
特徵工程和模型融合--機器學習--思維導圖和筆記(29)
一、思維導圖(點選圖方法)
二、補充筆記
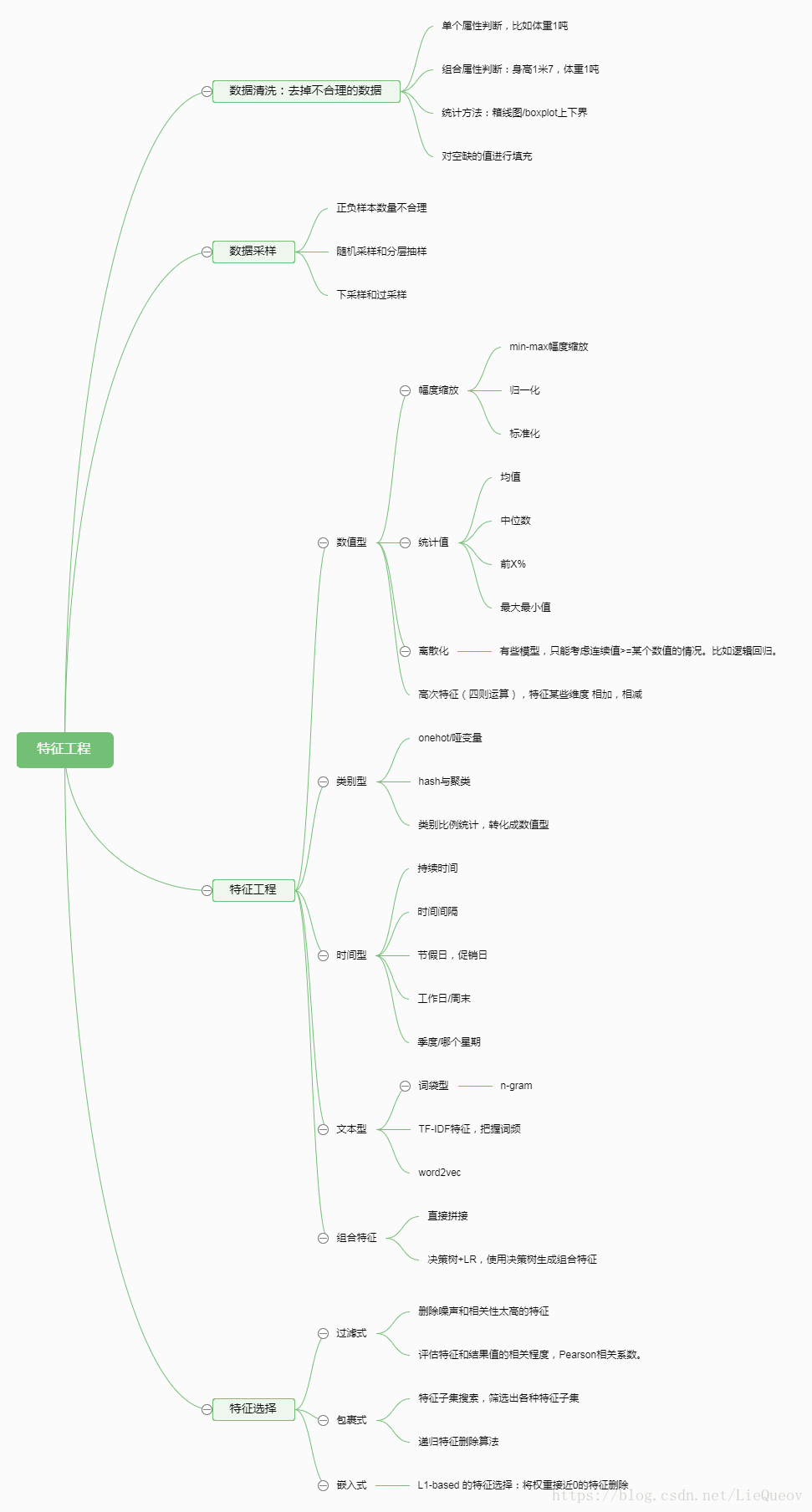
(1)常見的特徵工程主要指對各種型別的特徵進行處理,包括數值型特徵、類別型特徵、時間型特徵和其他型別特徵和組合特徵。對於數值型特徵,可以進行幅度調整(包括min-max縮放、標準化、歸一化)、統計值分析(最大值、最小值、平均值等)、離散化、高次特徵、通過特徵的四則運算獲取新特徵、或將數值型特徵轉換為類別型。對於類別型特徵,可以進行one-hot編碼(也叫啞變數)、hash技巧、分桶對映等。對於時間型特徵,既可以看成連續值,也可看成離散值。當為連續值的時候,可以計算持續時間、間隔時間。看成離散值的時候,可以得到比如這個日期是工作日還是休息日等。對於其他型別,比如文字型特徵,可以使用詞袋模型、TF-IDF模型、word2vec模型等轉換成向量形式。對於組合特徵,將兩個或者多個特徵直接拼接就可,或者採用樹模型產生特徵組合的路徑。
(2)特徵選擇的方法包括過濾式,包裹式和嵌入式。過濾式的特徵選擇,通過Pearson相關係數、互資訊等指標,將單特徵和結果的相關性進行評估,來對特徵進行選擇。包裹式的特徵選擇,是將特徵選擇轉化為從所有特徵集合中選擇出最優的特徵子集。一般採用遞迴特徵刪除演算法,根據模型的預測結果,刪除一些特徵。嵌入式的特徵選擇,是進行L1正則化後,會發現有些特徵的權重近乎為0,那麼認為就認為這些特徵對結果沒有貢獻,可以將這些特徵刪除。
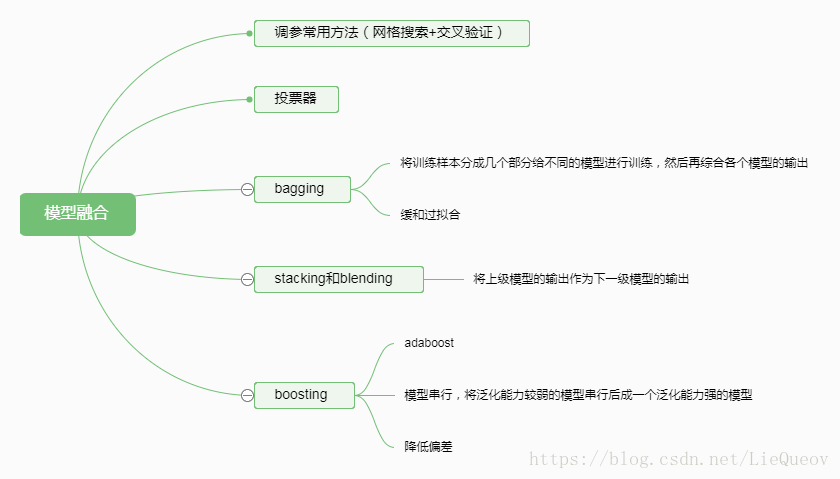
(3)常見的模型融合方法包括,投票器、Bagging、stacking、blending和boosting。投票器是採取少數服從多數的思想,如果是分類問題,將所有模型的輸出進行投票,得票高的那一類就為模型的總輸出。Bagging是將進行取樣後,分成幾個部分,每個部分訓練一個模型,最後將這些模型的輸出集合起來。Stacking使用上層的模型輸出作為下一層模型的輸入,Blending是弱化版的Stacking,相當於對上層模型的輸出進行了線性加權。Boosting是將泛化能力較弱的模型序列整合起來,生成一個泛化模型強的模型。