
Storm(流計算)技術原理
流計算概述
什麼是流資料:
資料有靜態資料和流資料。
靜態資料:
很多企業為了支援決策分析而構建的資料倉庫系統,其中存放的大量歷史資料就是靜態資料。技術人員可以利用資料探勘和OLAP(On-Line Analytical Processing)分析工具從靜態資料中找到對企業有價值的資訊。
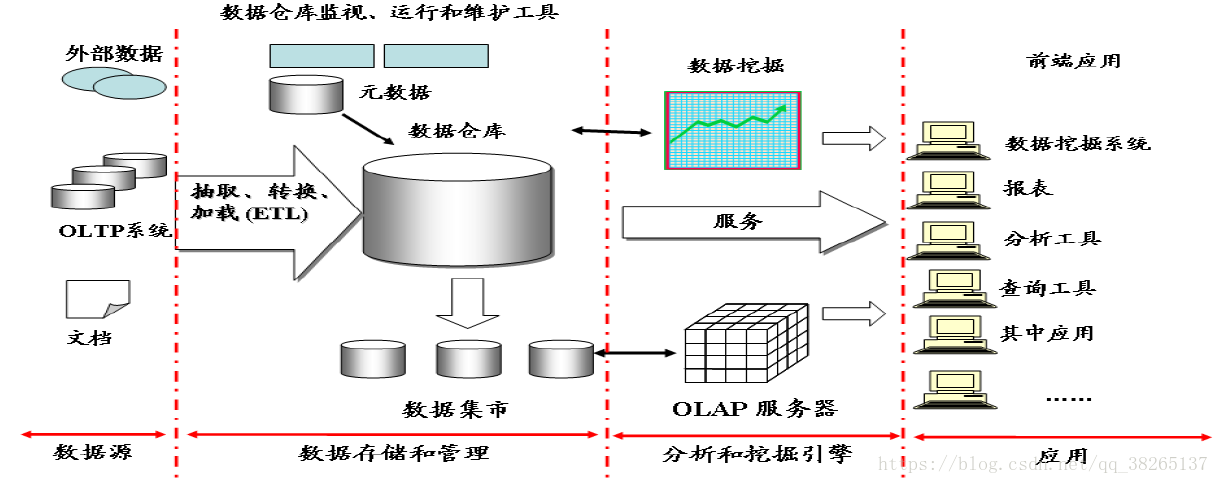
流資料:
近年來,在Web應用、網路監控、感測監測等領域,興起了一種新的資料密集型應用——流資料,即資料以大量、快速、時變的流形式持續到達。
- 例項:PM2.5檢測、電子商務網站使用者點選流
流資料具有如下特徵:
- 資料快速持續到達,潛在大小也許是無窮無盡的。
- 資料來源眾多,格式複雜。
- 資料量大,但是不十分關注儲存,一旦經過處理,要麼被丟棄,要麼被歸檔儲存。
- 注重資料的整體價值,不過分關注個別資料。
- 資料順序顛倒,或者不完整,系統無法控制將要處理的新到達的資料元素的順序。
批量計算和實時計算:
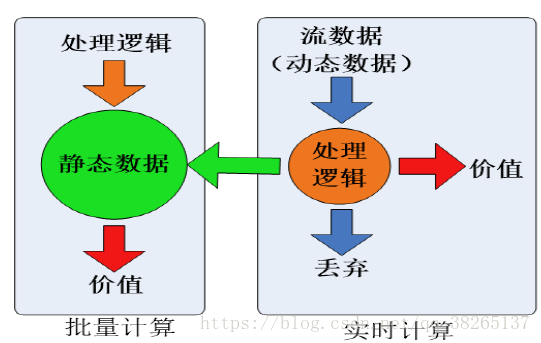
對靜態資料和流資料的處理,對應著兩種截然不同的計算模式:批量計算和實時計算。
- 批量計算:充裕時間處理靜態資料,如Hadoop。
- 流計算:流資料不適合採用批量計算,因為流資料不適合用傳統的關係模型建模。流資料必須採用實時計算,響應時間為秒級。在大資料時代,資料格式複雜、來源眾多、資料量巨大,對實時計算提出了很大的挑戰。因此,針對流資料的實時計算——流計算,應運而生。
流計算的概念:
流計算:實時獲取來自不同資料來源的海量資料,經過實時分析處理,獲得有價值的資訊。

流計算秉承一個基本理念,即資料的價值隨著時間的流逝而降低,如使用者點選流。因此,當事件出現時就應該立即進行處理,而不是快取起來進行批量處理。為了及時處理流資料,就需要一個低延遲、可擴充套件、高可靠的處理引擎.
對於一個流計算系統來說,它應達到如下需求:
- 高效能
- 海量式
- 實時性
- 分散式
- 易用性
- 可靠性
Streaming定義:
Streaming是基於開源Storm,是一個分散式、實時計算框架。
特點:
- 實時響應,低延時。
- 資料不儲存,先計算
- 連續查詢
- 事件驅動
傳統資料庫計算:資料先儲存,在查詢處理。
流計算與Hadoop:
Hadoop設計的初衷是面向大規模資料的批量處理。
MapReduce是專門面向靜態資料的批量處理的,內部各種實現機制都為批處理做了高度優化,不適合用於處理持續到達的動態資料。
可能會想到一種“變通”的方案來降低批處理的時間延遲——將基於MapReduce的批量處理轉為小批量處理,將輸入資料切成小的片段,每隔一個週期就啟動一次MapReduce作業。但這種方式也無法有效處理流資料。
- 切分成小片段,可以降低延遲,但是也增加了附加開銷,還要處理片段之間依賴關係。
- 需要改造MapReduce以支援流式處理。
結論:魚和熊掌不可兼得,Hadoop擅長批處理,不適合流計算。
Streaming在FusionInsight中的位置:

Streaming是一個實時分散式的實時計算框架,在實時業務彙總有廣泛的應用。
流計算框架:
當前業界誕生了許多專門的流資料實時計算系統來滿足各自需求。
商業級:IBM InfoSphere Streams和IBM StreamBase。
開源流計算框架
- Twitter Storm:免費、開源的分散式實時計算系統,可簡單、高效、可靠地處理大量的流資料。
- Yahoo! S4(Simple Scalable Streaming System):開源流計算平臺,是通用的、分散式的、可擴充套件的、分割槽容錯的、可插拔的流式系統。
公司為支援自身業務開發的流計算框架:
- Facebook Puma
- Dstream(百度)
- 銀河流資料處理平臺(淘寶)
流計算的應用:
流計算是針對流資料的實時計算,可以應用在多種場景中。如百度、淘寶等大型網站中,每天都會產生大量流資料,包括使用者的搜尋內容、使用者的瀏覽記錄等資料。採用流計算進行實時資料分析,可以瞭解每個時刻的流量變化情況,甚至可以分析使用者的實時瀏覽軌跡,從而進行實時個性化內容推薦。但是,並不是每個應用場景都需要用到流計算的。流計算適合於需要處理持續到達的流資料、對資料處理有較高實時性要求的場景。
主要應用於以下幾種場景:
- 實時分析:如實時日誌處理、交通流量分析等。
- 實時統計:如網站的實時訪問統計、排序等。
- 實時推薦:如實時的廣告定位、時間營銷等。
流計算處理流程
概述:
傳統的資料處理流程,需要先採集資料並存儲在關係資料庫等資料管理系統中,之後由使用者通過查詢操作和資料管理系統進行互動。
傳統的資料處理流程隱含了兩個前提:
- 儲存的資料是舊的。儲存的靜態資料是過去某一時刻的快照,這些資料在查詢時可能已不具備時效性了。
- 需要使用者主動發出查詢來獲取結果。
流計算的處理流程一般包含三個階段:資料實時採集、資料實時計算、實時查詢服務。
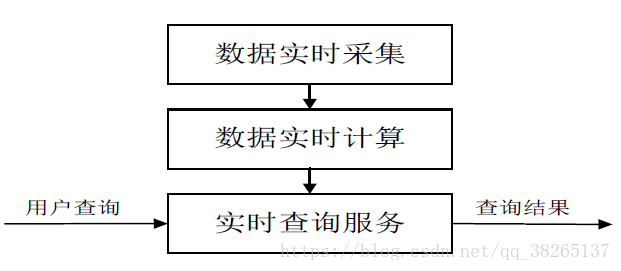
圖:流計算處理流程示意圖
資料實時採集:
資料實時採集階段通常採集多個數據源的海量資料,需要保證實時性、低延遲與穩定可靠。
以日誌資料為例,由於分散式叢集的廣泛應用,資料分散儲存在不同的機器上,因此需要實時彙總來自不同機器上的日誌資料。
目前有許多網際網路公司釋出的開源分散式日誌採集系統均可滿足每秒數百MB的資料採集和傳輸需求,如:
- Facebook的Scribe
- LinkedIn的Kafka
- 淘寶的Time Tunnel
- 基於Hadoop的Chukwa和Flume
資料採集系統的基本架構一般有以下三個部分:

- Agent:主動採集資料,並把資料推送到Collector部分。
- Collector:接收多個Agent的資料,並實現有序、可靠、高效能的轉發。
- Store:儲存Collector轉發過來的資料(對於流計算不儲存資料)。
資料實時計算:
資料實時計算階段對採集的資料進行實時的分析和計算,並反饋實時結果。
經流處理系統處理後的資料,可視情況進行儲存,以便之後再進行分析計算。在時效性要求較高的場景中,處理之後的資料也可以直接丟棄。
實時查詢服務:
實時查詢服務:經由流計算框架得出的結果可供使用者進行實時查詢、展示或儲存。
傳統的資料處理流程,使用者需要主動發出查詢才能獲得想要的結果。而在流處理流程中,實時查詢服務可以不斷更新結果,並將使用者所需的結果實時推送給使用者。
雖然通過對傳統的資料處理系統進行定時查詢,也可以實現不斷地更新結果和結果推送,但通過這樣的方式獲取的結果,仍然是根據過去某一時刻的資料得到的結果,與實時結果有著本質的區別。
可見,流處理系統與傳統的資料處理系統有如下不同:
- 流處理系統處理的是實時的資料,而傳統的資料處理系統處理的是預先儲存好的靜態資料。
- 使用者通過流處理系統獲取的是實時結果,而通過傳統的資料處理系統,獲取的是過去某一時刻的結果。
- 流處理系統無需使用者主動發出查詢,實時查詢服務可以主動將實時結果推送給使用者。
開源流計算框架Storm
Storm簡介:
Twitter Storm是一個免費、開源的分散式實時計算系統,Storm對於實時計算的意義類似於Hadoop對於批處理的意義,Storm可以簡單、高效、可靠地處理流資料,並支援多種程式語言。
Storm框架可以方便地與資料庫系統進行整合,從而開發出強大的實時計算系統。
Twitter是全球訪問量最大的社交網站之一,Twitter開發Storm流處理框架也是為了應對其不斷增長的流資料實時處理需求。
Storm的特點:
Storm可用於許多領域中,如實時分析、線上機器學習、持續計算、遠端RPC、資料提取載入轉換等。
Storm具有以下主要特點:
- 整合性
- 簡易的API
- 可擴充套件性
- 可靠的訊息處理
- 支援各種程式語言
- 快速部署
- 免費、開源
系統架構:
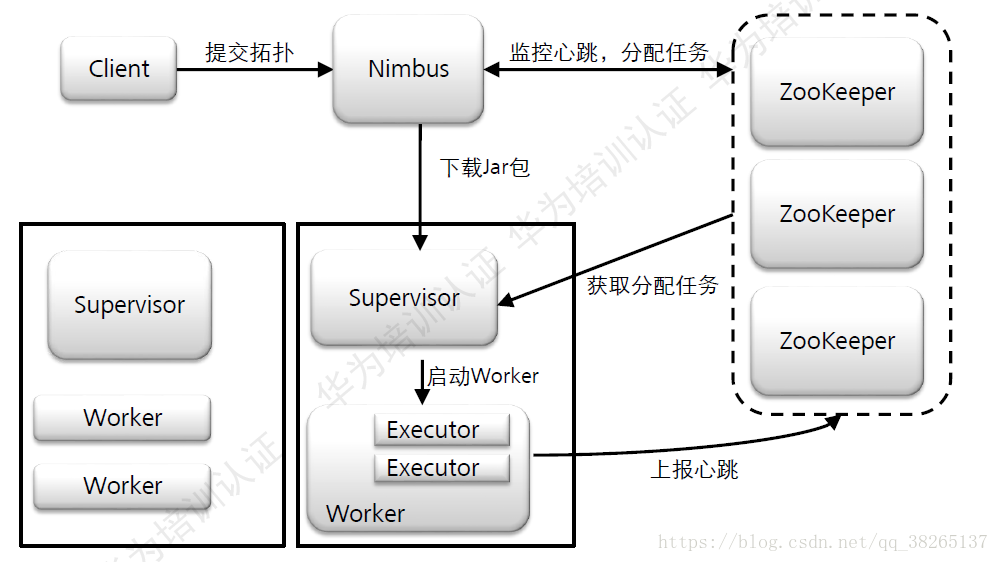
基本概念:
Storm主要術語包括Streams、Spouts、Bolts、Topology和Stream Groupings.
Topology:Streaming中執行的一個實時應用程式。
Nimbus:負責資源分配和任務排程。
Supervisor:負責接收Nimbus分配的任務,啟動和停止屬於自己管理的worker程序。
Worker:Topology執行時的物理程序。每個Worker是一個JVM程序。
Spout:Storm認為每個Stream都有一個源頭,並把這個源頭抽象為Spout。
在一個Topology中產生源資料流的元件。
通常Spout會從外部資料來源(佇列、資料庫等)讀取資料,然後封裝成Tuple形式,傳送到Stream中。Spout是一個主動的角色,在介面內部有個nextTuple函式,Storm框架會不停的呼叫該函式。
Bolt:在一個Topology中接收資料後然後執行處理的元件。
Task:Worker中每一個Spout/Bolt的執行緒稱為一個Task。
Tuple:Streaming的核心資料結構,是訊息傳遞的基本單元,不可變Key-Value對,這些Tuple會以一種分散式的方式程序建立和處理。
Stream:Storm將流資料Stream描述成一個無限的Tuple序列,這些Tuple序列會以分散式的方式並行地建立和處理。即無界的Tuple序列。
Zookeeper:為Streaming服務中各自程序提供分散式的協作服務、主備Nimbus、Supervisor、Worker將自己的資訊註冊到Zookeeper中,Nimbus據此感知各個角色的監控狀態。
Topology介紹:
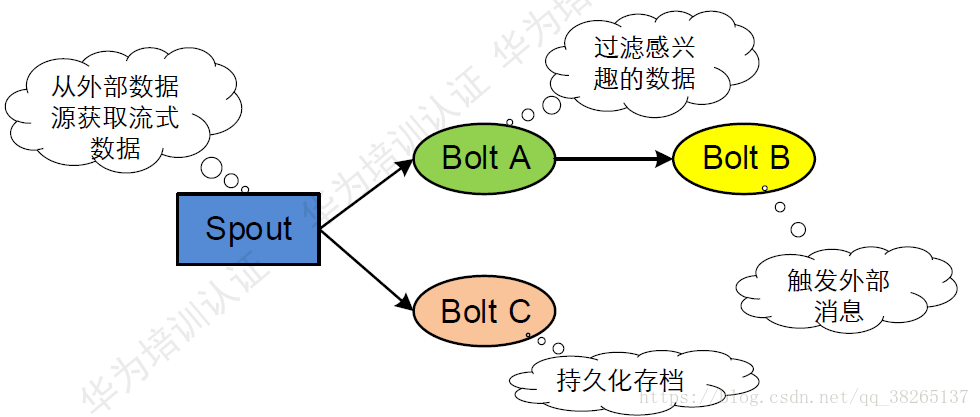
Storm將Spouts和Bolts組成的網路抽象成Topology,它可以被提
交到Storm叢集執行。Topology可視為流轉換圖,圖中節點是一個Spout或Bolt,邊則表示Bolt訂閱了哪個Stream。當Spout或者Bolt傳送元組時,它會把元組傳送到每個訂閱了該Stream的Bolt上進行處理。
Topology裡面的每個處理元件(Spout或Bolt)都包含處理邏輯, 而元件之間的連線則表示資料流動的方向。
Topology裡面的每一個元件都是並行執行的:
在Topology裡面可以指定每個元件的並行度,Storm會在叢集裡面分配那麼多的執行緒來同時計算。
在Topology的具體實現上,Storm中的Topology定義僅僅是一些Thrift結構體(二進位制高效能的通訊中介軟體),支援各種程式語言進行定義。
一個Topology是由一組Spout元件(資料來源)和Bolt元件(邏輯處理)通過Stream Groupings進行連線的有向無環圖(DAG)。
業務處理邏輯被封裝進Streaming中的Topology中。
Worker介紹:
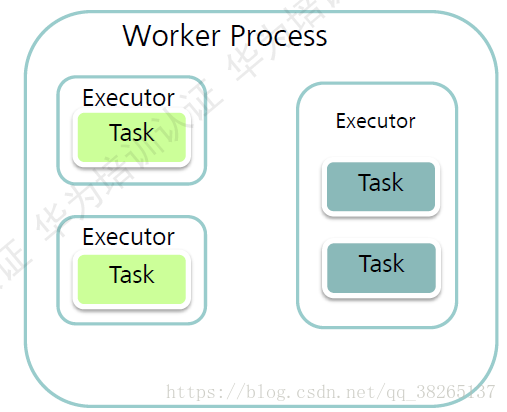
Worker:一個Worker是一個JVM程序,所有的Topology都是在一個或者多個Worker中執行的。Worker啟動後是長期執行的,除非人工停止。Worker程序的個數取決於Topology的設定,且無設定上限,具體可獲得並排程啟動的Worker個數則取決於Supervisor配置的slot個數。
Executor:在一個單獨的Worker程序中會執行一個或多個Executor執行緒。每個Executor只能運Spout或者Bolt中的一個或多個Task例項。
Task:是最終完成資料處理的實體單元。
Task介紹:
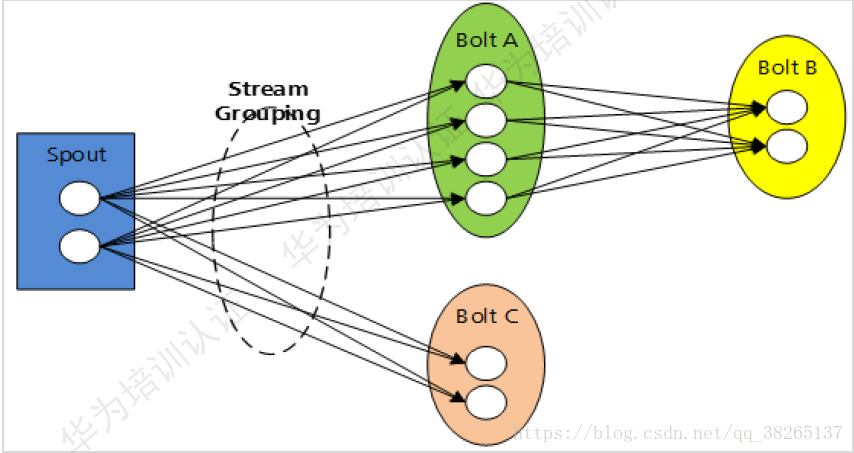
Topology裡面的每一個Component(元件)(Spout/Blot)節點都是並行執行的。在Topology裡面,可以指定每個節點的併發度,Streaming則會在叢集裡分配響應的Task來同時計算,以增強系統的處理能力。
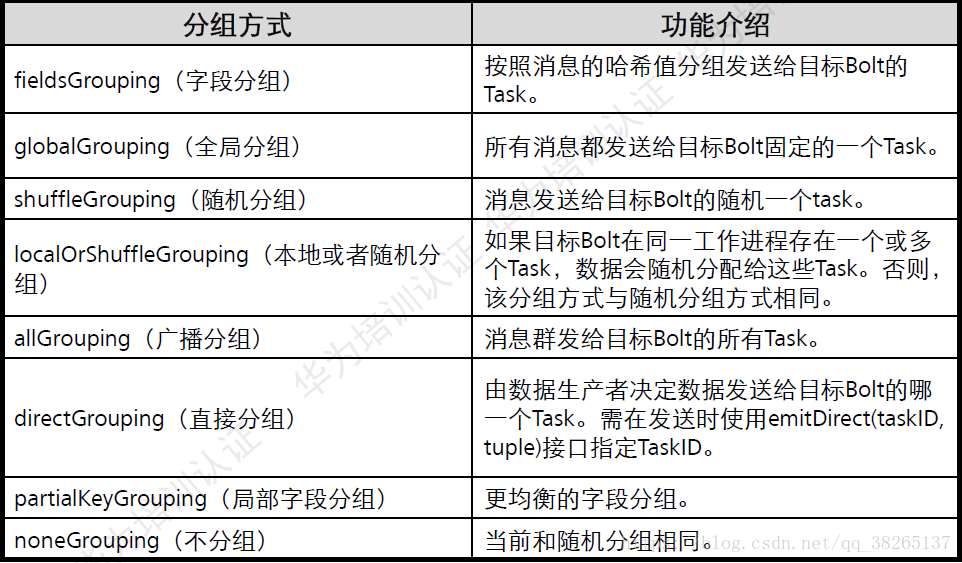
訊息分發策略(Stream Groupings):
Groupings:Storm中的Stream Groupings用於告知Topology如何在兩個元件間(如Spout和Bolt之間,或者不同的Bolt之間)進行Tuple的傳送。每一個Spout和Bolt都可以有多個分散式任務,一個任務在什麼時候、以什麼方式傳送Tuple就是由Stream Groupings來決定的。
目前,Storm中的Stream Groupings有如下幾種方式:
- ShuffleGrouping:隨機分組,隨機分發Stream中的Tuple,保證每個Bolt的Task接收Tuple數量大致一致。
- FieldsGrouping:按照欄位分組,保證相同欄位的Tuple分配到同一個Task中。
- AllGrouping:廣播發送,每一個Task都會收到所有的Tuple。
- GlobalGrouping:全域性分組,所有的Tuple都發送到同一個Task中。
- NonGrouping:不分組,和ShuffleGrouping類似,當前Task的執行會和它的被訂閱者在同一個執行緒中執行。
- DirectGrouping:直接分組,直接指定由某個Task來執行Tuple的處理。
Storm框架設計:
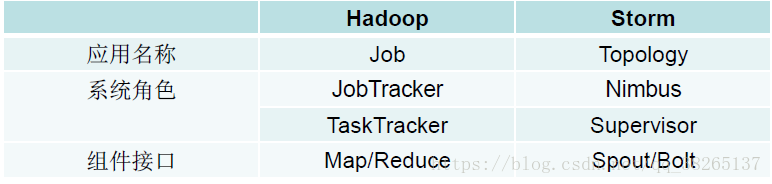
Storm叢集採用“Master—Worker”的節點方式:
Master節點執行名為“Nimbus”的後臺程式(類似Hadoop中的“JobTracker”),負責在叢集範圍內分發程式碼、為Worker分配任務和監測故障。
Worker節點執行名為“Supervisor”的後臺程式,負責監聽分配給它所在機器的工作,即根據Nimbus分配的任務來決定啟動或停止Worker程序,一個Worker節點上同時執行若干個Worker程序。
- Storm使用Zookeeper來作為分散式協調元件,負責Nimbus和多個Supervisor之間的所有協調工作。藉助於Zookeeper,若Nimbus程序或Supervisor程序意外終止,重啟時也能讀取、恢復之前的狀態並繼續工作,使得Storm極其穩定。

Nimbus並不直接和Supervisor交換,而是通過Zookeeper進行訊息的傳遞。
Storm和Hadoop架構元件功能對應關係:
Storm執行任務的方式與Hadoop類似:Hadoop執行的是MapReduce作業,而Storm執行的是“Topology”。
但兩者的任務大不相同,主要的不同是:MapReduce作業最終會完成計算並結束執行,而Topology將持續處理訊息(直到人為終止)。
Storm工作流程:
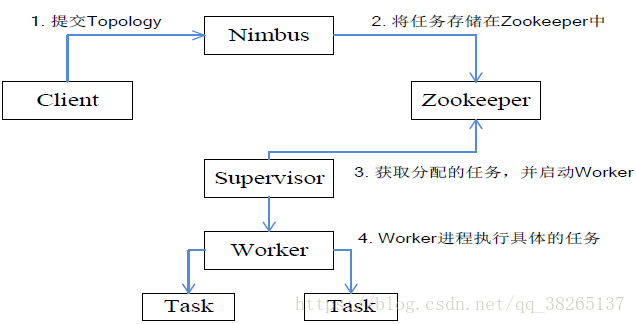
Storm工作流程為:
- 提交Topology
- 將任務儲存在Zookeeper中
- 獲取分配的任務,並啟動Worker
- Worker程序執行具體的任務
所有Topology任務的提交必須在Storm客戶端節點上進行,提交後,由Nimbus節點分配給其他Supervisor節點進行處理。
Nimbus節點首先將提交的Topology進行分片,分成一個個Task,分配給相應的Supervisor,並將Task和Supervisor相關
的資訊提交到Zookeeper叢集上。
Supervisor會去Zookeeper叢集上認領自己的Task,通知自己的Worker程序進行Task的處理。
Streaming提供的介面:
REST介面:(Representational State Transfer)表述性狀態轉移介面。
Thrift介面:由Nimbus提供。Thrift是一個基於靜態程式碼生成的跨語言的RPC協議棧實現,它可以生成包括C++,Java,Python, Ruby , PHP等主流語言的程式碼實現,這些程式碼實現了RPC的協議層和傳輸層功能,從而讓使用者可以集中精力與服務的呼叫和實現。
Streaming的關鍵特性介紹
Nimbus HA:

使用Zookeeper分散式鎖:
Nimbus HA的實現是使用Zookeeper分散式鎖,通過主備間爭搶模式完成的Leader選舉和主備切換。
主備間元資料同步:
主備Nimbus之間會週期性的同步元資料,保證在發生主備切換後拓撲資料不丟失,業務不受損。
容災能力:
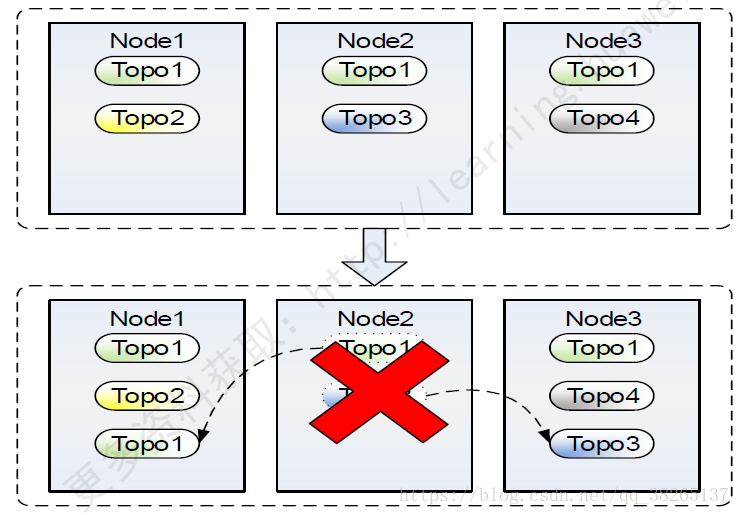
容災能力:節點失效,自動遷移到正常節點,業務不中斷。
整個過程無需人工干預!
訊息可靠性:
在Streaming裡面一個Tuple被完全處理的意思是:這個Tuple所派生的所有tuple都被成功處理。如果這個訊息在Timeout所指定的時間內沒有成功處理,這個tuple就被認為處理失敗了。
可靠性級別設定:
如果並不要求每個訊息必須被處理(允許在處理過程中丟失一些資訊),那麼可以關閉訊息的可靠性處理機制,從而可以獲得較好的效能。關閉訊息的可靠性機制一位著系統中的訊息數會減半。
有三種方法可以關閉訊息的可靠性處理機制:
- 將引數Config.TOPOLGY_ACKERS設定為0.
- Spout傳送一個訊息時,使用不指定訊息message ID的介面進行傳送。
- Blot傳送訊息時使用Unanchor方式傳送,使Tuple樹不往下延伸,從而關閉派生訊息的可靠性。
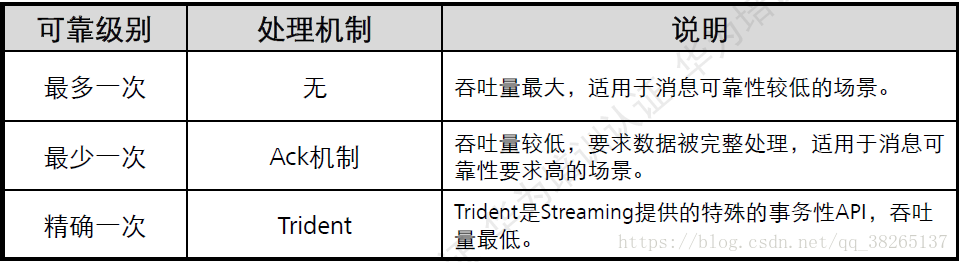
ACK機制:
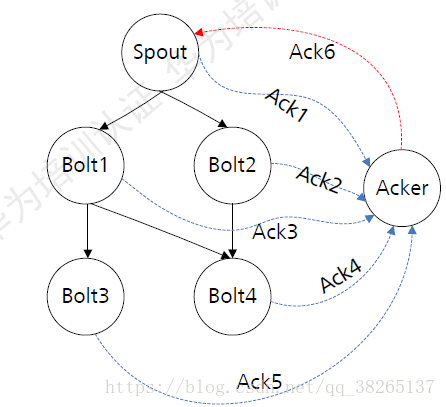
- 一個Spout傳送一個Tuple時,會通知Acker一個新的根訊息產生了,Acker會建立一個新的Tuple tree,並初始化校驗和為0.
- Bolt傳送訊息時間向Acker傳送anchor tuple,重新整理tuple tree,並在傳送成功後向Acker反饋結果。如果成功則重新重新整理校驗和,如果失敗則Acker會立即通知Spout處理失敗。
- 當Tuple tree被完成吹了(校驗和為0),Acker會通知Spout處理成功。
- Spout提供ack()和Fail()介面方法使用者處理Acker的反饋結果,需要使用者實現。一般在fail()方法中實現訊息重發邏輯。
Streaming與其他元件:
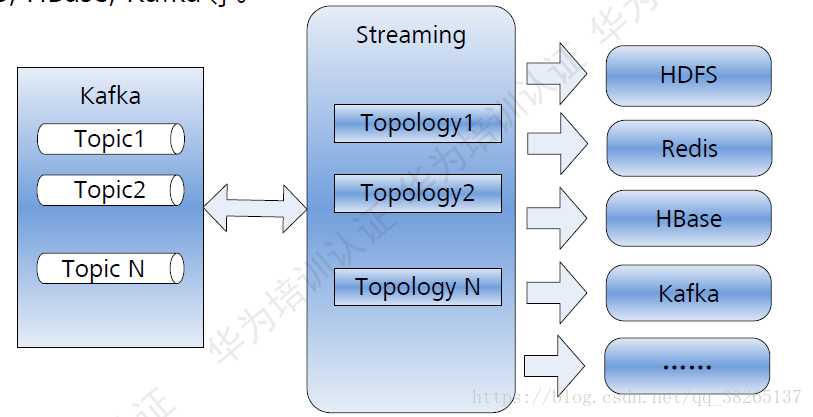
整合HDFS/HBase等外部元件,將實時結構提供給其他元件,程序離線分析。
Spark Streaming
Spark Streaming設計:
Spark Streaming可整合多種輸入資料來源,如Kafka、Flume、
HDFS,甚至是普通的TCP套接字。經處理後的資料可儲存至檔案
系統、資料庫,或顯示在儀表盤裡。

Spark Streaming的基本原理是將實時輸入資料流以時間片(秒級)為單位進行拆分,然後經Spark引擎以類似批處理的方式處理每個時間片資料。

Spark Streaming最主要的抽象是DStream(Discretized Stream,離散化資料流),表示連續不斷的資料流。在內部實現上,Spark Streaming的輸入資料按照時間片(如1秒)分成一段一段的DStream,每一段資料轉換為Spark中的RDD,並且對DStream的操作都最終轉變為對相應的RDD的操作。

Spark Streaming 與 Storm的對比:
- Spark Streaming和Storm最大的區別在於,Spark Streaming無法實現毫秒級的流計算,而Storm可以實現毫秒級響應。
- Spark Streaming構建在Spark上,一方面是因為Spark的低延遲執行引擎(100ms+)可以用於實時計算,另一方面,相比於Storm,RDD資料集更容易做高效的容錯處理。
- Spark Streaming採用的小批量處理的方式使得它可以同時相容批量和實時資料處理的邏輯和演算法,因此,方便了一些需要歷史資料和實時資料聯合分析的特定應用場合。
Samza技術原理
基本概念:
(1)作業:一個作業(Job)是對一組輸入流進行處理轉化成輸出流的程式。
(2)分割槽:
- Samza的流資料單位既不是Storm中的元組,也不是Spark Streaming中的DStream,而是一條條訊息。
- Samza中的每個流都被分割成一個或多個分割槽,對於流裡的每一個分割槽而言,都是一個有序的訊息序列,後續到達的訊息會根據一定規則被追加到其中一個分割槽裡。
(3)任務:
- 一個作業會被進一步分割成多個任務(Task)來執行,其中,每個任務負責處理作業中的一個分割槽。
- 分割槽之間沒有定義順序,從而允許每一個任務獨立執行。
- YARN排程器負責把任務分發給各個機器,最終,一個工作中的多個任務會被分發到多個機器進行分散式並行處理。
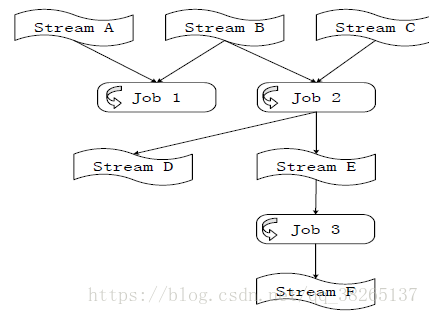
(4)資料流圖:
- 一個數據流圖是由多個作業構成的,其中,圖中的每個節點表示包含資料的流,每條邊表示資料傳輸。
- 多個作業串聯起來就完成了流式的資料處理流程。
- 由於採用了非同步的訊息訂閱分發機制,不同任務之間可以獨立執行。
Samza的系統架構:
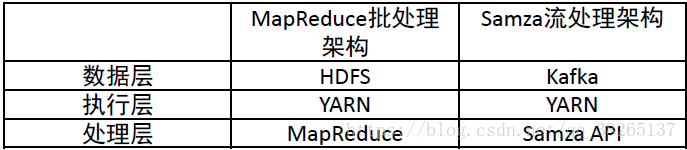
Samza系統架構主要包括:
- 流資料層(Kafka)
- 執行層(YARN)
- 處理層(Samza API)
流處理層和執行層都被設計成可插拔的,開發人員可以使用其他框架來替代YARN和Kafka。
處理分析過程:
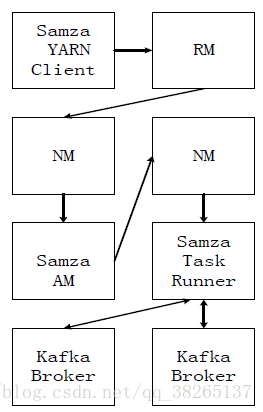
處理分析過程如下:
- Samza客戶端需要執行一個Samza作業時,它會向YARN的ResouceManager提交作業請求。
- ResouceManager通過與NodeManager溝通為該作業分配容器(包含了CPU、記憶體等資源)來執行Samza ApplicationMaster。
- Samza ApplicationMaster進一步向ResourceManager申請執行任務的容器。
- 獲得容器後,Samza ApplicationMaster與容器所在的NodeManager溝通,啟動該容器,並在其中執行Samza Task Runner。
- Samza Task Runner負責執行具體的Samza任務,完成流資料處理分析。
Storm、Spark Streaming和Samza的應用場景
從程式設計的靈活性來講,Storm是比較理想的選擇,它使用Apache Thrift,可以用任何程式語言來編寫拓撲結構(Topology)。
當需要在一個叢集中把流計算和圖計算、機器學習、SQL查詢分析等進行結合時,可以選擇Spark Streaming,因為,在Spark上可以統一部署Spark SQL,Spark Streaming、MLlib,GraphX等元件,提供便捷的一體化程式設計模型。
當有大量的狀態需要處理時,比如每個分割槽都有數十億個元組,則可以選擇Samza。當應用場景需要毫秒級響應時,可以選擇Storm和Samza,因為Spark Streaming無法實現毫秒級的流計算。