
Flink流計算程式設計--看看別人怎麼用Session Window
1、簡介
流處理在實際生產中體現的價值越來越大,Apache Flink這個純流式計算框架也正在被越來越多的公司所關注並嘗試使用其流上的功能。
在2017年波蘭華沙大資料峰會上,有一家叫做GetInData的公司,分享了一個關於他們內部如何使用Flink的session window的例子,並因此獲評最佳演講。PPT:STREAMING ANALYTICS BETTER THAN CLASSIC BATCH – WHEN AND WHY ?
基於此演講,該公司後續寫了一個系列blog(2篇),詳細的闡述了使用session window的來龍去脈。本文基於這兩篇blog,做些簡要的說明,也正好參考下別人是如何從傳統的批的方式(spark),轉而使用現代的流處理技術(Flink)來更好的實現其業務功能的。
2、User Sessionization
該公司是一家資訊科技服務公司,由前Spotify員工組建。他們的這個案例受Spotify的啟發,基於user session進行實時的資料分析。
關於Spotify提供的每週歌曲推薦,可以參考InfoQ上的一篇文章:Spotify每週歌曲推薦演算法解析。
首先,基於使用者的session,你可以作如下事情:
1、儀表板上顯示一些KPI,例如使用者在每週的Discover Weekly播放列表中聽了多長時間,或者連續聽了多少首歌曲等。 2、通過這些指標,你可以改進你的推薦演算法,併發出一些警告及時的捕獲一些變化較大的資訊,例如澳大利亞使用者聽Discover Weekly播放列表中歌曲的時間太短。 3、而且,基於當前的資料分析,我們可以根據不同的使用者,做些個性化的歌曲推薦和廣告推薦。

3、古典的批處理架構
許多公司使用類似於Kafka、Hadoop、Spark、Oozie來分析使用者session問題。
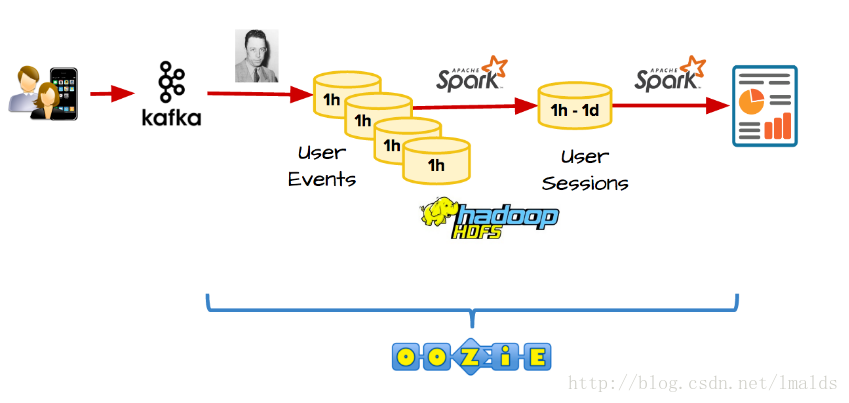
古典的批處理架構如下:使用者會話的資料被實時的傳送到kafka,之後使用批處理工具例如Campus(Gobblin)將kafka中的資料定時傳送到HDFS,這裡假設1小時抽取一次;之後由Spark來每小時進行一次批處理的Job,以計算使用者session的資料分析。
但是這裡有一個問題是使用者可能會一直在聽歌曲,因此session持續的時間很長,這樣得到的結果就是不正確的。一種可選的解決方法就是通過維護一個每小時的中間結果來連線Job。關於使用古典的批處理來實現user session的問題,有一本專門的書來說明:
儘管批處理可以處理user session問題,但是依然有很多缺點:
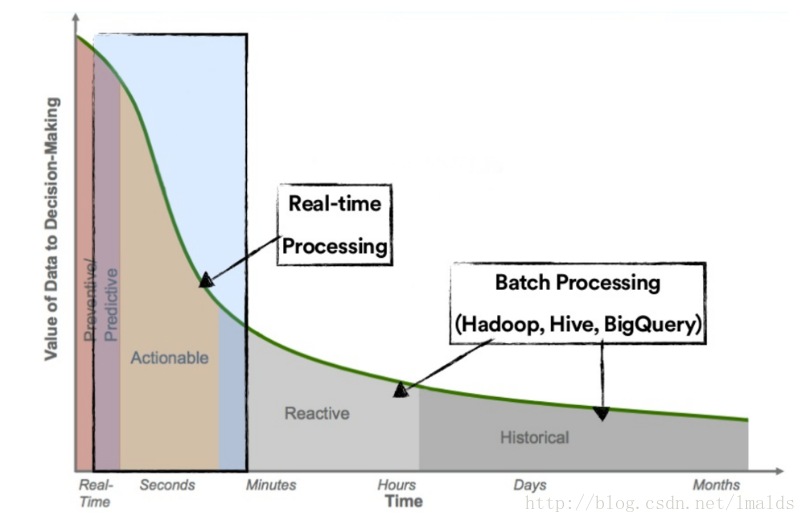
1、首先,這條pipeline上邊的元件太多,例如Gobblin,你需要部署額外的元件或者寫更多的程式碼來維持pipeline的可用性。
2、延遲性太高。這種架構不能實時的給出alerts,所有的結果必須等到1個小時後才能得到。4、微批架構
降低延遲並縮短結果反饋時間最簡單的方式看起來就是使用類似於Spark Streaming這種微批架構了。
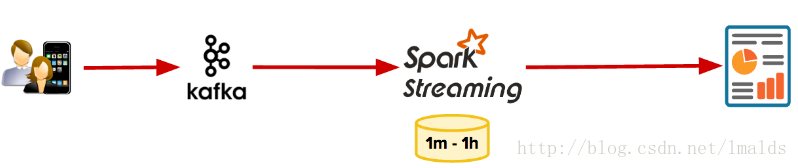
這種架構省去了Gobblin、Oozie、HDFS分割槽等元件,通過配置Spark Streaming的Job以每10分鐘、5分鐘或1分鐘的批次,來實現更低的延遲。
但是,Spark Streaming本身沒有內建支援Session問題的處理,由於其微批架構,使用者不得不通過自定義的程式碼實現user session,同時這種方式不得不自己維持每個批次的狀態資訊。你可以通過mapWithState方法來維護每個user的session狀態,有很多文章都提到如何構建一個user session,但是都沒有提到實現過程中可能遇到的諸多問題。
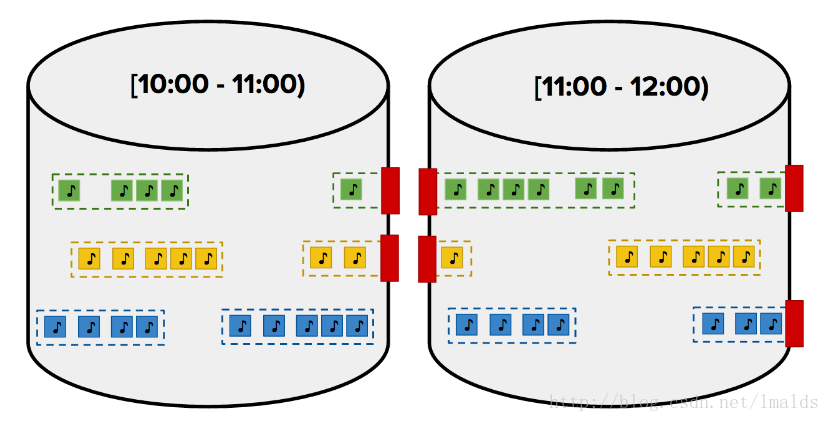
5、現實世界的事件流
在現實世界,資料是無界的。有可能產生亂序、延遲現象。例如使用者在飛機上是飛航模式(離線模式),此時正在聽spotify的歌曲,但是直到飛機降落才上線,此時資料的產生就是亂序的資料。而且由於經過kafka,由於並行處理的網路等原因,遲到的資料也是無處不在。
因此,如果還是採用Spark Streaming這種架構,這些問題的產生很可能不能正確的處理,這樣的結果就是不正確的。
6、解決流處理的問題
到這裡,讓我們問問我們自己,我們為什麼要用傳統的批處理、微批處理的方式來對待流資料呢?
在GetInData,我們找到了最簡單的、最重要、最正確的流處理引擎—Apache Flink。通過使用Flink,實施起來不但十分簡單,程式碼量很少,而且可以更快速的得到正確的結果。

7、實施案例
我們通過使用Flink很容易的解決了user session的問題,真的只有幾行程式碼!!!
案例A表示一個使用者在一個獨立的session中聽了多久的歌曲
案例B表示一個使用者在播放列表中連續聽了多少首歌曲首先,第一步我們需要從kafka中消費資料。通過Flink內部的檢查點機制,可以保證exactly once的處理,這僅僅需要提供幾個kafka的引數:
sEnv.addSource(new FlinkKafkaConsumer09[Event](conf.topic(),
getSerializationSchema,
kafkaProperties(conf.kafkaBroker()))
)之後,我們基於使用者key,設定一個session window的gap,在同一個session window中的資料表示使用者活躍的區間,假如gap的時間是15分鐘:
.keyBy(_.userId)
.window(EventTimeSessionWindows.withGap(Time.minutes(15)))最後,我們應用一個window function,就可以用5行程式碼實現亂序問題的處理:
val sessionStream : DataStream[SessionStats] = sEnv
.addSource(new FlinkKafkaConsumer09[Event](...))
.keyBy(_.userId)
.window(EventTimeSessionWindows.withGap(Time.minutes(15)))
.apply(new CountSessionStats())8、高階的時間處理
上邊這5行程式碼夠優雅麼?
答案是否定的,這裡即使基於Event Time以及應用watermark來處理亂序,依然不夠理想。考慮下面兩種情況:
1、例如15分鐘之後,突然來了一條之前5分鐘資料怎麼辦?這時之前的session就不應該產生gap。
2、再比如假如一個使用者一直在聽音樂,gap一直沒產生,那麼這個使用者的資料就一直無法及時產生。這個對於結果的反饋時間太長了。對於第一種情況,Flink提供了allowedLateness來處理延遲的資料,假設我們預計有些資料最晚會延遲1小時到來,那麼我們可以通過allowedLateness設定一個引數,來處理那些延遲的資料:
.allowedLateness(Time.minutes(60))這樣,當late data element到達時,我們依然可以正確的處理。
對於第二種情況,為了縮短結果的反饋時間,我們可以自定義一個early firing trigger實現每隔一段時間就觸發一次計算:
.trigger(EarlyTriggeringTrigger.every(Time.minutes(10)))例如,我們每隔10分鐘就觸發一次視窗計算。考慮一個簡單的例子,假如一個使用者session持續了1個小時,那麼通過這種觸發器,我們就可以每10分鐘便得到一個結果,之後的結果不斷更新之前的結果,最終趨於正確。後邊的結果相當於對前邊的結果的重新整理。

儘管程式碼相當簡單,但是其背後卻是Flink內援原理的支撐,例如低延遲、高吞吐、有狀態的處理、簡單的tasks等。
9、EarlyTriggeringTrigger的實現
class EarlyTriggeringTrigger(interval: Long) extends Trigger[Object, TimeWindow] {
//通過reduce函式維護一個Long型別的資料,此資料代表即將觸發的時間戳
private type JavaLong = java.lang.Long
//這裡取2個註冊時間的最小值,因為首先註冊的是視窗的maxTimestamp,也是最後一個要觸發的時間
private val min: ReduceFunction[JavaLong] = new ReduceFunction[JavaLong] {
override def reduce(value1: JavaLong, value2: JavaLong): JavaLong = Math.min(value1, value2)
}
private val serializer: TypeSerializer[JavaLong] = LongSerializer.INSTANCE.asInstanceOf[TypeSerializer[JavaLong]]
private val stateDesc = new ReducingStateDescriptor[JavaLong]("fire-time", min, serializer)
//每個元素都會執行此方法
override def onElement(element: Object,
timestamp: Long,
window: TimeWindow,
ctx: TriggerContext): TriggerResult =
//如果當前的watermark超過視窗的結束時間,則清除定時器內容,觸發視窗計算
if (window.maxTimestamp <= ctx.getCurrentWatermark) {
clearTimerForState(ctx)
TriggerResult.FIRE
}
else {
//否則將視窗的結束時間註冊給EventTime定時器
ctx.registerEventTimeTimer(window.maxTimestamp)
//獲取當前狀態中的時間戳
val fireTimestamp = ctx.getPartitionedState(stateDesc)
//如果第一次執行,則將元素的timestamp進行floor操作,取整後加上傳入的例項變數interval,得到下一次觸發時間並註冊,新增到狀態中
if (fireTimestamp.get == null) {
val start = timestamp - (timestamp % interval)
val nextFireTimestamp = start + interval
ctx.registerEventTimeTimer(nextFireTimestamp)
fireTimestamp.add(nextFireTimestamp)
}
//此時繼續等待
TriggerResult.CONTINUE
}
//這裡不基於processing time,因此永遠不會基於processing time 觸發
override def onProcessingTime(time: Long,
window: TimeWindow,
ctx: TriggerContext): TriggerResult = TriggerResult.CONTINUE
//之前註冊的Event Time Timer定時器,當watermark超過註冊的時間時,就會執行onEventTime方法
override def onEventTime(time: Long,
window: TimeWindow,
ctx: TriggerContext): TriggerResult = {
//如果註冊的時間等於maxTimestamp時間,清空狀態,並觸發計算
if (time == window.maxTimestamp()) {
clearTimerForState(ctx)
TriggerResult.FIRE
} else {
//否則,獲取狀態中的值(maxTimestamp和nextFireTimestamp的最小值)
val fireTimestamp = ctx.getPartitionedState(stateDesc)
//如果狀態中的值等於註冊的時間,則刪除此定時器時間戳,並註冊下一個interval的時間,觸發計算
//這裡,前提條件是watermark超過了定時器中註冊的時間,就會執行此方法,理論上狀態中的fire time一定是等於註冊的時間的
if (fireTimestamp.get == time) {
fireTimestamp.clear()
fireTimestamp.add(time + interval)
ctx.registerEventTimeTimer(time + interval)
TriggerResult.FIRE
} else {
//否則繼續等待
TriggerResult.CONTINUE
}
}
}
//上下文中獲取狀態中的值,並從定時器中清除這個值
private def clearTimerForState(ctx: TriggerContext): Unit = {
val timestamp = ctx.getPartitionedState(stateDesc).get()
if (timestamp != null) {
ctx.deleteEventTimeTimer(timestamp)
}
}
//用於session window的merge,判斷是否可以merge
override def canMerge: Boolean = true
override def onMerge(window: TimeWindow,
ctx: OnMergeContext): TriggerResult = {
ctx.mergePartitionedState(stateDesc)
val nextFireTimestamp = ctx.getPartitionedState(stateDesc).get()
if (nextFireTimestamp != null) {
ctx.registerEventTimeTimer(nextFireTimestamp)
}
TriggerResult.CONTINUE
}
//刪除定時器中已經觸發的時間戳,並呼叫Trigger的clear方法
override def clear(window: TimeWindow,
ctx: TriggerContext): Unit = {
ctx.deleteEventTimeTimer(window.maxTimestamp())
val fireTimestamp = ctx.getPartitionedState(stateDesc)
val timestamp = fireTimestamp.get
if (timestamp != null) {
ctx.deleteEventTimeTimer(timestamp)
fireTimestamp.clear()
}
}
override def toString: String = s"EarlyTriggeringTrigger($interval)"
}
//類中的every方法,傳入interval,作為引數傳入此類的構造器,時間轉換為毫秒
object EarlyTriggeringTrigger {
def every(interval: Time) = new EarlyTriggeringTrigger(interval.toMilliseconds)
}10、Flink中的ContinuousEventTimeTrigger
Flink中,其實已經實現了一個early trigger的功能,即ContinuousEventTimeTrigger,其實現方式大致相同:
/**
* A {@link Trigger} that continuously fires based on a given time interval. This fires based
* on {@link org.apache.flink.streaming.api.watermark.Watermark Watermarks}.
*
* @see org.apache.flink.streaming.api.watermark.Watermark
*
* @param <W> The type of {@link Window Windows} on which this trigger can operate.
*/
@PublicEvolving
public class ContinuousEventTimeTrigger<W extends Window> extends Trigger<Object, W> {
private static final long serialVersionUID = 1L;
private final long interval;
/** When merging we take the lowest of all fire timestamps as the new fire timestamp. */
private final ReducingStateDescriptor<Long> stateDesc =
new ReducingStateDescriptor<>("fire-time", new Min(), LongSerializer.INSTANCE);
private ContinuousEventTimeTrigger(long interval) {
this.interval = interval;
}
@Override
public TriggerResult onElement(Object element, long timestamp, W window, TriggerContext ctx) throws Exception {
if (window.maxTimestamp() <= ctx.getCurrentWatermark()) {
// if the watermark is already past the window fire immediately
return TriggerResult.FIRE;
} else {
ctx.registerEventTimeTimer(window.maxTimestamp());
}
ReducingState<Long> fireTimestamp = ctx.getPartitionedState(stateDesc);
if (fireTimestamp.get() == null) {
long start = timestamp - (timestamp % interval);
long nextFireTimestamp = start + interval;
ctx.registerEventTimeTimer(nextFireTimestamp);
fireTimestamp.add(nextFireTimestamp);
}
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception {
if (time == window.maxTimestamp()){
return TriggerResult.FIRE;
}
ReducingState<Long> fireTimestamp = ctx.getPartitionedState(stateDesc);
if (fireTimestamp.get().equals(time)) {
fireTimestamp.clear();
fireTimestamp.add(time + interval);
ctx.registerEventTimeTimer(time + interval);
return TriggerResult.FIRE;
}
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public void clear(W window, TriggerContext ctx) throws Exception {
ReducingState<Long> fireTimestamp = ctx.getPartitionedState(stateDesc);
Long timestamp = fireTimestamp.get();
if (timestamp != null) {
ctx.deleteEventTimeTimer(timestamp);
fireTimestamp.clear();
}
}
@Override
public boolean canMerge() {
return true;
}
@Override
public void onMerge(W window, OnMergeContext ctx) throws Exception {
ctx.mergePartitionedState(stateDesc);
Long nextFireTimestamp = ctx.getPartitionedState(stateDesc).get();
if (nextFireTimestamp != null) {
ctx.registerEventTimeTimer(nextFireTimestamp);
}
}
@Override
public String toString() {
return "ContinuousEventTimeTrigger(" + interval + ")";
}
@VisibleForTesting
public long getInterval() {
return interval;
}
/**
* Creates a trigger that continuously fires based on the given interval.
*
* @param interval The time interval at which to fire.
* @param <W> The type of {@link Window Windows} on which this trigger can operate.
*/
public static <W extends Window> ContinuousEventTimeTrigger<W> of(Time interval) {
return new ContinuousEventTimeTrigger<>(interval.toMilliseconds());
}
private static class Min implements ReduceFunction<Long> {
private static final long serialVersionUID = 1L;
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return Math.min(value1, value2);
}
}
}實現細節上省略了clearTimerForState(ctx)方法,同時增加了內部類Min實現求最小值的reduce方法。
11、後續的問題
儘管實現user session window很簡單,但是這僅僅是一個系統的第一步,還有後續的問題需要考慮:
(1)如何重新處理資料?
假如我改了程式,想用以前的資料測試對比下兩套程式的結果,Flink流上也可以實現麼?答案是可以的。你可以通過“savepoints”功能實現。例如每天夜裡12點定時產生savepoint,當你想重新消費資料時,就從那個savepoint開始重新消費kafka中的資料,相當於將時間回撥到了儲存點的時間。
但這也有負面的影響,就是下游的輸出可能已經落地了,但是如何處理他們是系統外部的事情了,但這一點也不容忽視。
(2)如果kafka中的資料沒了怎麼辦?
這是個好問題,kafka具有持久化的能力,但大都由於磁碟限制,通過保留策略來保留一段時間的資料。假如我們想重新處理1年前的資料怎麼辦?一種可行的辦法是將kafka的資料抽取到HDFS上,然後通過重寫SourceFunction來重新消費這些資料。
但是這裡引入另外一個問題–亂序。因為HDFS中的資料不保證是嚴格按事件發生的順序存放的,消費時就可能產生亂序。
還有一點問題未解決,即在kafka和HDFS之間切換來消費資料,但這對於維護offset資訊太難了。
(3)一個流如何和其他的data Sets/stream進行join?
第一種情況是DataStream join DataStream,這個很簡單,雙流join的問題之前的blog中已經講過:
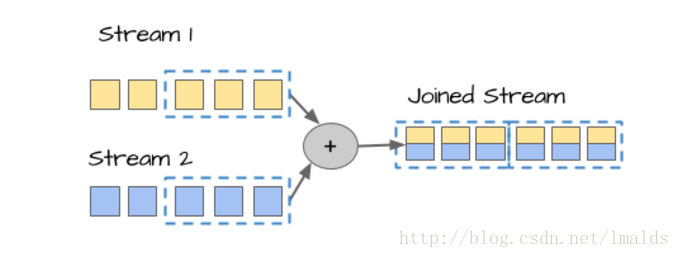
第二種情況是DataStream join DataSet。這個通常的做法是DataStream通過實現RichXXXFunction,重寫open方法,在open方法中將dataSet資訊寫入一個集合容器,然後對DataStream中的每個元素去匹配這個集合。
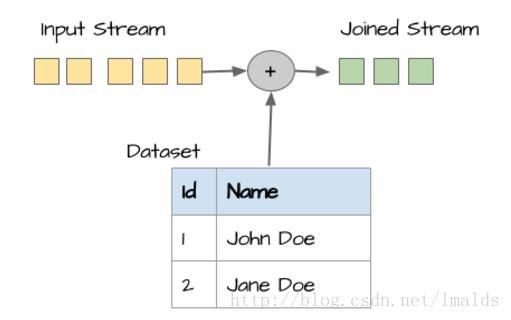
(4)我能用Flink做批處理麼?
當然可以,Flink支援批和流的處理,你甚至可以用Apache Beam或Flink的Table API來進行批處理。
(5)什麼時候適合用批處理?
批處理在很多場景下依然是非常好的選擇,例如ad-hoc查詢,像Hive、Spark-SQL、Presto、Kylin、Spark + R等就是非常好的工具。
當你要處理大量的HDFS上的資料時,也非常適合批處理。
而一些library的支援也僅僅在批處理上比較成熟,例如機器學習和圖計算。
12、最重要的建議
流處理並不僅僅是為了觸發某些警告或者以更低的延遲獲得結果。
流處理通常是許多現實問題很自然的表達呈現形式,你可以在流上實現實時的ETL、統計一些KPI的指標、增強業務報告等。
像Flink這種現代的流處理框架,你可以用它很容易的、不斷的處理並獲得正確的結果。
總結起來就是:
當資料不斷產生時,不要以批的方式去處理流!!!當資料不斷產生時,不要以批的方式去處理流!!!當資料不斷產生時,不要以批的方式去處理流!!!