
分散式系統設計系列 -- 基本原理及高可用策略
”分散式系統設計“系列第一篇文章,這篇文章主要介紹一些入門的概念和原理,後面帶來一些高可用、資料分佈的實踐方法!!
各位親,如果你們覺得本文有還不錯的地方,請點選“投一票”支援本文,多謝!
==> 分散式系統中的概念==> 分散式系統與單節點的不同
==> 分散式系統特性
==> 分散式系統設計策略
==> 分散式系統設計實踐
【分散式系統中的概念】
三元組
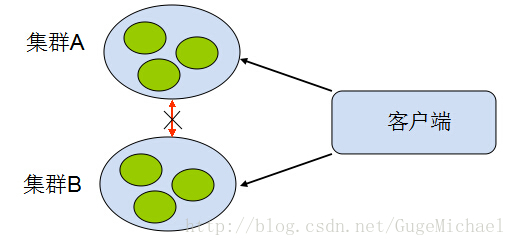
其實,分散式系統說白了,就是很多機器組成的叢集,靠彼此之間的網路通訊,擔當的角色可能不同,共同完成同一個事情的系統。如果按”實體“來劃分的話,就是如下這幾種:1、節點
2、網路 -- 系統的資料傳輸通道,用來彼此通訊。通訊是具有方向性的。
3、儲存 -- 系統中持久化資料的資料庫或者檔案儲存。
如圖

狀態特性
各個節點的狀態可以是“無狀態”或者“有狀態的”.
一般認為,節點是偏計算和通訊的模組,一般是無狀態的。這類應用一般不會儲存自己的中間狀態資訊,比如Nginx,一般情況下是轉發請求而已,不會儲存中間資訊。另一種“有狀態”的,如mysql等資料庫,狀態和資料全部持久化到磁碟等介質。
“無狀態”的節點一般我們認為是可隨意重啟的,因為重啟後只需要立刻工作就好。“有狀態”的則不同,需要先讀取持久化的資料,才能開始服務。所以,“無狀態”的節點一般是可以隨意擴充套件的,“有狀態”的節點需要一些控制協議來保證擴充套件。系統異常
異常,可認為是節點因為某種原因不能工作,此為節點異常。還有因為網路原因,臨時、永久不能被其他節點所訪問,此為網路異常。在分散式系統中,要有對異常的處理,保證叢集的正常工作。【分散式系統與單節點的不同】
1、從linux write()系統呼叫說起
眾所周知,在unix/linux/mac(類Unix)環境下,兩個機器通訊,最常用的就是通過socket連線對方。傳輸資料的話,無非就是呼叫write()這個系統呼叫,把一段記憶體緩衝區發出去。但是可以進一步想一下,write()之後能確認對方收到了這些資料嗎?答案肯定是不能,原因就是傳送資料需要走核心->網絡卡->鏈路->對端網絡卡->核心,這一路徑太長了,所以只能是非同步操作。write()把資料寫入核心緩衝區之後就返回到應用層了,具體後面何時傳送、怎麼傳送、TCP怎麼做滑動視窗、流控都是tcp/ip協議棧核心的事情了。
所以在應用層,能確認對方受到了訊息只能是對方應用返回資料,邏輯確認了這次傳送才認為是成功的。這就卻別與單系統程式設計,大部分系統呼叫、庫呼叫只要返回了就說明已經確認完成了。
2、TCP/IP協議是“不可靠”的
教科書上明確寫明瞭網際網路是不可靠的,TCP實現了可靠傳輸。何來“不可靠”呢?先來看一下網路互動的例子,有A、B兩個節點,之間通過TCP連線,現在A、B都想確認自己發出的任何一條訊息都能被對方接收並反饋,於是開始瞭如下操作:A->B傳送資料,然後A需要等待B收到資料的確認,B收到資料後傳送確認訊息給A,然後B需要等待A收到資料的確認,A收到B的資料確認訊息後再次傳送確認訊息給B,然後A又去需要等待B收到的確認。。。死迴圈了!!
其實,這就是著名的“拜占庭將軍”問題:
所以,通訊雙方是“不可能”同時確認對方受到了自己的資訊。而教科書上定義的其實是指“單向”通訊是成立的,比如A向B發起Http呼叫,收到了HttpCode 200的響應包,這隻能確認,A確認B收到了自己的請求,並且B正常處理了,不能確認的是B確認A受到了它的成功的訊息。
3、不可控的狀態
在單系統程式設計中,我們對系統狀態是非常可控的。比如函式呼叫、邏輯運算,要麼成功,要麼失敗,因為這些操作被框在一個機器內部,cpu/匯流排/記憶體都是可以快速得到反饋的。開發者可以針對這兩個狀態很明確的做出程式上的判斷和後續的操作。
而在分散式的網路環境下,這就變得微妙了。比如一次rpc、http呼叫,可能成功、失敗,還有可能是“超時”,這就比前者的狀態多了一個不可控因素,導致後面的程式碼不是很容易做出判斷。試想一下,用A用支付寶向B轉了一大筆錢,當他按下“確認”後,介面上有個圈在轉啊轉,然後顯示請求超時了,然後A就抓狂了,不知道到底錢轉沒轉過去,開始確認自己的賬戶、確認B的賬戶、打電話找客服等等。
所以分散式環境下,我們的其實要時時刻刻考慮面對這種不可控的“第三狀態”設計開發,這也是挑戰之一。
4、視”異常“為”正常“
單系統下,程序/機器的異常概率十分小。即使出現了問題,可以通過人工干預重啟、遷移等手段恢復。但在分散式環境下,機器上千臺,每幾分鐘都可能出現宕機、宕機、網路斷網等異常,出現的概率很大。所以,這種環境下,程序core掉、機器掛掉都是需要我們在程式設計中認為隨時可能出現的,這樣才能使我們整個系統健壯起來,所以”容錯“是基本需求。
異常可以分為如下幾類:
節點錯誤:
一般是由於應用導致,一些coredump和系統錯誤觸發,一般重新服務後可恢復。
硬體錯誤:
由於磁碟或者記憶體等硬體裝置導致某節點不能服務,需要人工干預恢復。
網路錯誤:
由於點對點的網路抖動,暫時的訪問錯誤,一般拓撲穩定後或流量減小可以恢復。
網路分化:
網路中路由器、交換機錯誤導致網路不可達,但是網路兩邊都正常,這類錯誤比較難恢復,並且需要在開發時特別處理。【這種情況也會比較前面的問題較難處理】
【分散式系統特性】
CAP是分散式系統裡最著名的理論,wiki百科如下
Consistency(all nodes see the same data at the same time)
Availability (a guarantee that every request receives a response about whether it was successful or failed)
Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
(摘自 :http://en.wikipedia.org/wiki/CAP_theorem)
早些時候,國外的大牛已經證明了CAP三者是不能兼得,很多實踐也證明了。
本人就不挑戰權威了,感興趣的同學可以自己Google。本人以自己的觀點總結了一下:
一致性
描述當前所有節點儲存資料的統一模型,分為強一致性和弱一致性:
強一致性描述了所有節點的資料高度一致,無論從哪個節點讀取,都是一樣的。無需擔心同一時刻會獲得不同的資料。是級別最高的,實現的代價比較高
如圖:

弱一致性又分為單調一致性和最終一致性:
1、單調一致性強調資料是按照時間的新舊,單調向最新的資料靠近,不會回退,如:
資料存在三個版本v1->v2->v3,獲取只能向v3靠近(如取到的是v2,就不可能再次獲得v1)
2、最終一致性強調資料經過一個時間視窗之後,只要多嘗試幾次,最終的狀態是一致的,是最新的資料
如圖:
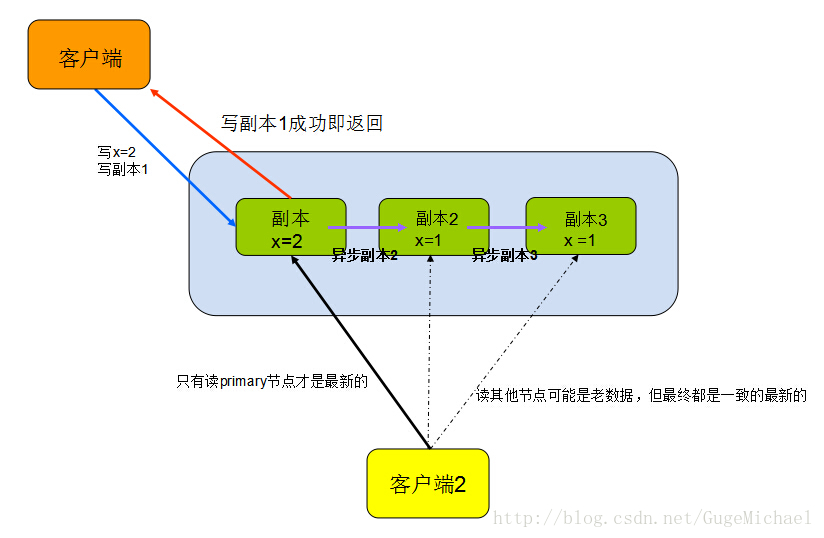
強一致性的場景,就好像交易系統,存取錢的+/-操作必須是馬上一致的,否則會令很多人誤解。
弱一致性的場景,大部分就像web網際網路的模式,比如發了一條微博,改了某些配置,可能不會馬上生效,但重新整理幾次後就可以看到了,其實弱一致性就是在系統上通過業務可接受的方式換取了一些系統的低複雜度和可用性。
可用性
保證系統的正常可執行性,在請求方看來,只要傳送了一個請求,就可以得到恢復無論成功還是失敗(不會超時)!
分割槽容忍性
在系統某些節點或網路有異常的情況下,系統依舊可以繼續服務。
這通常是有負載均衡和副本來支撐的。例如計算模組異常可通過負載均衡引流到其他平行節點,儲存模組通過其他幾點上的副本來對外提供服務。
擴充套件性
擴充套件性是融合在CAP裡面的特性,我覺得此處可以單獨講一下。擴充套件性直接影響了分散式系統的好壞,系統開發初期不可能把系統的容量、峰值都考慮到,後期肯定牽扯到擴容,而如何做到快而不太影響業務的擴容策略,也是需要考慮的。(後面在介紹資料分佈時會著重討論這個問題)
【分散式系統設計策略】
1、重試機制
一般情況下,寫一段網路互動的程式碼,發起rpc或者http,都會遇到請求超時而失敗情況。可能是網路抖動(暫時的網路變更導致包不可達,比如拓撲變更)或者對端掛掉。這時一般處理邏輯是將請求包在一個重試迴圈塊裡,如下:
int retry = 3;
while(!request() && retry--)
sched_yield(); // or usleep(100)此種模式可以防止網路暫時的抖動,一般停頓時間很短,並重試多次後,請求成功!但不能防止對端長時間不能連線(網路問題或程序問題)
2、心跳機制
心跳顧名思義,就是以固定的頻率向其他節點彙報當前節點狀態的方式。收到心跳,一般可以認為一個節點和現在的網路拓撲是良好的。當然,心跳彙報時,一般也會攜帶一些附加的狀態、元資料資訊,以便管理。如下圖: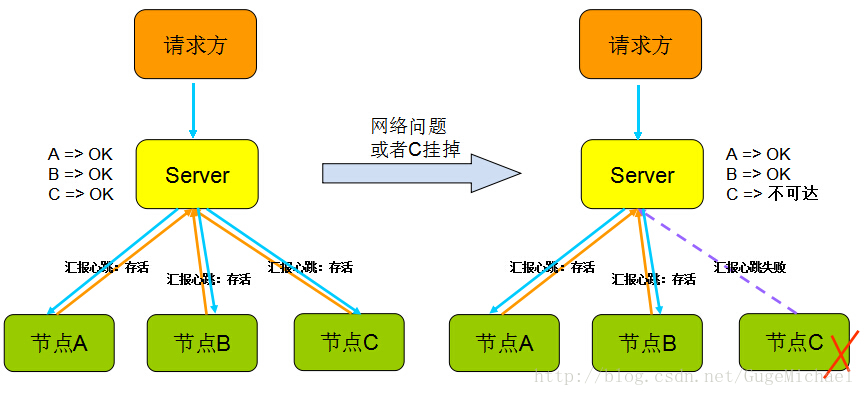
但心跳不是萬能的,收到心跳可以確認ok,但是收不到心跳卻不能確認節點不存在或者掛掉了,因為可能是網路原因倒是鏈路不通但是節點依舊在工作。
所以切記,”心跳“只能告訴你正常的狀態是ok,它不能發現節點是否真的死亡,有可能還在繼續服務。(後面會介紹一種可靠的方式 -- Lease機制)
3、副本
副本指的是針對一份資料的多份冗餘拷貝,在不同的節點上持久化同一份資料,當某一個節點的資料丟失時,可以從副本上獲取資料。資料副本是分散式系統解決資料丟失異常的僅有的唯一途徑。當然對多份副本的寫入會帶來一致性和可用性的問題,比如規定副本數為3,同步寫3份,會帶來3次IO的效能問題。還是同步寫1份,然後非同步寫2份,會帶來一致性問題,比如後面2份未寫成功其他模組就去讀了(下個小結會詳細討論如果在副本一致性中間做取捨)。
4、中心化/無中心化
系統模型這方面,無非就是兩種:
中心節點,例如mysql的MSS單主雙從、MongDB Master、HDFS NameNode、MapReduce JobTracker等,有1個或幾個節點充當整個系統的核心元資料及節點管理工作,其他節點都和中心節點互動。這種方式的好處顯而易見,資料和管理高度統一集中在一個地方,容易聚合,就像領導者一樣,其他人都服從就好。簡單可行。
但是缺點是模組高度集中,容易形成效能瓶頸,並且如果出現異常,就像群龍無首一樣。
無中心化的設計,例如cassandra、zookeeper,系統中不存在一個領導者,節點彼此通訊並且彼此合作完成任務。好處在於如果出現異常,不會影響整體系統,區域性不可用。缺點是比較協議複雜,而且需要各個節點間同步資訊。
【分散式系統設計實踐】
基本的理論和策略簡單介紹這麼多,後面本人會從工程的角度,細化說一下”資料分佈“、"副本控制"和"高可用協議"
在分散式系統中,無論是計算還是儲存,處理的物件都是資料,資料不存在於一臺機器或程序中,這就牽扯到如何多機均勻分發資料的問題,此小結主要討論"雜湊取模",”一致性雜湊“,”範圍表劃分“,”資料塊劃分“
1、雜湊取模:
雜湊方式是最常見的資料分佈方式,實現方式是通過可以描述記錄的業務的id或key(比如使用者 id),通過Hash函式的計算求餘。餘數作為處理該資料的伺服器索引編號處理。如圖:
這樣的好處是隻需要通過計算就可以映射出資料和處理節點的關係,不需要儲存對映。難點就是如果id分佈不均勻可能出現計算、儲存傾斜的問題,在某個節點上分佈過重。並且當處理節點宕機時,這種”硬雜湊“的方式會直接導致部分資料異常,還有擴容非常困難,原來的對映關係全部發生變更。
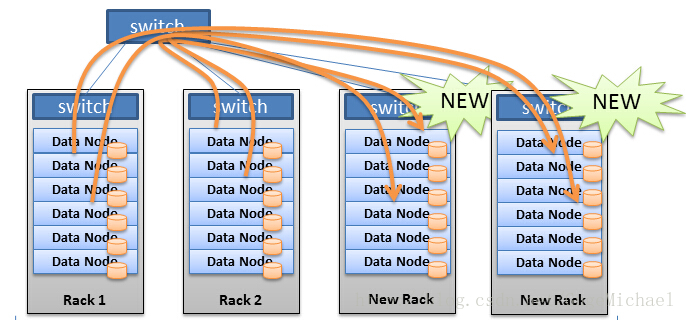
此處,如果是”無狀態“型的節點,影響比較小,但遇到”有狀態“的儲存節點時,會發生大量資料位置需要變更,發生大量資料遷移的問題。這個問題在實際生產中,可以通過按2的冪的機器數,成倍擴容的方式來緩解,如圖:
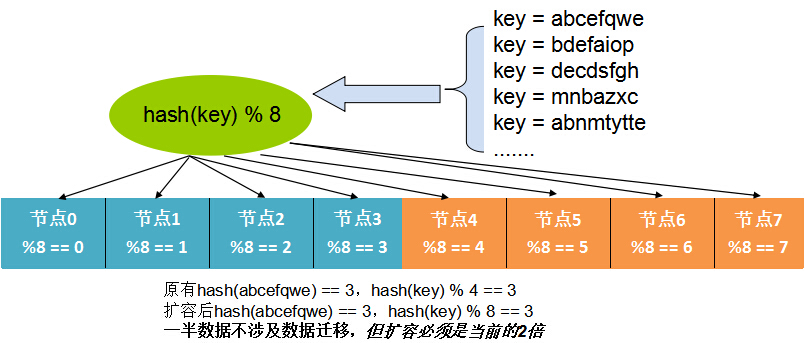
不過擴容的數量和方式後收到很大限制。下面介紹一種”自適應“的方式解決擴容和容災的問題。
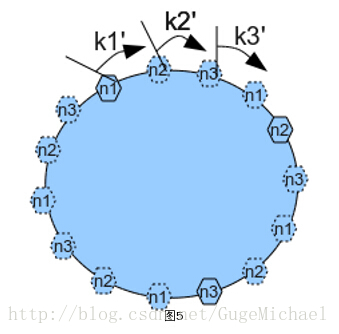
2、一致性雜湊:
一致性雜湊 -- Consistent Hash 是使用一個雜湊函式計算資料或資料特徵的雜湊值,令該雜湊函式的輸出值域為一個封閉的環,最大值+1=最小值。將節點隨機分佈到這個環上,每個節點負責處理從自己開始順時針至下一個節點的全部雜湊值域上的資料,如圖:

################################################3
一致性雜湊的優點在於可以任意動態新增、刪除節點,每次新增、刪除一個節點僅影響一致性雜湊環上相鄰的節點。 為了儘可能均勻的分佈節點和資料,一種常見的改進演算法是引入虛節點的概念,系統會建立許多虛擬節點,個數遠大於當前節點的個數,均勻分佈到一致性雜湊值域環上。讀寫資料時,首先通過資料的雜湊值在環上找到對應的虛節點,然後查詢到對應的real節點。這樣在擴容和容錯時,大量讀寫的壓力會再次被其他部分節點分攤,主要解決了壓力集中的問題。如圖:
3、資料範圍劃分:
有些時候業務的資料id或key分佈不是很均勻,並且讀寫也會呈現聚集的方式。比如某些id的資料量特別大,這時候可以將資料按Group劃分,從業務角度劃分比如id為0~10000,已知8000以上的id可能訪問量特別大,那麼分佈可以劃分為[[0~8000],[8000~9000],[9000~1000]]。將小訪問量的聚集在一起。這樣可以根據真實場景按需劃分,缺點是由於這些資訊不能通過計算獲取,需要引入一個模組儲存這些對映資訊。這就增加了模組依賴,可能會有效能和可用性的額外代價。
4、資料塊劃分:
許多檔案系統經常採用類似設計,將資料按固定塊大小(比如HDFS的64MB),將資料分為一個個大小固定的塊,然後這些塊均勻的分佈在各個節點,這種做法也需要外部節點來儲存對映關係。
由於與具體的資料內容無關,按資料量分佈資料的方式一般沒有資料傾斜的問題,資料總是被均勻切分並分佈到叢集中。當叢集需要重新負載均衡時,只需通過遷移資料塊即可完成。
如圖:
大概說了一下資料分佈的具體實施,後面根據這些分佈,看看工程中各個節點間如何相互配合、管理,一起對外服務。
1、paxos
paxos很多人都聽說過了,這是唯一一個被認可的在工程中證實的強一致性、高可用的去中心化分散式協議。雖然論文裡提到的概念比較複雜,但基本流程不難理解。本人能力有限,這裡只簡單的闡述一下基本原理:
Paxos 協議中,有三類角色:
Proposer:Proposer 可以有多個,Proposer 提出議案,此處定義為value。不同的 Proposer 可以提出不同的甚至矛盾的 value,例如某個 Proposer 提議“將變數a設定為x1” ,另一個 Proposer 提議“將變數a設定為x2” ,但對同一輪 Paxos過程,最多隻有一個 value 被批准。
Acceptor: 批准者。 Acceptor 有 N 個, Proposer 提出的 value 必須獲得超過半數(N/2+1)的 Acceptor批准後才能通過。Acceptor 之間對等獨立。
Learner:學習者。Learner 學習被批准的 value。所謂學習就是通過讀取各個 Proposer 對 value的選擇結果, 如果某個 value 被超過半數 Proposer 通過, 則 Learner 學習到了這個 value。從而學習者需要至少讀取 N/2+1 個 Accpetor,至多讀取 N 個 Acceptor 的結果後,能學習到一個通過的 value。
paxos在開源界裡比較好的實現就是zookeeper(類似Google chubby),zookeeper犧牲了分割槽容忍性,在一半節點宕機情況下,zookeeper就不可用了。可以提供中心化配置管理下發、分散式鎖、選主等訊息佇列等功能。其中前兩者依靠了Lease機制來實現節點存活感知和網路異常檢測。
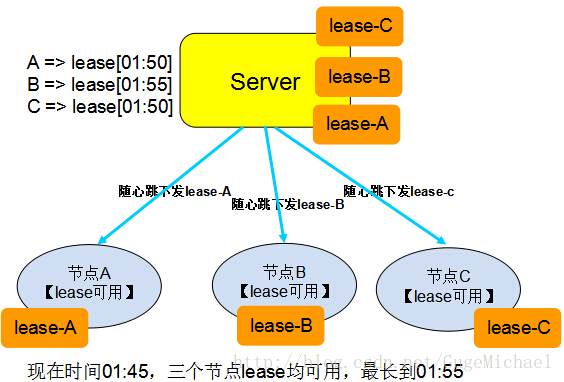
2、Lease機制
Lease英文含義是”租期“、”承諾“。在分散式環境中,此機制描述為:Lease 是由授權者授予的在一段時間內的承諾。授權者一旦發出 lease,則無論接受方是否收到,也無論後續接收方處於何種狀態,只要 lease 不過期,授權者一定遵守承諾,按承諾的時間、內容執行。接收方在有效期內可以使用頒發者的承諾,只要 lease 過期,接
收方放棄授權,不再繼續執行,要重新申請Lease。
如圖:

Lease用法舉例1:
現有一個類似DNS服務的系統,資料的規律是改動很少,大量的讀操作。客戶端從服務端獲取資料,如果每次都去伺服器查詢,則量比較大。可以把資料快取在本地,當資料有變動的時候重新拉取。現在伺服器以lease的形式,把資料和lease一同推送給客戶端,在lease中存放承諾該資料的不變的時間,然後客戶端就可以一直放心的使用這些資料(因為這些資料在伺服器不會發生變更)。如果有客戶端修改了資料,則把這些資料推送給伺服器,伺服器會阻塞一直到已釋出的所有lease都已經超時用完,然後後面傳送資料和lease時,更新現在的資料。
這裡有個優化可以做,當伺服器收到資料更新需要等所有已經下發的lease超時的這段時間,可以直接傳送讓資料和lease失效的指令到客戶端,減小伺服器等待時間,如果不是所有的lease都失效成功,則退化為前面的等待方案(概率小)。
Lease用法舉例2:
現有一個系統,有三個角色,選主模組Manager,唯一的Master,和其他salver節點。slaver都向Maganer註冊自己,並由manager選出唯一的Master節點並告知其他slaver節點。當網路出現異常時,可能是Master和Manager之間的鏈路斷了,Master認為Master已經死掉了,則會再選出一個Master,但是原來的Master對其他網路鏈路可能都還是正常的,原來的Master認為自己還是主節點,繼續服務。這時候系統中就出現了”雙主“,俗稱”腦裂“。
解決這個問題的方式可以通過Lease,來規定節點可以當Master的時間,如果沒有可用的Lease,則自動退化為Slaver。如果出現”雙主“,原Master會因為Lease到期而放棄當Master,退化為Slaver,恢復了一個Master的情況。