
Storm實時流計算原理概述與最佳入門實踐
隨著網際網路的發展,資訊量爆炸式的增長,人們越來越需要實時獲取一些計算資訊,離線計算已經不能滿足了人們的需求,這時Storm、Flink、Spark Streaming等實時計算框架日益發展起來。本篇文章主要講述Storm原理架構概述以及入門實踐案例的編寫。
一、Storm架構原理概述
1.Storm的優點
- Storm是一款開源免費的分散式,可容錯性,可擴充套件、高可靠的實時流處理框架,它可以實時處理無界的流資料,並且支援多種程式語言的開發。
- Storm涉及領域廣泛,比如實時資料分析,機器學習,持續計算,分散式RPC,ETL資料處理等方面。
2. Storm核心元件
Storm 主要有以下概念:
- Spout 產生資料來源的地方。
- Bolt 訊息處理者。
- Topology 網路拓撲。
- Stream 流。
- Tuple 元組。
- Stream 訊息流。
- Streaming Group訊息流組。
Spout訊息源
正如上圖所示,Spout訊息源就像一個水龍頭,源源不斷的產生資料,ISpout是一個介面,主要有以下方法:
public interface ISpout extends Serializable {
//例項化Spout,主要是一些叢集配置
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
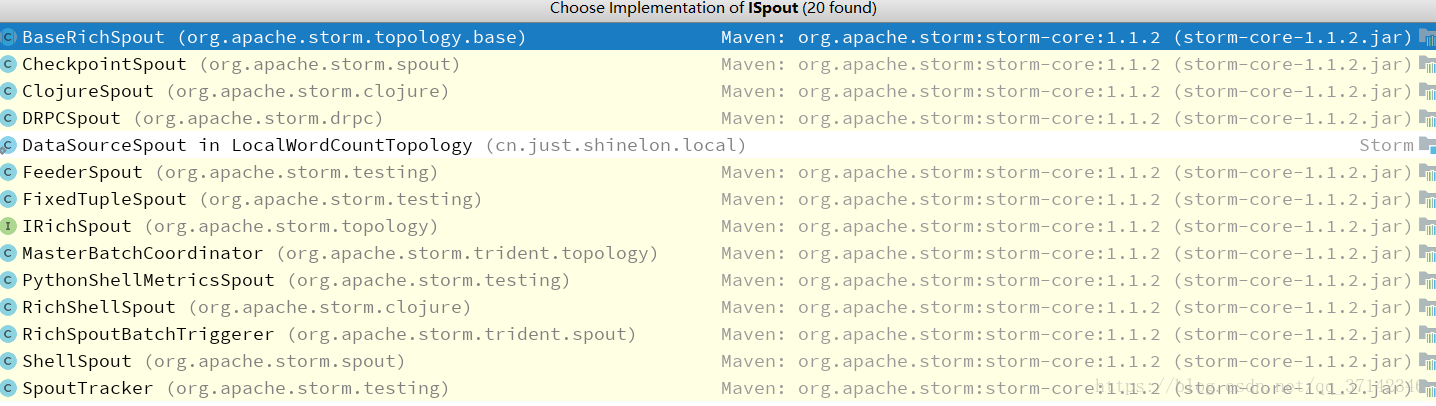
//關閉Spout,Storm並不保證關閉,可以通過kill -9的方式顯示殺死 在我們的應用程式中編寫Spout需要實現ISpout介面,一般情況下,我們並不會直接實現ISpout介面,而是整合它的抽象類BaseRichSpout,該抽象類覆蓋了ISpout介面的這幾個方法,繼承BaseRichSpout抽象類的好處是我們可以自由的按照我們的需求編寫程式,而不需實現全部方法,ISpout介面有很多實現類和子介面:
BaseRichSpout抽象類實現了ISpout介面,集成了BaseCompont介面,而BaseCompont實現了IComponent介面,因此,該抽象類總共實現了ISpout介面和IComponent介面,實現了更加豐富的功能,原始碼如下所示:
public abstract class BaseRichSpout extends BaseComponent implements IRichSpout {
@Override
public void close() {
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public void ack(Object msgId) {
}
@Override
public void fail(Object msgId) {
}
}Bolt訊息處理者
Bolt以Tuple元組資料作為輸入資料,經過處理之後產生一個新的資料輸出。IBolt是一個介面,實現了和ISpout類似的方法,原始碼如下:
public interface IBolt extends Serializable {
//初始化bolt
void prepare(Map stormConf, TopologyContext context, OutputCollector collector);
//實現邏輯處理
void execute(Tuple input);
void cleanup();
}同樣,我們在編寫應用程式的時候整合BaseRichBolt抽象類,它實現了IBolt介面和IComponent介面,其原始碼如下所示:
public abstract class BaseRichBolt extends BaseComponent implements IRichBolt {
@Override
public void cleanup() {
}
}Topology網路拓撲
如果說Stream流資料,Spout,Bolt是流計算的血肉,那麼Topology就是流計算的骨架,它將所有的Spout和Bolt組織在一起,構成了一套實時流處理架構。
Topology的執行有兩種模式,即Storm執行有兩種模式,本地模式和叢集模式。
本地模式,主要用於我們開發測試應用程式來用,可以通過 LocalCluster來建立一個叢集,例如使用如下程式碼建立本地模式提交任務:
LocalCluster localCluster=new LocalCluster();
localCluster.submitTopology("LocalSumTopology",new Config(),builder.createTopology());叢集模式,用於生產線上使用,我們可以定義一個Topology,然後使用 StormSubmitter來提交任務,如下例所示:
Config conf = new Config();
conf.setNumWorkers(20);
conf.setMaxSpoutPending(5000);
StormSubmitter.submitTopology("mytopology", conf, topology);Stream訊息流
它是一個抽象的概念,是一個無界的 Tuple 序列,這些 Tuple 以分散式的方式來並行的建立和處理。
Tuple元組
Tuple是Storm中最基本的資料處理單元,是一個值列表,可以支援任何型別的資料,如果自定義型別的話需要進行序列化。
Stream Grouping訊息流組
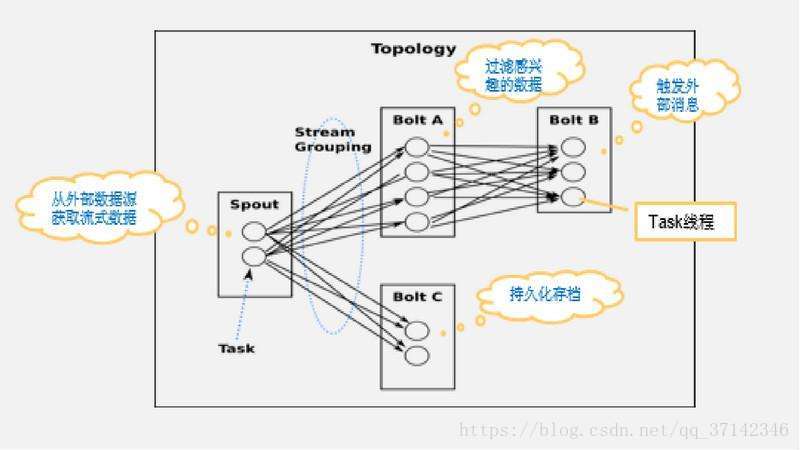
如上圖所示,Stream Grouping主要是定義Bolt處理由Spout發射的何種資料,比如按照某個欄位分組等等,主要有以下分組策略:
- 隨機分組(Shuffle Grouping):隨機分發到Bolt的各個任務中,保證每個任務獲取相同數量的元組。
- 欄位分組(Fields Grouping):根據指定 欄位分割資料流並分組。
- 區域性Key分組(Partial Key Grouping):和Feilds Grouping一樣指定Key傳送資料,但是它會將資料負載均衡的傳送給下游的資料,可以提供更好的資源利用率當發生資料傾斜的時候
- 全部分組(All Grouping):對於每一個Tuple,所有的Bolt都會收到。
- 全域性分組(Global Grouping):全部的流分配到一個Bolt的同一個任務中,即分配給ID最小的Task。
- 無分組(None Grouping):等效於隨機分組。
- 直接分組(Direct Grouping):即元組生產者決定有哪一個消費者消費資料,Spout必須使用emitDirect方法直接發射。
- 本地/隨機分組(Local or shuffle grouping):如果目標Bolt有一個或者多個task在相同的Worker程序中,task則會只發送到處理這些task的Worker程序中,否則和Shuffle Grouping一樣隨機分發。
3.Strom叢集架構
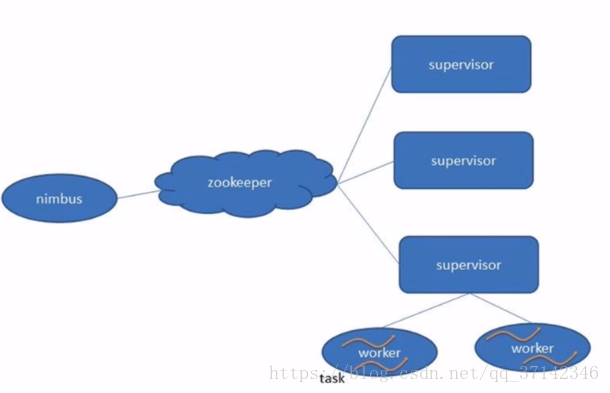
Strom使用Zookeeper作為協調框架,主要由nimbus,supervisor,worker等元件組成。它們三者之間主要有以下關係:
nimbus為主節點,supervisor為從節點,在Surpervisor中可以啟動多個Worker程序,每一個Wroker程序為一個特定的Topology服務,一個Topology可以建立在多個Wroker程序之上,在一個Worker中可以啟動多個Executor執行緒,在executor中可以啟動多個task任務。一般情況下,Executor要麼全部是Spout的task,要麼全部是Bolt的task,也就是說一個Executor只能執行一個Spout或者Bolt的task任務。
二、簡單案例編寫
下面主要編寫一個求和案例,Spout端不斷的輸入資料,從1,2,3,,,n,Bolt端接收資料進行累加計算,最後在控制檯列印,首先匯入maven依賴:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>程式程式碼如下:
/**
* 實現簡單的本地求和功能
*/
public class LocalSumTopology {
/**
* Spout元件
* 產生資料並且傳送
*/
public static class SumSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
/**
* 初始化操作
* @param conf 初始化配置項
* @param context 上下文
* @param collector 資料發射器
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
int number=0;
/**
* 發射資料
* 該方法是一個死迴圈
*/
@Override
public void nextTuple() {
//Values類實現了ArrayList
collector.emit(new Values(++number));
System.out.println("Spout number: "+number);
//防止資料產生太快,睡眠一秒
Utils.sleep(1000);
}
/**
* 定義輸出端欄位
* @param declarer
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//與上面的number變數對應
declarer.declare(new Fields("num"));
}
}
/**
* Bolt元件
* 實現業務的邏輯處理,這裡求和
*/
public static class SumBolt extends BaseRichBolt{
/**
* 因為 這裡接收資料之後不需要再發送給下一個Bolt,因此再初始化collector發射器
* @param stormConf
* @param context
* @param collector
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum=0;
/**
* 執行業務邏輯的處理
* 該方法也是一個死迴圈
* @param input
*/
@Override
public void execute(Tuple input) {
//可以通過欄位名或者下標索引獲取
Integer value=input.getIntegerByField("num");
sum+=value;
System.out.println("Bolt sum: "+sum);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
//使用TopologyBuilder設定Spout和Bolt,並且將其關聯 在一起
//建立Topology
TopologyBuilder builder=new TopologyBuilder();
builder.setSpout("SumSpout",new SumSpout());
builder.setBolt("SumBolt",new SumBolt()).shuffleGrouping("SumSpout");
//使用本地模式
LocalCluster localCluster=new LocalCluster();
localCluster.submitTopology("LocalSumTopology",new Config(),builder.createTopology());
}
}如果想在叢集中提交該應用程式,只需要將程式中的本地模式使用StormSubmitter改為叢集模式,使用下面命令提交即可:
storm jar test.jar main.java args