
感知機模型(原始形式和對偶形式)
本篇部落格主要介紹機器學習中十分基礎的感知機模型。感知機模型是二類分類的線性分類模型,其輸入為例項的特徵向量,輸出為例項的類別。我們寫出基於誤分類的損失函式,利用梯度下降法對損失函式進行極小化,求得感知機模型。
1.首先,我們假定線性方程 wx+b=0 是一個超平面,令 g(x)=wx+b,也就是超平面上的點x都滿足g(x)=0。對於超平面的一側的點滿足:g(x)>0; 同樣的,對於超平面另一側的點滿足:g(x)<0.
結論一:對於不在超平面上的點x,它到超平面的距離:

證明:如下圖所示,O表示原點,Xp表示超平面上的一點,X是超平面外的一點,w是超平面的法向量。





等式1說明:向量的基本運演算法則,OX=OXp+XpX. 因為w是法向量,所以w/||w||是垂直於超平面的單位向量。
等式2說明:將等式1帶入g(x)=wx+b;由於Xp在超平面上,所以g(Xp)=w^T*Xp+w0 = 0
以上得證。
2.下面區分一下易混淆的兩個概念,梯度下降和隨機梯度下降:
梯度下降:一次將誤分類集合中所有誤分類點的梯度下降;
隨機梯度下降:隨機選取一個誤分類點使其梯度下降。
3.對於誤分類的資料來說,當w*xi + b>0時,yi = -1,也就是,明明是正例,預測成負例。因此,誤分類點到超平面的距離為:
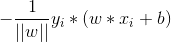
因此所有誤分類點到超平面的總距離為:

忽略1/||w||,我們就可以得到感知機學習的損失函式。
損失函式:

這個損失函式就是感知機學習的經驗風險函式。
下面我們計算損失函式的梯度:

值得我們注意的是,以上求和都是針對誤分類集合M中的樣本點進行的。對於正確分類的樣本點,則不需要考慮。
下面我們就得到了我們的更新策略:
隨機選取誤分類點(xi,yi),對w,b進行更新:

4.感知器演算法的原始形式:
輸出w,b; 感知機模型f(x)=sign(w*x+b)
(1)選取初值w0,b0
(2)在訓練集中選取資料(xi,yi)
(3)若yi*(w*xi+b)<=0, (該樣本點被誤分類了)

(4)轉至(2),直至訓練集中沒有誤分類點。
對於感知器演算法,還有一種對偶形式,其基本想法是將w,b表示為例項xi,和標記yi的線性組合的形式,通過求解其係數而求得w,b
將Ni表示為樣本點(xi,yi)在更新過程中使用的次數,我們可以得到以下式子:

這樣的話,我們可以看出對偶形式本質上是學習Ni,而非w與b,即學習每個樣本在更新過程中使用的次數。
我們可以假設:
對偶形式的一般性描述:
輸出Ni,b; 感知機模型為:

(1)Ni = 0
(2)在訓練集中選取資料(xi,yi)
(3)若

則更新:

(4)轉至(2)直到沒有誤分類的資料
為了方便後期的計算,可先求出Gram矩陣。

例如,正例:x1 = (3,3)^T, x2 = (4,3)^T, 負例: x3 = (1,1)^T
那麼Gram矩陣就是:
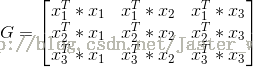

因為對偶形式中會大量用到xi*xj的值,所以提前求出Gram矩陣會方便很多。