
Flink流計算程式設計--在雙流中體會joinedStream與coGroupedStream
一、joinedStream與coGroupedStream簡介
在實際的流計算中,我們經常會遇到多個流進行join的情況,Flink提供了2個Transformations來實現。
如下圖:
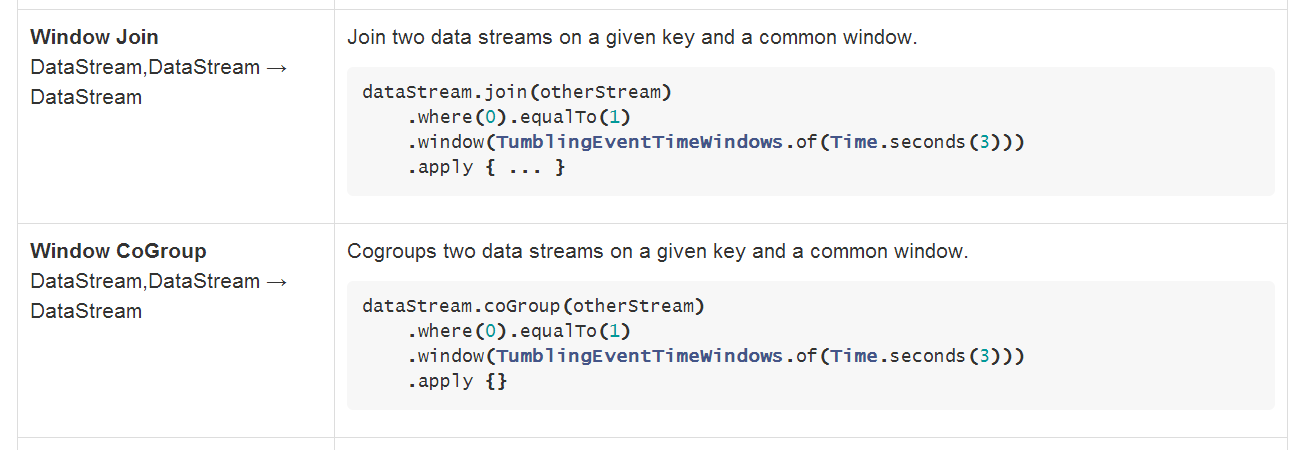
注意:Join(Cogroups) two data streams on a given key and a common window。這裡很明確了,我們要在2個DataStream中指定連線的key以及window下來運算。
二、SQL比較
我們最熟悉的SQL語言中,如果想要實現2個表join,可以如下實現:
select T1.* , T2.*
from T1
join 這個SQL是一個inner join的形式。稍微複雜點的帶有group by與order by的SQL如下:
select T1.key , sum(T2.col)
from T1
join T2 on T1.key = T2.key
group by T1.key
order by T1.col;通過這2個SQL,我們想要在Flink中實現實時的流計算,就可以通過joinedStream或coGroupedStream來實現。但是在join之後實施更復雜的運算,例如判斷、迭代等,僅僅通過SQL實現,恐怕會很麻煩,只能通過PL/SQL塊來實現,而Flink提供了apply方法,使用者可以自己編寫複雜的函式來實現。
三、join與coGroup的區別
先來看下原始碼中提供的類與方法比較下:
1、join
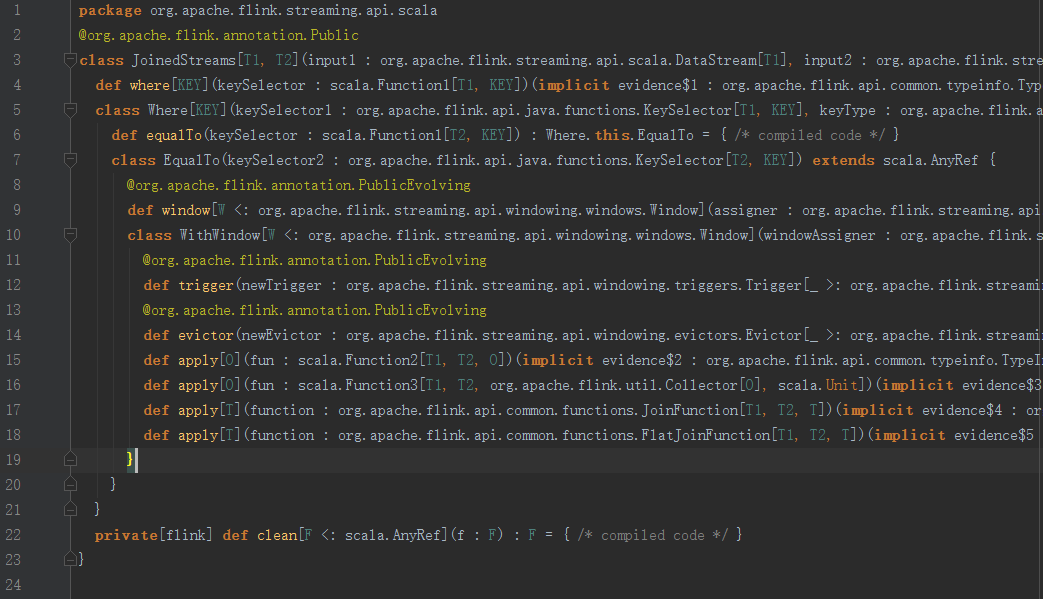
通過結構可以發現,在JoinedStreams提供了where方法,在where類中提供了equalTo方法,下一層就是window,之後是trigger、evictor以及apply方法。
這裡貼出一個程式碼模板共參考:
* val one: DataStream[(String, Int)] = ...
* val two: DataStream[(String, Int)] = ...
*
* val result = one.join(two)
* .where {t => ... 2、coGroup
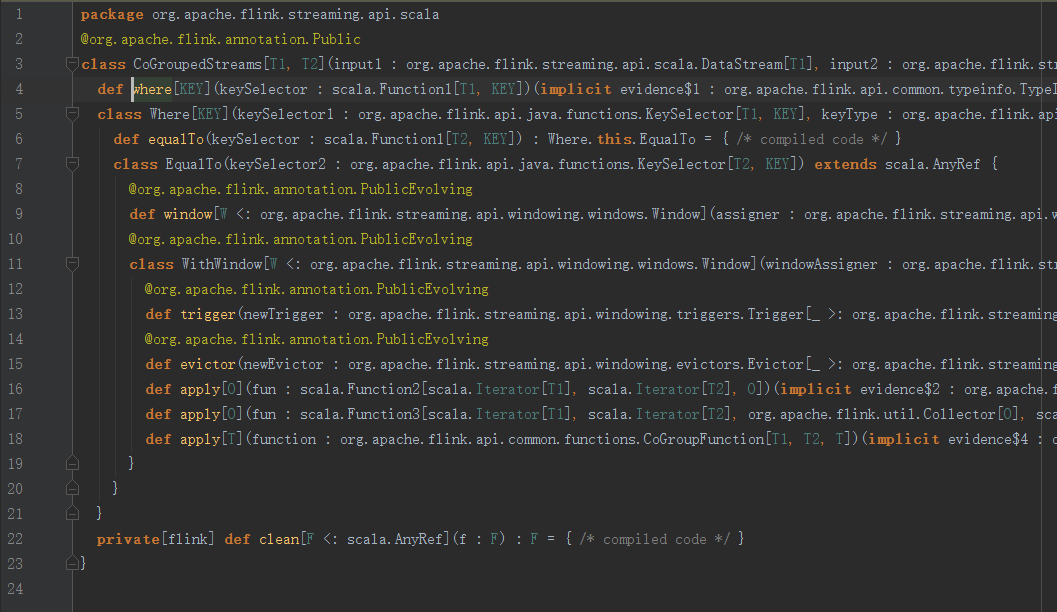
仔細觀察我們發現,實現上與join幾乎一樣,唯一的區別在於apply方法提供的引數型別。
程式碼模板如下:
* val one: DataStream[(String, Int)] = ...
* val two: DataStream[(String, Int)] = ...
*
* val result = one.coGroup(two)
* .where(new MyFirstKeySelector())
* .equalTo(new MyFirstKeySelector())
* .window(TumblingEventTimeWindows.of(Time.of(5, TimeUnit.SECONDS)))
* .apply(new MyCoGroupFunction())3、區別
剛才提到的apply方法中的引數型別不一樣,join中提供的apply方法,引數是T1與T2這2種資料型別,對應到SQL中就是T1.* 與 T2.*的一行資料。而coGroup中提供的apply方法,引數是Iterator[T1]與Iterator[2]這2種集合,對應SQL中類似於Table[T1]與Table[T2]。
基於這2種方式,如果我們的邏輯不僅僅是對一條record做處理,而是要與上一record或更復雜的判斷與比較,甚至是對結果排序,那麼join中的apply方法顯得比較困難。

四、程式實踐
下面開始實際演示程式的編寫與程式碼的打包併發布到叢集,最後輸出結果的一步步的過程。
說明:由於是雙流,我模擬Kafka的Topic,自定義了2個socket,其中一個指定“transaction”的實時交易輸入流,另一個socket指定“Market”的快照輸入流,原則上每3秒(時間戳)生成1個快照。
1、join
由於是2個DataStream,且我的邏輯是要根據各自流產生的時間戳去限制window,因此這裡要對2個流都分配時間戳並emit水位線(採用EventTime):
val eventMarketStream = marketDataStream.assignAscendingTimestamps(_._2)
val eventTransactionStream = transactionDataStream.assignAscendingTimestamps(_._2)join操作後,apply方法接收的只是T1與T2的型別:
val joinedStreams = eventTransactionStream
.join(eventMarketStream)
.where(_._1)
.equalTo(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply{
(t1 : (Long, Long, Long, Long), t2 : (Long, Long, Long), out : Collector[(Long,String,String,Long,Long,Long)]) =>
val transactionTime = t1._2
val marketTime = t2._2
val differ = transactionTime - marketTime
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
if(differ >=0 && differ <= 3 * 1000) {
out.collect(t1._1,format.format(marketTime) + ": marketTime", format.format(transactionTime) + ": transactionTime",t2._3,t1._3,t1._4)
}
}這裡實現的邏輯就是每個key在10秒的EventTime視窗中join,且只需要那些交易時間在快照時間之後,且在3秒的間隔內的資料。
詳細的程式碼如下:
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
/**
* Created by zhe on 2016/6/21.
*/
object JoinedOperaion {
case class Transaction(szWindCode:String, szCode:Long, nAction:String, nTime:String, seq:Long, nIndex:Long, nPrice:Long,nVolume:Long, nTurnover:Long, nBSFlag:Int, chOrderKind:String, chFunctionCode:String,nAskOrder:Long, nBidOrder:Long, localTime:Long)
case class MarketInfo(szCode : Long, nActionDay : String, nTime : String, nMatch : Long)
case class Market(szCode : Long, eventTime : String, nMatch : Long)
def main(args: Array[String]): Unit = {
/**
* 引數包含3個:hostname,port1,port2
* port1:作為Transaction的輸入流(例如nc -lk 9000,然後輸入引數指定9000)
* port2:作為Market的輸入流(例如nc -lk 9999,然後輸入引數指定9999)
*/
if(args.length != 3){
System.err.println("USAGE:\nSocketTextStream <hostname> <port1> <port2>")
return
}
val hostname = args(0)
val port1 = args(1).toInt
val port2 = args(2).toInt
/**
* 1、指定執行環境,設定EventTime
* 1、Obtain an execution environment
*/
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
/**
* 2、建立初始化資料流:Transaction與market
* 2、Load/create the initial data
*/
val inputTransaction = env.socketTextStream(hostname, port1)
val inputMarket = env.socketTextStream(hostname, port2)
/**
* 3、實施“累計資金流量”,
* 資金流量(in) = if(當前價格>LastPrice){sum + = nTurnover}elsif(當前價格=LastPrice且最近的一次Transaction的價格<>LastPrice的價格且那次價格>LastPrice){sum += nTurnover}
* 資金流量(out) = if(當前價格<LastPrice){sum + = nTurnover}elsif(當前價格=LastPrice且最近的一次Transaction的價格<>LastPrice的價格且那次價格<LastPrice){sum += nTurnover}
* 3、Specify transformations on this data
*/
val transactionDataStream = inputTransaction.map(new TransactionPrice)
val marketDataStream = inputMarket.map(new MarketPrice)
val eventMarketStream = marketDataStream.assignAscendingTimestamps(_._2)
val eventTransactionStream = transactionDataStream.assignAscendingTimestamps(_._2)
val joinedStreams = eventTransactionStream
.join(eventMarketStream)
.where(_._1)
.equalTo(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply{
(t1 : (Long, Long, Long, Long), t2 : (Long, Long, Long), out : Collector[(Long,String,String,Long,Long,Long)]) =>
val transactionTime = t1._2
val marketTime = t2._2
val differ = transactionTime - marketTime
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
if(differ >=0 && differ <= 3 * 1000) {
out.collect(t1._1,format.format(marketTime) + ": marketTime", format.format(transactionTime) + ": transactionTime",t2._3,t1._3,t1._4)
}
}
.name("JoinedStream Test")
/**
* 4、標準輸出
* 4、Specify where to put the results of your computations
*/
joinedStreams.print()
/**
* 5、執行程式
* 5、Trigger the program execution
*/
env.execute("2 DataStream join")
}
class TransactionPrice extends MapFunction[String,(Long, Long, Long, Long)]{
def map(transactionStream: String): (Long, Long, Long,Long) = {
val columns = transactionStream.split(",")
val transaction = Transaction(columns(0),columns(1).toLong,columns(2),columns(3),columns(4).toLong,columns(5).toLong,
columns(6).toLong,columns(7).toLong,columns(8).toLong,columns(9).toInt,columns(9),columns(10),columns(11).toLong,
columns(12).toLong,columns(13).toLong)
val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
if(transaction.nTime.length == 8){
val eventTimeString = transaction.nAction + '0' + transaction.nTime
val eventTime : Long = format.parse(eventTimeString).getTime
(transaction.szCode,eventTime,transaction.nPrice,transaction.nTurnover)
}else{
val eventTimeString = transaction.nAction + transaction.nTime
val eventTime = format.parse(eventTimeString).getTime
(transaction.szCode,eventTime,transaction.nPrice,transaction.nTurnover)
}
}
}
class MarketPrice extends MapFunction[String, (Long, Long, Long)]{
def map(marketStream : String) : (Long, Long, Long) = {
val columnsMK = marketStream.split(",")
val marketInfo = MarketInfo(columnsMK(0).toLong,columnsMK(1),columnsMK(2),columnsMK(3).toLong)
val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
if(marketInfo.nTime.length == 8){
val eventTimeStringMarket = marketInfo.nActionDay + '0' + marketInfo.nTime
val eventTimeMarket = format.parse(eventTimeStringMarket).getTime
(marketInfo.szCode, eventTimeMarket, marketInfo.nMatch)
}else{
val eventTimeStringMarket = marketInfo.nActionDay + marketInfo.nTime
val eventTimeMarket = format.parse(eventTimeStringMarket).getTime
(marketInfo.szCode, eventTimeMarket, marketInfo.nMatch)
}
}
}
}1.1、Maven打包

在專案的target目錄下會生成一個jar包:flink-scala-project-0.1.jar
將其拷貝到Driver(這裡採用master當作Driver)。
1.2、啟動hdfs叢集、Flink叢集,並開啟2個socket:
master上操作:
關於Hadoop叢集、Flink叢集的配置,參見各自的官方文件即可。
1.3、釋出程式到Flink叢集
這裡通過CLI(Command-Line Interface)的方式釋出:CLI
flink run -c toptrade.flink.trainning.JoinedOperaion /root/Documents/flink-scala-project-0.1.jar master 9998 9999
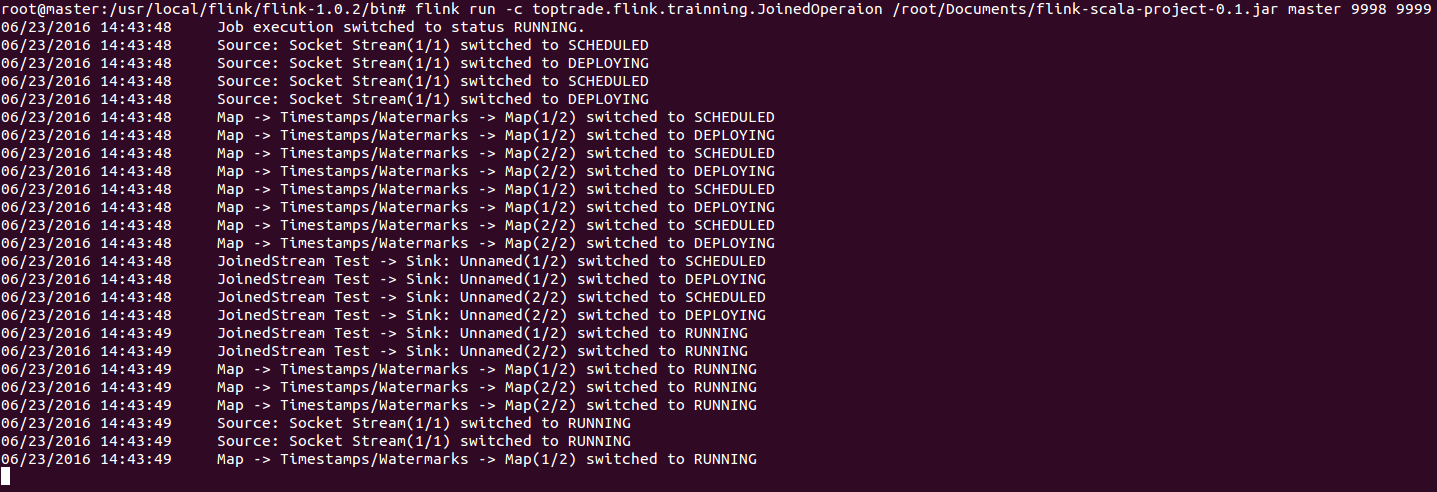
這裡-c是指定入口類,後邊的3個引數分別是:hostname、port1、port2
1.4、webUI檢視當前叢集狀態
Flink的conf檔案中,webUI的預設埠是8081。
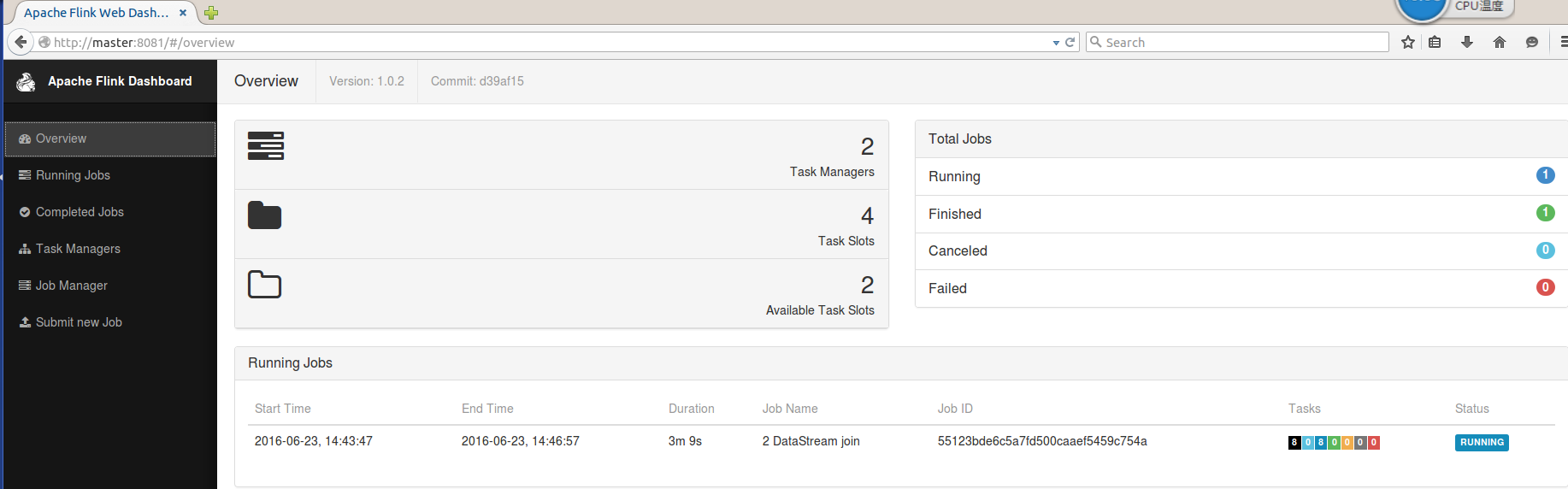
點開Running Jobs:
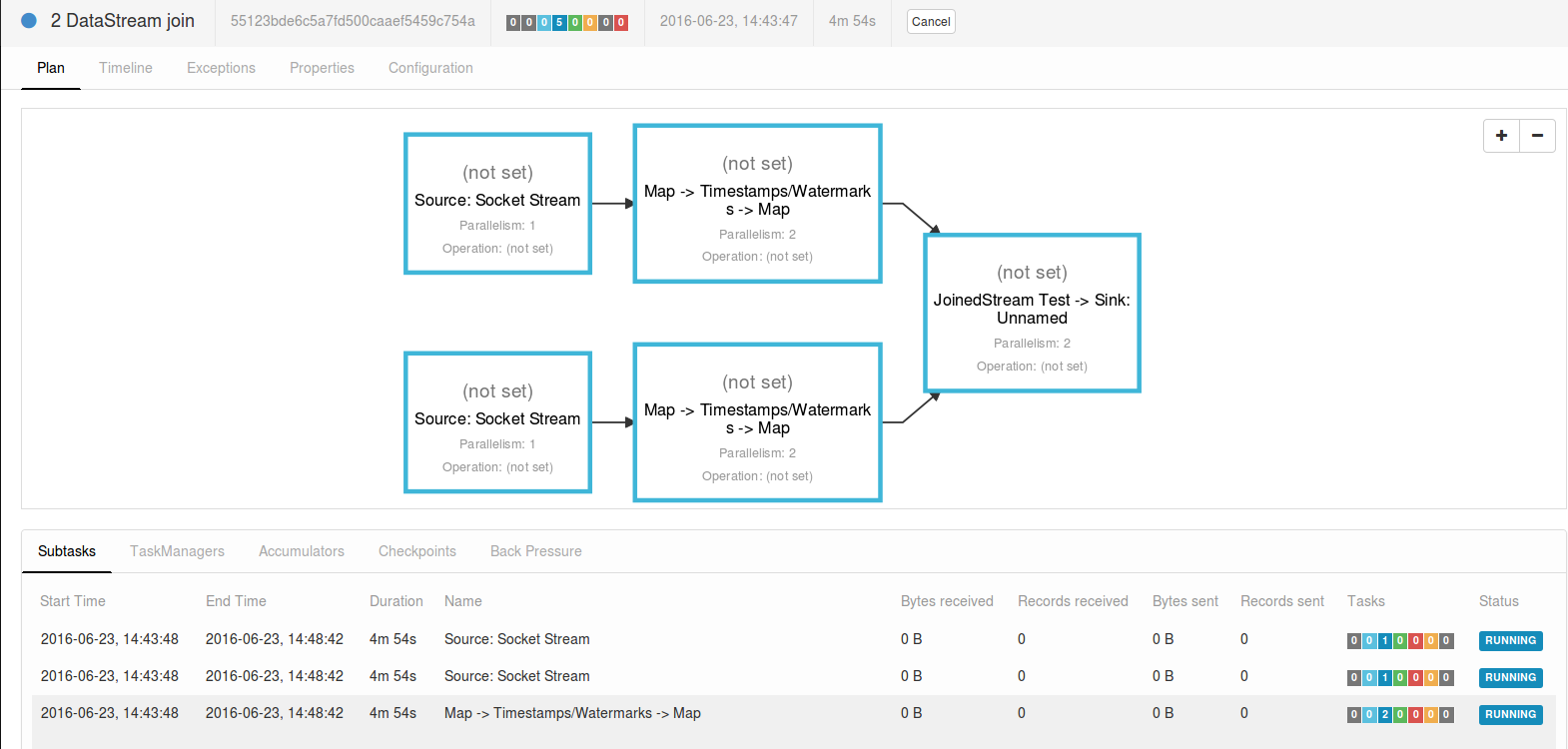
當前沒有任何資料流入,因此records的傳輸位元組都是0。
1.5、程序
由於程式直接釋出到了master,也就是master當作Driver來發布,因此看到的Job對應的程序名字叫:CliFrontend
1.6、輸入資料
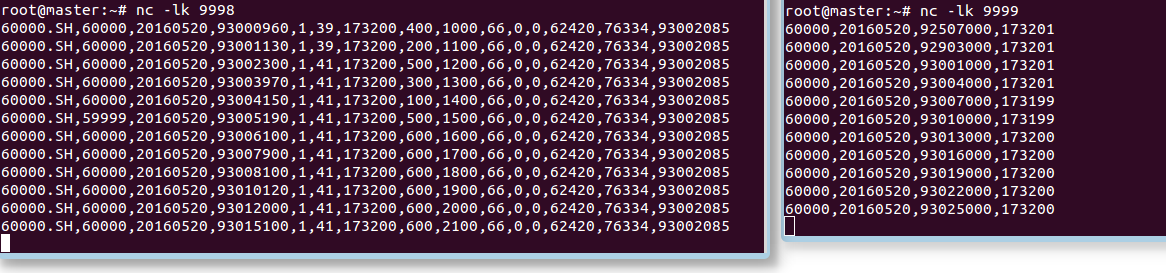
transaction的資料如下:
60000.SH,60000,20160520,93000960,1,39,173200,400,1000,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93001130,1,39,173200,200,1100,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93002300,1,41,173200,500,1200,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93003970,1,41,173200,300,1300,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93004150,1,41,173200,100,1400,66,0,0,62420,76334,93002085
60000.SH,59999,20160520,93005190,1,41,173200,500,1500,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93006100,1,41,173200,600,1600,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93007900,1,41,173200,600,1700,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93008100,1,41,173200,600,1800,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93010120,1,41,173200,600,1900,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93012000,1,41,173200,600,2000,66,0,0,62420,76334,93002085
60000.SH,60000,20160520,93015100,1,41,173200,600,2100,66,0,0,62420,76334,93002085
market的資料如下:
60000,20160520,92507000,173201
60000,20160520,92903000,173201
60000,20160520,93001000,173201
60000,20160520,93004000,173201
60000,20160520,93007000,173199
60000,20160520,93010000,173199
60000,20160520,93013000,173200
60000,20160520,93016000,173200
60000,20160520,93019000,173200
60000,20160520,93022000,173200
60000,20160520,93025000,173200
分別輸入socket9998與9999:
1.7、結果:
2> (60000,2016-05-20 09:30:01.000: marketTime,2016-05-20 09:30:02.300: transactionTime,173201,173200,1200)
2> (60000,2016-05-20 09:30:04.000: marketTime,2016-05-20 09:30:04.150: transactionTime,173201,173200,1400)
2> (60000,2016-05-20 09:30:04.000: marketTime,2016-05-20 09:30:06.100: transactionTime,173201,173200,1600)
2> (60000,2016-05-20 09:30:07.000: marketTime,2016-05-20 09:30:08.100: transactionTime,173199,173200,1800)
2> (60000,2016-05-20 09:30:01.000: marketTime,2016-05-20 09:30:01.130: transactionTime,173201,173200,1100)
2> (60000,2016-05-20 09:30:01.000: marketTime,2016-05-20 09:30:03.970: transactionTime,173201,173200,1300)
2> (60000,2016-05-20 09:30:07.000: marketTime,2016-05-20 09:30:07.900: transactionTime,173199,173200,1700)
~
我們看到,join操作沒問題,而且也按照我們的邏輯輸出了最終的結果,但唯一遺憾的是我無法再對這個結果進行排序操作,進而進行後續的計算。只能通過map對結果集進行自定義的排序。
這裡我的邏輯是希望對結果按照transaction的時間順序排序後,再進行復雜的計算,所以無法在一個apply中實現。
2、coGroup
這裡省略打包釋出的命令,直接貼上程式碼並看輸出結果:
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
import scala.collection.mutable.ListBuffer
object Job {
case class Transaction(szWindCode:String, szCode:Long, nAction:String, nTime:String, seq:Long, nIndex:Long, nPrice:Long,
nVolume:Long, nTurnover:Long, nBSFlag:Int, chOrderKind:String, chFunctionCode:String,
nAskOrder:Long, nBidOrder:Long, localTime:Long
)
case class MarketInfo(szCode : Long, nActionDay : String, nTime : String, nMatch : Long)
def main(args: Array[String]): Unit = {
/**
* 引數包含3個:hostname,port1,port2
* port1:作為Transaction的輸入流(例如nc -lk 9000,然後輸入引數指定9000)
* port2:作為Market的輸入流(例如nc -lk 9999,然後輸入引數指定9999)
*/
if(args.length != 3){
System.err.println("USAGE:\nSocketTextStream <hostname> <port1> <port2>")
return
}
val hostname = args(0)
val port1 = args(1).toInt
val port2 = args(2).toInt
/**
* 1、指定執行環境,設定EventTime
* 1、Obtain an execution environment
*/
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
/**
* 2、建立初始化資料流:Transaction與market
* 2、Load/create the initial data
*/
val inputTransaction = env.socketTextStream(hostname, port1)
val inputMarket = env.socketTextStream(hostname, port2)
/**
* 3、實施“累計資金流量”,
* 資金流量(in) = if(當前價格>LastPrice){sum + = nTurnover}elsif(當前價格=LastPrice且最近的一次Transaction的價格<>LastPrice的價格且那次價格>LastPrice){sum += nTurnover}
* 資金流量(out) = if(當前價格<LastPrice){sum + = nTurnover}elsif(當前價格=LastPrice且最近的一次Transaction的價格<>LastPrice的價格且那次價格<LastPrice){sum += nTurnover}
* 3、Specify transformations on this data
*/
val transactionDataStream = inputTransaction.map(new TransactionPrice)
val marketDataStream = inputMarket.map(new MarketPrice)
val eventMarketStream = marketDataStream.assignAscendingTimestamps(_._2)
val eventTransactionStream = transactionDataStream.assignAscendingTimestamps(_._2)
val coGroupedStreams = eventTransactionStream
.coGroup(eventMarketStream)
.where(_._1)
.equalTo(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply {
(t1: Iterator[(Long, Long, Long, Long)], t2: Iterator[(Long, Long, Long)], out: Collector[(Long, String, String, Long, Long)]) =>
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
val listOut = new ListBuffer[(Long, String, String, Long, Long, Long)]
//將Iterator的元素賦值給一個ListBuffer
val l1 = new ListBuffer[(Long,Long,Long,Long)]
while(t1.hasNext){
l1.append(t1.next())
}
val l2 = new ListBuffer[(Long,Long,Long)]
while(t2.hasNext){
l2.append(t2.next())
}
//遍歷每個ListBuffer,將coGroup後的所有結果進行判斷,只取Transaction的時間-Snapshot的時間between 0 和3000(ms)
for(e1 <- l1){
for(e2 <- l2){
if(e1._2 - e2._2 >=0 && e1._2 - e2._2 <= 3 * 1000){
listOut.append((e1._1,"tranTime: "+format.format(e1._2),"markTime: "+ format.format(e2._2),e1._3,e2._3, e1._4))
//out.collect(e1._1,"tranTime: "+format.format(e1._2),"markTime: "+ format.format(e2._2),e1._3,e2._3)
}
}
}
//需要將ListBuffer中的結果按照Transaction時間進行排序
val l : ListBuffer[(Long, String, String, Long, Long, Long)] = listOut.sortBy(_._2)
//測試是否按照transactionTime進行排序
l.foreach(f => println("排序後的結果集:" + f))
var fundFlowIn : Long = 0
var fundFlowOut : Long= 0
var InOutState : Int= 1
/**
* 實施“資金流量”的邏輯:
* 如果交易的價格 > 上一快照的價格,則資金流入
* 如果交易的價格 < 上一快照的價格,則資金流出
* 如果交易的價格 = 上一快照的價格,則要看上一交易是屬於流入還是流出,如果上一交易是流入,則流入,流出則流出
* 如果第一筆交易的價格與上一快照的價格相等,則預設資金流入
*/
for(item <- l) {
if (item._4 > item._5) {
fundFlowIn = fundFlowIn + item._6
InOutState = 1
} else if (item._4 < item._5) {
fundFlowOut = fundFlowOut + item._6
InOutState = 0
} else {
if (InOutState == 1) {
fundFlowIn = fundFlowIn + item._6
InOutState = 1
} else {
fundFlowOut = fundFlowOut + item._6
InOutState = 0
}
}
//out.collect(item._1,item._2,item._3,item._4,item._5)
}
if(!l.isEmpty) {
val szCode = l.head._1
val tranStartTime = l.head._2
val tranEndTime = l.last._2
out.collect(szCode,tranStartTime,tranEndTime,fundFlowIn, fundFlowOut)
}
}
.name("coGroupedStream Test")
/**
* 4、標準輸出
* 4、Specify where to put the results of your computations
*/
coGroupedStreams.print()
/**
* 5、執行程式
* 5、Trigger the program execution
*/
env.execute("2 DataStream coGroup")
}
class TransactionPrice extends MapFunction[String,(Long, Long, Long, Long)]{
def map(transactionStream: String): (Long, Long, Long,Long) = {
val columns = transactionStream.split(",")
val transaction = Transaction(columns(0),columns(1).toLong,columns(2),columns(3),columns(4).toLong,columns(5).toLong,
columns(6).toLong,columns(7).toLong,columns(8).toLong,columns(9).toInt,columns(9),columns(10),columns(11).toLong,
columns(12).toLong,columns(13).toLong)
val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
if(transaction.nTime.length == 8){
val eventTimeString = transaction.nAction + '0' + transaction.nTime
val eventTime : Long = format.parse(eventTimeString).getTime
(transaction.szCode,eventTime,transaction.nPrice,transaction.nTurnover)
}else{
val eventTimeString = transaction.nAction + transaction.nTime
val eventTime = format.parse(eventTimeString).getTime
(transaction.szCode,eventTime,transaction.nPrice,transaction.nTurnover)
}
}
}
class MarketPrice extends MapFunction[String, (Long, Long, Long)]{
def map(marketStream : String) : (Long, Long, Long) = {
val columnsMK = marketStream.split(",")
val marketInfo = MarketInfo(columnsMK(0).toLong,columnsMK(1),columnsMK(2),columnsMK(3).toLong)
val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
if(marketInfo.nTime.length == 8){
val eventTimeStringMarket = marketInfo.nActionDay + '0' + marketInfo.nTime
val eventTimeMarket = format.parse(eventTimeStringMarket).getTime
(marketInfo.szCode, eventTimeMarket, marketInfo.nMatch)
}else{
val eventTimeStringMarket = marketInfo.nActionDay + marketInfo.nTime
val eventTimeMarket = format.parse(eventTimeStringMarket).getTime
(marketInfo.szCode, eventTimeMarket, marketInfo.nMatch)
}
}
}
}這裡邊唯一的不同就是apply方法的引數,coGroup是iterator,我就可以直接在apply中進行排序,並計算了。
結果如下:
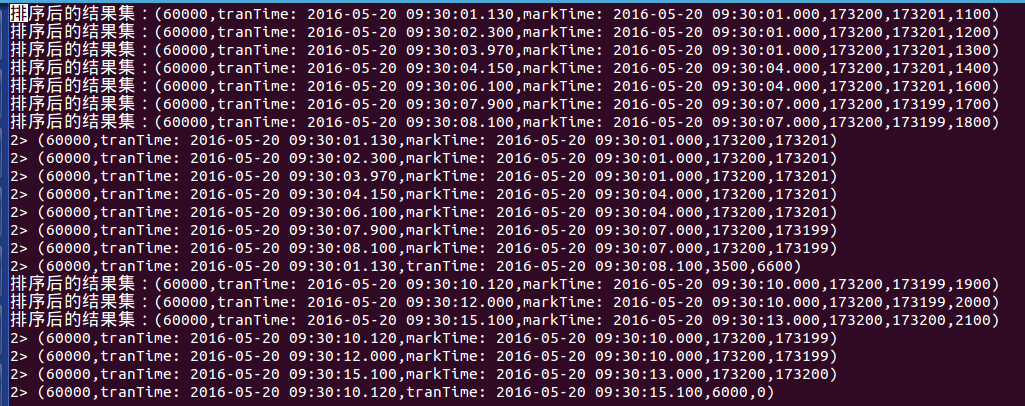
可以看到,結果按照transaction排序並生成了最終的資金流量(流入與流出)。
其實我想輸出的就是每個視窗內的:股票程式碼、視窗內最早的交易時間、視窗內最後的交易時間、資金流量流入、資金流量流出。
通過coGroup的諸多方法,實現了我的需求。
五、總結
join操作與coGroup操作在Flink流處理中很有用,其中coGroup相對來講功能更強大一點。
但是,相對於Spark提供了Spark SQL而言,Flink在DataStream中隊SQL的支援顯然不夠,在即將到來的Flink1.1以及未來的Flink1.2版本中,DataStream中會有對SQL的支援,那時候寫起程式會容易的多。