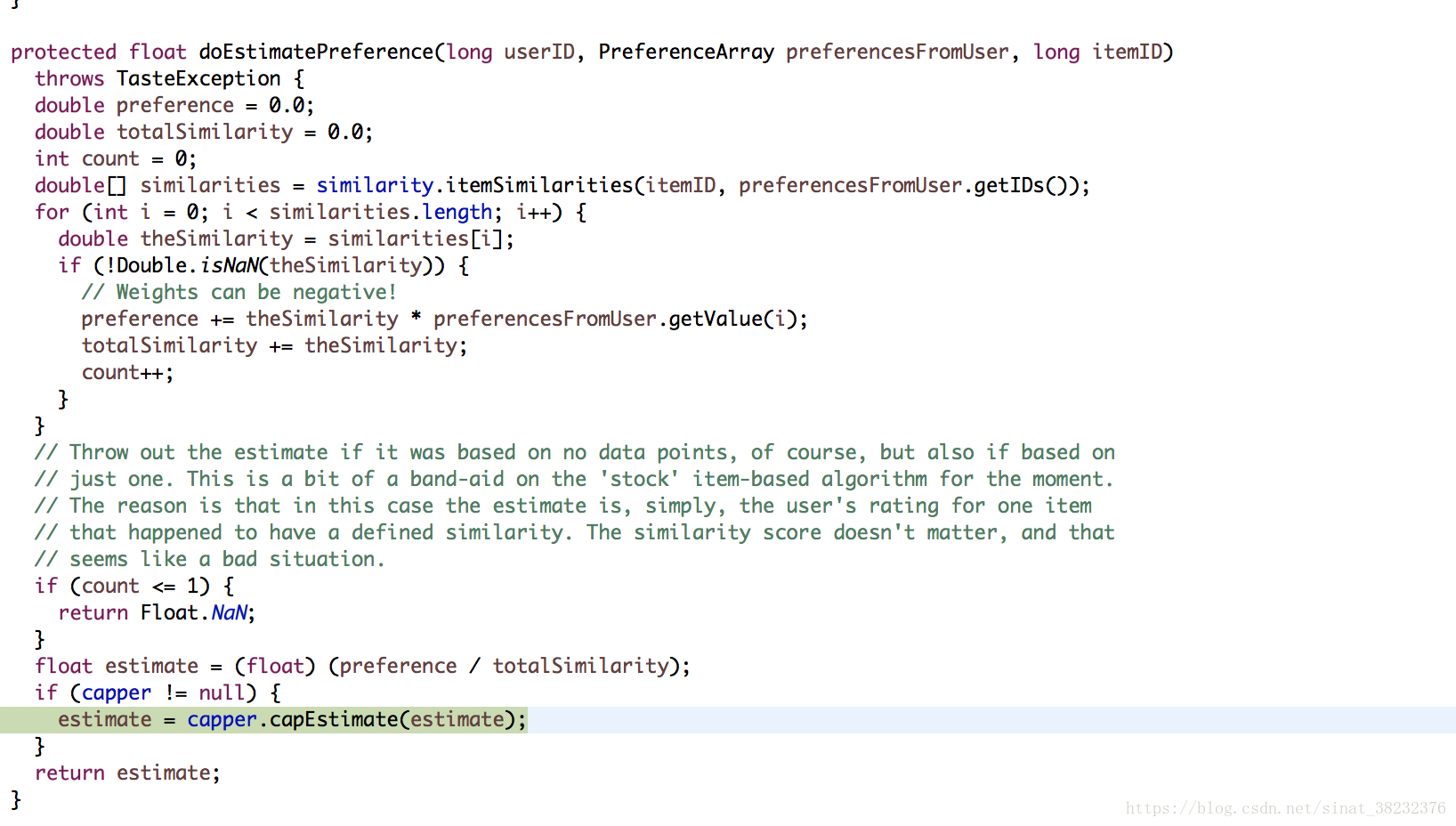
之後做的事情就是拿實際評分和預測評分進行對比,計算差值的絕對值diff。
每個物品的預測過程都在多執行緒中進行,最後都會把diff彙總到一起,計算diff的平均值作為分數。

4. 計算模型準確率和召回率
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);準確率和召回率的定義我們就不再重複了,下面直接開始截原始碼圖:

@Override
public IRStatistics evaluate(RecommenderBuilder recommenderBuilder,
DataModelBuilder dataModelBuilder,
DataModel dataModel,
IDRescorer rescorer,
int at,
double relevanceThreshold,
double evaluationPercentage) throws TasteException {
Preconditions.checkArgument(recommenderBuilder != null, "recommenderBuilder is null");
Preconditions.checkArgument(dataModel != null, "dataModel is null");
Preconditions.checkArgument(at >= 1, "at must be at least 1");
Preconditions.checkArgument(evaluationPercentage > 0.0 && evaluationPercentage <= 1.0,
"Invalid evaluationPercentage: %s", evaluationPercentage);
int numItems = dataModel.getNumItems();
RunningAverage precision = new FullRunningAverage();
RunningAverage recall = new FullRunningAverage();
RunningAverage fallOut = new FullRunningAverage();
RunningAverage nDCG = new FullRunningAverage();
int numUsersRecommendedFor = 0;
int numUsersWithRecommendations = 0;
LongPrimitiveIterator it = dataModel.getUserIDs();
while (it.hasNext()) {
long userID = it.nextLong();
if (random.nextDouble() >= evaluationPercentage) {
// Skipped
continue;
}
long start = System.currentTimeMillis();
PreferenceArray prefs = dataModel.getPreferencesFromUser(userID);
// List some most-preferred items that would count as (most) "relevant" results
double theRelevanceThreshold = Double.isNaN(relevanceThreshold) ? computeThreshold(prefs) : relevanceThreshold;
FastIDSet relevantItemIDs = dataSplitter.getRelevantItemsIDs(userID, at, theRelevanceThreshold, dataModel);
int numRelevantItems = relevantItemIDs.size();
if (numRelevantItems <= 0) {
continue;
}
FastByIDMap<PreferenceArray> trainingUsers = new FastByIDMap<PreferenceArray>(dataModel.getNumUsers());
LongPrimitiveIterator it2 = dataModel.getUserIDs();
while (it2.hasNext()) {
dataSplitter.processOtherUser(userID, relevantItemIDs, trainingUsers, it2.nextLong(), dataModel);
}
DataModel trainingModel = dataModelBuilder == null ? new GenericDataModel(trainingUsers)
: dataModelBuilder.buildDataModel(trainingUsers);
try {
trainingModel.getPreferencesFromUser(userID);
} catch (NoSuchUserException nsee) {
continue; // Oops we excluded all prefs for the user -- just move on
}
int size = relevantItemIDs.size() + trainingModel.getItemIDsFromUser(userID).size();
if (size < 2 * at) {
// Really not enough prefs to meaningfully evaluate this user
continue;
}
Recommender recommender = recommenderBuilder.buildRecommender(trainingModel);
int intersectionSize = 0;
List<RecommendedItem> recommendedItems = recommender.recommend(userID, at, rescorer);
for (RecommendedItem recommendedItem : recommendedItems) {
if (relevantItemIDs.contains(recommendedItem.getItemID())) {
intersectionSize++;
}
}
int numRecommendedItems = recommendedItems.size();
// Precision
if (numRecommendedItems > 0) {
precision.addDatum((double) intersectionSize / (double) numRecommendedItems);
}
// Recall
recall.addDatum((double) intersectionSize / (double) numRelevantItems);
// Fall-out
if (numRelevantItems < size) {
fallOut.addDatum((double) (numRecommendedItems - intersectionSize)
/ (double) (numItems - numRelevantItems));
}
// nDCG
// In computing, assume relevant IDs have relevance 1 and others 0
double cumulativeGain = 0.0;
double idealizedGain = 0.0;
for (int i = 0; i < recommendedItems.size(); i++) {
RecommendedItem item = recommendedItems.get(i);
double discount = i == 0 ? 1.0 : 1.0 / log2(i + 1);
if (relevantItemIDs.contains(item.getItemID())) {
cumulativeGain += discount;
}
// otherwise we're multiplying discount by relevance 0 so it doesn't do anything
// Ideally results would be ordered with all relevant ones first, so this theoretical
// ideal list starts with number of relevant items equal to the total number of relevant items
if (i < relevantItemIDs.size()) {
idealizedGain += discount;
}
}
nDCG.addDatum(cumulativeGain / idealizedGain);
// Reach
numUsersRecommendedFor++;
if (numRecommendedItems > 0) {
numUsersWithRecommendations++;
}
long end = System.currentTimeMillis();
log.info("Evaluated with user {} in {}ms", userID, end - start);
log.info("Precision/recall/fall-out/nDCG: {} / {} / {} / {}", new Object[] {
precision.getAverage(), recall.getAverage(), fallOut.getAverage(), nDCG.getAverage()
});
}
double reach = (double) numUsersWithRecommendations / (double) numUsersRecommendedFor;
return new IRStatisticsImpl(
precision.getAverage(),
recall.getAverage(),
fallOut.getAverage(),
nDCG.getAverage(),
reach);
}
根據引數,我們可以看出,這次依然使用閾值的方式來判斷是否是正相關,而在程式碼中依然可以看出我們依舊使用某種演算法來計算每個使用者的閾值。

計算閾值的方式依然是平均值+標準差。
使用者對某物品的評分大於這個閾值的時候,說明這個物品和該使用者正相關。
我們可以依次整理每個使用者所有的真實評分,整理出與該使用者正相關的物品到底是哪些,也就是下面這部分程式碼(上上圖中包含):
/ List some most-preferred items that would count as (most) "relevant" results
double theRelevanceThreshold = Double.isNaN(relevanceThreshold) ? computeThreshold(prefs) : relevanceThreshold;
FastIDSet relevantItemIDs = dataSplitter.getRelevantItemsIDs(userID, at, theRelevanceThreshold, dataModel);
int numRelevantItems = relevantItemIDs.size();
if (numRelevantItems <= 0) {
continue;
}
然後我們在資料集中抽取了部分(大部分)作為訓練集,具體演算法是,把該使用者以外所有使用者的資料都一股腦塞進去當測試集,只有遇到自己的時候把正相關的物品id拿掉,也就是隻放非正相關的資料。
@Override
public void processOtherUser(long userID,
FastIDSet relevantItemIDs,
FastByIDMap<PreferenceArray> trainingUsers,
long otherUserID,
DataModel dataModel) throws TasteException {
PreferenceArray prefs2Array = dataModel.getPreferencesFromUser(otherUserID);
// If we're dealing with the very user that we're evaluating for precision/recall,
if (userID == otherUserID) {
// then must remove all the test IDs, the "relevant" item IDs
List<Preference> prefs2 = Lists.newArrayListWithCapacity(prefs2Array.length());
for (Preference pref : prefs2Array) {
prefs2.add(pref);
}
for (Iterator<Preference> iterator = prefs2.iterator(); iterator.hasNext(); ) {
Preference pref = iterator.next();
if (relevantItemIDs.contains(pref.getItemID())) {
iterator.remove();
}
}
if (!prefs2.isEmpty()) {
trainingUsers.put(otherUserID, new GenericUserPreferenceArray(prefs2));
}
} else {
// otherwise just add all those other user's prefs
trainingUsers.put(otherUserID, prefs2Array);
}
}總結一下就是某個使用者的訓練集裡只放其他使用者的全部資料和該使用者的非正相關資料。
然後如果我們要對某一使用者推薦n件物品,那麼這個演算法要求該使用者已有2*n個評分資料才可以。
然後我們根據訓練集,計算所其他使用者與該使用者的相似度,然後根據相似度,訓練集中除已有該使用者評價的物品以外的物品的預測評分,返回前2(由我們傳入引數決定).這部分程式碼和上面幾乎一樣,所以不重新說一遍了。
最後我們用實際正相關的物品和我們預測正相關的物品進行對比。根據公式計算準確率和召回率。
5. 正式推薦
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}其實和上一篇一樣,到了這一步以後,基本上所用的程式碼都在之前的模組裡提到過了。
到這一步實際上預測流程和算準確率召回率中的推薦那一步一模一樣,只是訓練集不再是部分資料。而是把所有已知資料作為訓練集,然後計算物品之間的相關度,對使用者沒評價過的物品挨個進行估分(有些能估出來,有些則不能),然後對估分進行排序,取出估分最高的3個(引數傳入)作為推薦資料。