
排序演算法大雜燴(概念、複雜度、程式碼實現、應用例項)
大部分內容來自於“一畫素”以及其他的網上資訊。待完善(關於不同版本程式碼的實現以及應用例項)
目錄:
一、常見演算法分類
二、演算法複雜度
三、相關概念
四、演算法詳情以及程式碼實現
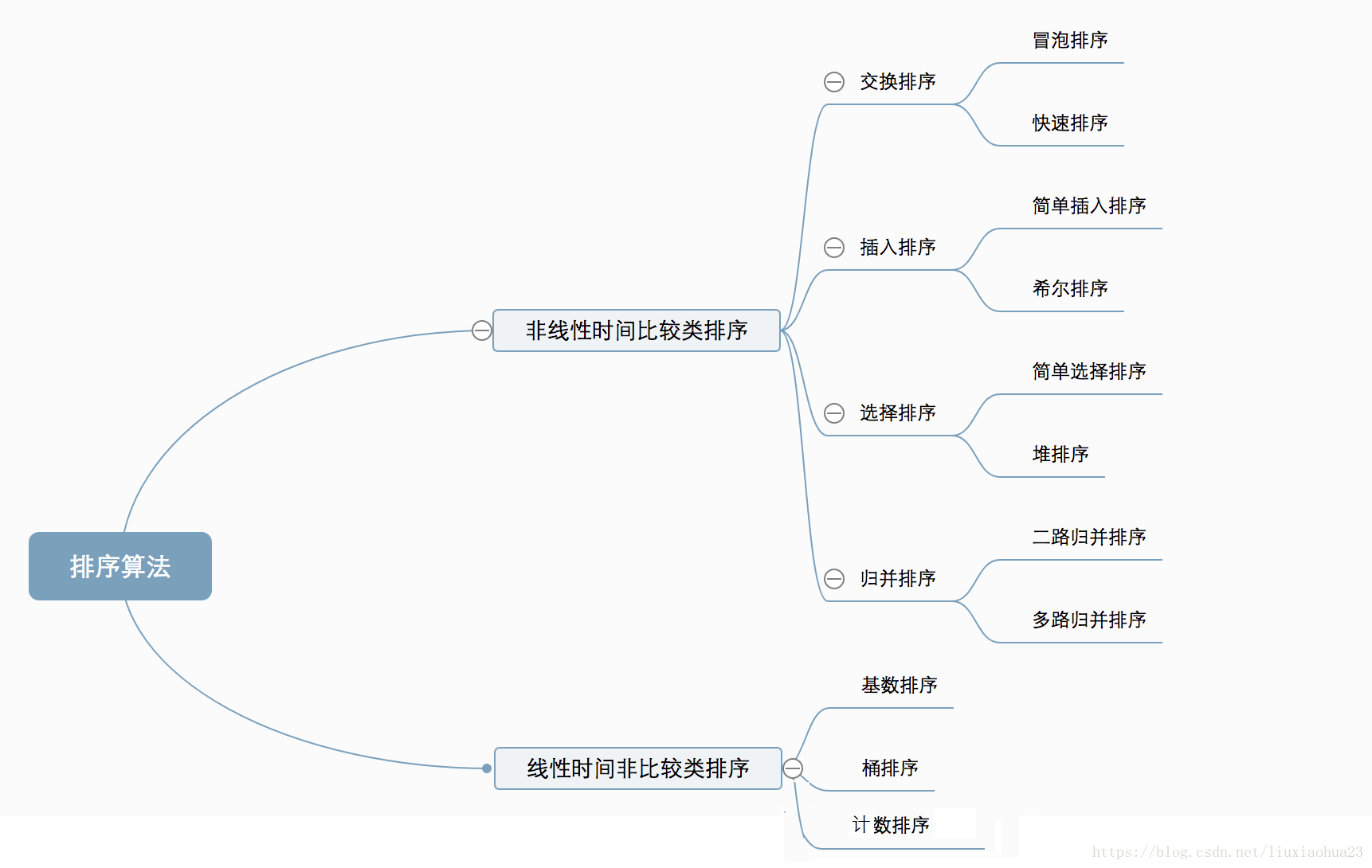
一、 常見的排序演算法可分為兩類
非線性時間比較類排序:通過比較來決定元素間的相對次序,由於其時間複雜度不能突破O(nlogn),因此稱為非線性時間比較類排序。
線性時間非比較類排序:不通過比較來決定元素間的相對次序,它可以突破基於比較排序的時間下界,以線性時間執行,因此稱為線性時間非比較類排序。
二、 複雜度比較

三、 相關概念
穩定:如果a原本在b前面,而a=b,排序之後a仍然在b的前面。
不穩定:如果a原本在b的前面,而a=b,排序之後 a 可能會出現在 b 的後面。
時間複雜度:對排序資料的總的操作次數。反映當n變化時,操作次數呈現什麼規律。
空間複雜度:是指演算法在計算機內執行時所需儲存空間的度量,它也是資料規模n的函式
四、 演算法詳情--非線性時間比較演算法
交換排序: 氣泡排序 與 快速排序
4.1 氣泡排序
定義(描述):
它重複地走訪過要排序的數列,一次比較兩個元素,如果它們的順序錯誤就把它們交換過來。走訪數列的工作是重複地進行直到沒有再需要交換,也就是說該數列已經排序完成。這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端。
演算法:
- 比較相鄰的元素。如果第一個比第二個大,就交換它們兩個;
- 對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最後一對,這樣在最後的元素應該會是最大的數;
- 針對所有的元素重複以上的步驟,除了最後一個;
- 重複步驟1~3,直到排序完成。
動畫演示:

程式碼實現(待完善):
C++版本
//氣泡排序 void bubbleSort(int arr[], int n) { for(int i = 0;i < n;i++){ //比較兩個相鄰的元素 for(int j = 0;j < n-i-1;j++){ if(arr[j] > arr[j+1]){ int t = arr[j]; arr[j] = arr[j+1]; arr[j+1] = t; } } } }
Python版本
MATLAB 版本
4.2 快速排序
定義:
其思想是:先選一個“標尺”,用它把整個佇列過一遍篩子, 以保證,其左邊的元素都不大於它,其右邊的元素都不小於它。這樣,排序問題就被分割為兩個子區間,再分別對子區間排序就可以了。
演算法:
快速排序使用分治法來把一個串(list)分為兩個子串(sub-lists)。具體演算法描述如下:
從數列中挑出一個元素,稱為 “基準”(pivot);
重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的後面(相同的數可以到任一邊)。在這個分割槽退出之後,該基準就處於數列的中間位置。這個稱為分割槽(partition)操作;
遞迴地(recursive)把小於基準值元素的子數列和大於基準值元素的子數列排序。
動畫演示:

程式碼實現:
C++版本
//快速排序
void quickSort(int *arr,int l,int r)
{
//此處編寫程式碼實現快速排序
int i,j,x,temp;
if(l<r)
{
i=l;
j=r;
x=arr[(l+r)/2];
//以中間元素為軸
while(1)
{
while(i<=r&&arr[i]<x)
i++;
while(j>=0&&arr[j]>x)
j--;
if(i>=j) //相遇則跳出
break;
else
{
temp=arr[i];
arr[i]=arr[j];
arr[j]=temp;
//交換
}
}
quickSort(arr,l,i-1); //對左半部分進行快排
quickSort(arr,j+1,r); //對右半部分進行快排
}
}冒泡與快排異同:
插入排序:簡單插入 與 希爾排序
4.3 簡單插入排序
定義:
插入排序(Insertion-Sort)的演算法描述是一種簡單直觀的排序演算法。它的工作原理是通過構建有序序列,對於未排序資料,在已排序序列中從後向前掃描,找到相應位置並插入。
演算法描述:
- 從第一個元素開始,該元素可以認為已經被排序;
- 取出下一個元素,在已經排序的元素序列中從後向前掃描;
- 如果該元素(已排序)大於新元素,將該元素移到下一位置;
- 重複步驟3,直到找到已排序的元素小於或者等於新元素的位置;
- 將新元素插入到該位置後;
- 重複步驟2~5。
動畫演示:

程式碼實現:
C++版本
//插入排序
void insertSort(int arr[], int n){
for(int i = 1;i < n;i++){
int temp = arr[i];
int j = i - 1;
while(temp < arr[j]){
arr[j+1] = arr[j];
j--;
if(j == -1){
break;
}
}
arr[j+1] = temp;
}
} 4.4 希爾排序
定義:
1959年Shell發明,第一個突破O(n2)的排序演算法,是簡單插入排序的改進版。它與插入排序的不同之處在於,它會優先比較距離較遠的元素。希爾排序又叫縮小增量排序。
演算法描述:
選擇一個增量序列t1,t2,…,tk,其中ti>tj,tk=1;
按增量序列個數k,對序列進行k 趟排序;
每趟排序,根據對應的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進行直接插入排序。僅增量因子為1 時,整個序列作為一個表來處理,表長度即為整個序列的長度。
動畫演示:

程式碼實現:
C++版本
// 希爾排序
void Shellsort(int a[], int n) {
int i, j, gap;
for (gap = n / 2; gap > 0; gap /= 2)
{
//for (i = 0; i < gap; i++)
for (i = gap; i < n; i++)
{
for (j = i - gap; j >= 0; j -= gap)
{
if (a[j + gap] < a[j])
swap(a[j + gap], a[j]);
}
}
}
}異同:
選擇排序:簡單選擇 與 堆排序
4.5 簡單選擇排序
定義:
選擇排序(Selection-sort)是一種簡單直觀的排序演算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然後,再從剩餘未排序元素中繼續尋找最小(大)元素,然後放到已排序序列的末尾。以此類推,直到所有元素均排序完畢。
演算法描述:
- 初始狀態:無序區為R[1..n],有序區為空;
- 第i趟排序(i=1,2,3…n-1)開始時,當前有序區和無序區分別為R[1..i-1]和R(i..n)。該趟排序從當前無序區中-選出關鍵字最小的記錄 R[k],將它與無序區的第1個記錄R交換,使R[1..i]和R[i+1..n)分別變為記錄個數增加1個的新有序區和記錄個數減少1個的新無序區;
- n-1趟結束,陣列有序化了。
動畫演示:

程式碼實現:
C++版本
//選擇排序
void choiceSort(int arr[], int n){
for(int i = 0;i < n; i++){
int m = i;
for(int j = i + 1;j < n;j++){
//如果第j個元素比第m個元素小,將j賦值給m
if(arr[j] < arr[m]){
m = j;
}
}
//交換m和i兩個元素的位置
if(i != m){
int t = arr[i];
arr[i] = arr[m];
arr[m] = t;
}
}
}4.6 堆排序
定義:
堆排序(Heapsort)是指利用堆這種資料結構所設計的一種排序演算法。堆積是一個近似完全二叉樹的結構,並同時滿足堆積的性質:即子結點的鍵值或索引總是小於(或者大於)它的父節點。
演算法描述:
- 將初始待排序關鍵字序列(R1,R2….Rn)構建成大頂堆,此堆為初始的無序區;
- 將堆頂元素R[1]與最後一個元素R[n]交換,此時得到新的無序區(R1,R2,……Rn-1)和新的有序區(Rn),且滿足R[1,2…n-1]<=R[n];
- 由於交換後新的堆頂R[1]可能違反堆的性質,因此需要對當前無序區(R1,R2,……Rn-1)調整為新堆,然後再次將R[1]與無序區最後一個元素交換,得到新的無序區(R1,R2….Rn-2)和新的有序區(Rn-1,Rn)。不斷重複此過程直到有序區的元素個數為n-1,則整個排序過程完成。
動畫演示:

程式碼實現:
C++版本
//堆排序
void Heapify(int arr[], int first, int end){
int father = first;
int son = father * 2 + 1;
while(son < end){
if(son + 1 < end && arr[son] < arr[son+1]) ++son;
//如果父節點大於子節點則表示調整完畢
if(arr[father] > arr[son]) break;
else {
//不然就交換父節點和子節點的元素
int temp = arr[father];
arr[father] = arr[son];
arr[son] = temp;
//父和子節點變成下一個要比較的位置
father = son;
son = 2 * father + 1;
}
}
}
void HeapSort(int arr[],int len){
int i;
//初始化堆,從最後一個父節點開始
for(i = len/2 - 1; i >= 0; --i){
Heapify(arr,i,len);
}
//從堆中的取出最大的元素再調整堆
for(i = len - 1;i > 0;--i){
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
//調整成堆
Heapify(arr,0,i);
}
}異同:
歸併排序:二歸併排序 與 多路排序
4.7 二歸併排序
定義:
歸併排序是建立在歸併操作上的一種有效的排序演算法,該演算法是採用分治法(Divide and Conquer)的一個非常典型的應用。將已有序的子序列合併,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合併成一個有序表,稱為二路歸併。
演算法簡述:
- 把長度為n的輸入序列分成兩個長度為n/2的子序列;
- 對這兩個子序列分別採用歸併排序;
- 將兩個排序好的子序列合併成一個最終的排序序列。
動畫演示:

程式碼實現:
C++版本
void MergeArray(int a[], int first, int mid, int last, int tmp[]){
int i = first, n = mid;
int j = mid + 1, m = last;
int k = 0;
while (i <= n&&j <= m)
{
if (a[i] < a[j])
tmp[k++] = a[i++];
else
tmp[k++] = a[j++];
}
while (i <= n) {
tmp[k++] = a[i++];
}
while (j <= m)
tmp[k++] = a[j++];
for (i = 0; i < k; i++)
a[first + i] = tmp[i];
}
// 先遞迴地分解數列,再合併數列完成歸併排序
void MergesortSection(int a[], int first, int last, int tmp[]){
if (first < last)
{
int mid = (first + last) / 2;
MergesortSection(a, first, mid, tmp); // 左邊有序
MergesortSection(a, mid + 1, last, tmp); // 右邊有序
MergeArray(a, first, mid, last, tmp); // 合併兩個有序序列
}
}
void Mergesort(int a[], int n){
int *p = new int[n];
if (p == NULL)
return;
MergesortSection(a, 0, n - 1, p);
delete[] p;
}4.8 多路歸併排序
定義:
程式碼實現:
異同:
四、 演算法詳情--線性時間非比較演算法
4.9 基數排序
定義:
基數排序是按照低位先排序,然後收集;再按照高位排序,然後再收集;依次類推,直到最高位。有時候有些屬性是有優先順序順序的,先按低優先順序排序,再按高優先順序排序。最後的次序就是高優先順序高的在前,高優先順序相同的低優先順序高的在前。
演算法描述:
- 取得陣列中的最大數,並取得位數;
- arr為原始陣列,從最低位開始取每個位組成radix陣列;
- 對radix進行計數排序(利用計數排序適用於小範圍數的特點);
動畫演示:

程式碼實現:
C++
//基數排序
//尋找陣列中最大數的位數作為基數排序迴圈次數
int KeySize(int a[], int n){
int key = 1;
for(int i=0;i<n;i++){
int temp = 1;
int r = 10;
while(a[i]/r>0){
temp++;
r*=10;
}
key = (temp>key)?temp:key;
}
return key;
}
//基數排序
void RadixSort(int a[], int n){
int key = KeySize(a,n);
int bucket[10][10]={0};
int order[10]={0};
for(int r = 1;key>0;key--,r*=10){
for(int i=0;i<n;i++){
int lsd = (a[i]/r)%10;
bucket[lsd][order[lsd]++]=a[i];
}
int k = 0;
for(int i = 0;i<10;i++){
if(order[i]!=0){
for(int j = 0;j<order[i];j++)
a[k++]=bucket[i][j];
}
order[i]=0;
}
}
}
異同:
4.10 桶排序
定義:
桶排序是計數排序的升級版。它利用了函式的對映關係,高效與否的關鍵就在於這個對映函式的確定。桶排序 (Bucket sort)的工作的原理:假設輸入資料服從均勻分佈,將資料分到有限數量的桶裡,每個桶再分別排序(有可能再使用別的排序演算法或是以遞迴方式繼續使用桶排序進行排)。
演算法描述:
- 設定一個定量的陣列當作空桶;
- 遍歷輸入資料,並且把資料一個一個放到對應的桶裡去;
- 對每個不是空的桶進行排序;
- 從不是空的桶裡把排好序的資料拼接起來。
動畫演示:
程式碼實現:
C++版本
//桶排序 1,桶排序是穩定的 2,桶排序是常見排序裡最快的一種,比快排還要快…大多數情況下 3,桶排序非常快,但是同時也非常耗空間,基本上是最耗空間的一種排序演算法
void BucketSort(int a[],int n)
{
int maxVal = a[0]; //假設最大為arr[0]
for(int x = 1; x < n; x++) //遍歷比較,找到大的就賦值給maxVal
{
if(a[x] > maxVal)
maxVal = a[x];
}
int tmpArrLen = maxVal + 1;
int *tmpArr = new int[tmpArrLen]; //獲得空桶大小
int i, j;
for( i = 0; i < tmpArrLen; i++) //空桶初始化
tmpArr[i] = 0;
for(i = 0; i < n; i++) //尋訪序列,並且把專案一個一個放到對應的桶子去。
tmpArr[ a[i] ]++;
for(i = 0, j = 0; i < tmpArrLen; i++)
{
while( tmpArr[ i ] != 0) //對每個不是空的桶子進行排序。
{
a[j ] = i; //從不是空的桶子裡把專案再放回原來的序列中。i為索引,陣列的索引位置就表示值
j++;
tmpArr[i]--;
}
}
}異同:
4.11 計數排序
定義:
對於每個元素x,找出比x小的數的個數,從而確定x在排好序的陣列中的位置。此演算法需要輔助陣列,是以空間換時間。
演算法描述:
- 找出待排序的陣列中最大和最小的元素;
- 統計陣列中每個值為i的元素出現的次數,存入陣列C的第i項;
- 對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加);
- 反向填充目標陣列:將每個元素i放在新陣列的第C(i)項,每放一個元素就將C(i)減去1。
動畫演示:

程式碼實現:
C++版本
void CountSort(vector<int> &arr, int maxVal) {
int len = arr.size();
if (len < 1)
return;
vector<int> count(maxVal+1, 0);
vector<int> tmp(arr);
for (auto x : arr)
count[x]++;
for (int i = 1; i <= maxVal; ++i)
count[i] += count[i - 1];
for (int i = len - 1; i >= 0; --i) {
arr[count[tmp[i]] - 1] = tmp[i];
count[tmp[i]]--; //注意這裡要減1
}
}int main()
{
int i;
int a[] = {9, 8, 7, 6, 5, 4, 3, 2, 1, 10};
// 計數排序 OK
int max = a[0];
for (int i = 1;i < 10; ++i)
{
if (a[i]>max)
{
max = a[i];
}
}
Counting_sort(a,10,max+1);
for (int i = 0; i < 10; ++i)
{
cout<<a[i]<<" ";
}
system("pause");
return 0;
}1、基於比較的排序演算法有:
(1)直接插入排序;
(2)氣泡排序;
(3)簡單選擇排序;
(4)希爾排序;
(5)快速排序;
(6)堆排序;
(7)歸併排序。
2、基數排序(radix sort)屬於“分配式排序”(distribution sort),又稱“桶子法”(bucket sort)或bin sort,顧名思義,它是透過鍵值的部分資訊,將要排序的元素分配至某些“桶”中,藉以達到排序的作用,基數排序法是屬於穩定性的排序,其時間複雜度為O (nlog(r)m),其中r為所採取的基數,而m為堆數,在某些時候,基數排序法的效率高於其它的穩定性排序法。