TLD目標跟蹤演算法學習(二)
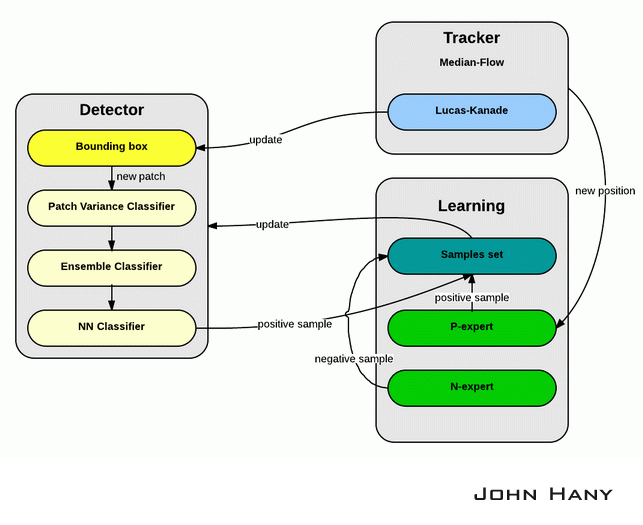
正如名字所示,TLD演算法主要由三個模組構成:追蹤器(tracker),檢測器(detector)和機器學習(learning)。
對於視訊追蹤來說,常用的方法有兩種,一是使用追蹤器根據物體在上一幀的位置預測它在下一幀的位置,但這樣會積累誤差,而且一旦物體在影象中消失,追蹤器就會永久失效,即使物體再出現也無法完成追蹤;另一種方法是使用檢測器,對每一幀單獨處理檢測物體的位置,但這又需要提前對檢測器離線訓練,只能用來追蹤事先已知的物體。
TLD是對視訊中未知物體的長時間跟蹤的演算法。“未知物體”指的是任意的物體,在開始追蹤之前不知道哪個物體是目標。“長時間跟蹤”又意味著需要演算法實時計算,在追蹤中途物體可能會消失再出現,而且隨著光照、背景的變化和由於偶爾的部分遮擋,物體在畫素上體現出來的“外觀”可能會發生很大的變化。從這幾點要求看來,單獨使用追蹤器或檢測器都無法勝任這樣的工作。所以作者提出把追蹤器和檢測器結合使用,同時加入機器學習來提高結果的準確度。
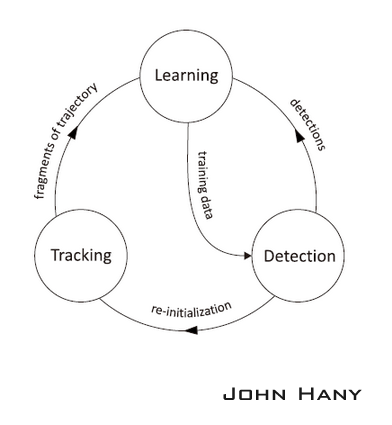
追蹤器的作用是跟蹤連續幀間的運動,當物體始終可見時跟蹤器才會有效。追蹤器根據物體在前一幀已知的位置估計在當前幀的位置,這樣就會產生一條物體運動的軌跡,從這條軌跡可以為學習模組產生正樣本(Tracking->Learning)。
檢測器的作用是估計追蹤器的誤差,如果誤差很大就改正追蹤器的結果。檢測器對每一幀影象都做全面的掃描,找到與目標物體相似的所有外觀的位置,從檢測產生的結果中產生正樣本和負樣本,交給學習模組(Detection->Learning)。演算法從所有正樣本中選出一個最可信的位置作為這一幀TLD的輸出結果,然後用這個結果更新追蹤器的起始位置(Detection->Tracking)。
學習模組
---------------------------------------
追蹤模組
TLD使用作者自己提出的Median-Flow追蹤演算法。
作者假設一個“好”的追蹤演算法應該具有正反向連續性(forward-backward consistency),即無論是按照時間上的正序追蹤還是反序追蹤,產生的軌跡應該是一樣的。作者根據這個性質規定了任意一個追蹤器的FB誤差(forward-backward error):從時間t的初始位置x(t)開始追蹤產生時間t+p的位置x(t+p),再從位置x(t+p)反向追蹤產生時間t的預測位置x`(t),初始位置

Median-Flow追蹤演算法採用的是Lucas-Kanade追蹤器,也就是常說的光流法追蹤器。這個追蹤器的原理就不在這裡解釋了。只需要知道給定若干追蹤點,追蹤器會根據畫素的運動情況確定這些追蹤點在下一幀的位置。
追蹤點的選擇:
作者給出了一種依據FB誤差繪製誤差圖(Error Map)篩選最佳追蹤點的方法,但並不適用於實時追蹤任務,就不詳細介紹了。這裡只介紹在TLD中確定追蹤點的方法。
首先在上一幀t的物體包圍框裡均勻地產生一些點,然後用Lucas-Kanade追蹤器正向追蹤這些點到t+1幀,再反向追蹤到t幀,計算FB誤差,篩選出FB誤差最小的一半點作為最佳追蹤點。最後根據這些點的座標變化和距離的變化計算t+1幀包圍框的位置和大小(平移的尺度取中值,縮放的尺度取中值。取中值的光流法,估計這也是名稱Median-Flow的由來吧)。

還可以用NCC(Normalized Cross Correlation,歸一化互相關)和SSD(Sum-of-Squared Differences,差值平方和)作為篩選追蹤點的衡量標準。作者的程式碼中是把FB誤差和NCC結合起來的,所以篩選出的追蹤點比原來一半還要少。
NCC:
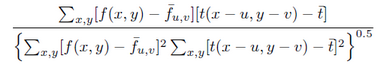
SSD:
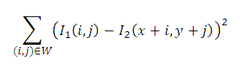
---------------------------------------
學習模組
TLD使用的機器學習方法是作者提出的P-N學習(P-N Learning)。P-N學習是一種半監督的機器學習演算法,它針對檢測器對樣本分類時產生的兩種錯誤提供了兩種“專家”進行糾正:(PN學習可參考:http://blog.csdn.net/carson2005/article/details/7647519)
P專家(P-expert):檢出漏檢(false negative,正樣本誤分為負樣本)的正樣本;
N專家(N-expert):改正誤檢(false positive,負樣本誤分為正樣本)的正樣本。
樣本的產生:
用不同尺寸的掃描窗(scanning grid)對影象進行逐行掃描,每在一個位置就形成一個包圍框(bounding box),包圍框所確定的影象區域稱為一個影象元(patch),影象元進入機器學習的樣本集就成為一個樣本。掃描產生的樣本是未標籤樣本,需要用分類器來分類,確定它的標籤。
如果演算法已經確定物體在t+1幀的位置(實際上是確定了相應包圍框的位置),從檢測器產生的包圍框中篩選出10個與它距離最近的包圍框(兩個包圍框的交的面積除以並的面積大於0.7),對每個包圍框做微小的仿射變換(平移10%、縮放10%、旋轉10°以內),產生20個影象元,這樣就產生200個正樣本。再選出若干距離較遠的包圍框(交的面積除以並的面積小於0.2),產生負樣本。這樣產生的樣本是已標籤的樣本,把這些樣本放入訓練集,用於更新分類器的引數。下圖中的a圖展示的是掃描窗的例子。
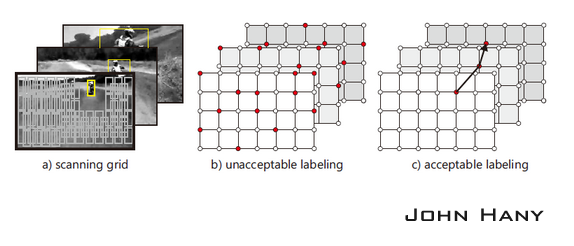
作者認為,演算法的結果應該具有“結構性”:每一幀影象內物體最多隻出現在一個位置;相鄰幀間物體的運動是連續的,連續幀的位置可以構成一條較平滑的軌跡。比如像上圖c圖那樣每幀只有一個正的結果,而且連續幀的結果構成了一條平滑的軌跡,而不是像b圖那樣有很多結果而且無法形成軌跡。還應該注意在整個追蹤過程中,軌跡可能是分段的,因為物體有可能中途消失,之後再度出現。
P專家的作用是尋找資料在時間上的結構性,它利用追蹤器的結果預測物體在t+1幀的位置。如果這個位置(包圍框)被檢測器分類為負,P專家就把這個位置改為正。也就是說P專家要保證物體在連續幀上出現的位置可以構成連續的軌跡;
N專家的作用是尋找資料在空間上的結構性,它把檢測器產生的和P專家產生的所有正樣本進行比較,選擇出一個最可信的位置,保證物體最多隻出現在一個位置上,把這個位置作為TLD演算法的追蹤結果。同時這個位置也用來重新初始化追蹤器。

比如在這個例子中,目標車輛是下面的深色車,每一幀中黑色框是檢測器檢測到的正樣本,黃色框是追蹤器產生的正樣本,紅星標記的是每一幀最後的追蹤結果。在第t幀,檢測器沒有發現深色車,但P專家根據追蹤器的結果認為深色車也是正樣本,N專家經過比較,認為深色車的樣本更可信,所以把淺色車輸出為負樣本。第t+1幀的過程與之類似。第t+2幀時,P專家產生了錯誤的結果,但經過N專家的比較,又把這個結果排除了,演算法仍然可以追蹤到正確的車輛。
---------------------------------------
檢測模組
檢測模組使用一個級聯分類器,對從包圍框獲得的樣本進行分類。級聯分類器包含三個級別:
影象元方差分類器(Patch Variance Classifier)。計算影象元畫素灰度值的方差,把方差小於原始影象元方差一半的樣本標記為負。論文提到在這一步可以排除掉一半以上的樣本。
整合分類器(Ensemble Classifier)。實際上是一個隨機蕨分類器(Random Ferns Classifier),類似於隨機森林(Random Forest),區別在於隨機森林的樹中每層節點判斷準則不同,而隨機蕨的“蕨”中每層只有一種判斷準則。
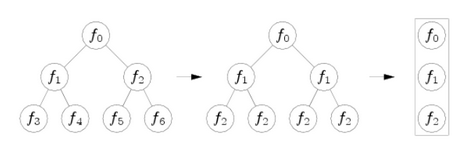
如上圖所示,把左面的樹每層節點改成相同的判斷條件,就變成了右面的蕨。所以蕨也不再是樹狀結構,而是線性結構。隨機蕨分類器根據樣本的特徵值判斷其分類。從影象元中任意選取兩點A和B,比較這兩點的亮度值,若A的亮度大於B,則特徵值為1,否則為0。每選取一對新位置,就是一個新的特徵值。蕨的每個節點就是對一對畫素點進行比較。
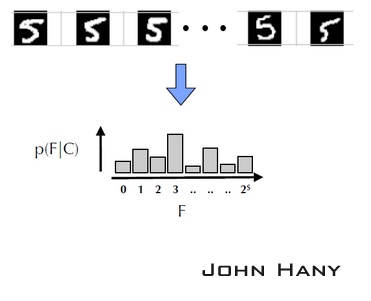
比如取5對點,紅色為A,藍色為B,樣本影象經過含有5個節點的蕨,每個節點的結果按順序排列起來,得到長度為5的二進位制序列01011,轉化成十進位制數字11。這個11就是該樣本經過這個蕨得到的結果。

同一類的很多個樣本經過同一個蕨,得到了該類結果的分佈直方圖。高度代表類的先驗概率p(F|C),F代表蕨的結果(如果蕨有s個節點,則共有1+2^s種結果)。
不同類的樣本經過同一個蕨,得到不同的先驗概率分佈。

以上過程可以視為對分類器的訓練。當有新的未標籤樣本加入時,假設它經過這個蕨的結果為00011(即3),然後從已知的分佈中尋找後驗概率最大的一個。由於樣本集固定時,右下角公式的分母是相同的,所以只要找在F=3時高度最大的那一類,就是新樣本的分類。
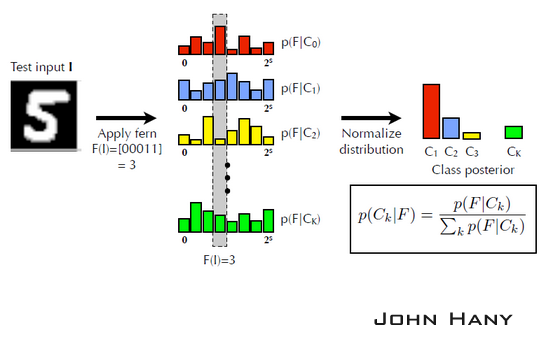
只用一個蕨進行分類會有較大的偶然性。另取5個新的特徵值就可以構成新的蕨。用很多個蕨對同一樣本分類,投票數最大的類就作為新樣本的分類,這樣在很大程度上提高了分類器的準確度。
最近鄰分類器(Nearest Neighbor Classifier)。計算新樣本的相對相似度,如大於0.6,則認為是正樣本。相似度規定如下:
影象元pi和pj的相似度,公式裡的N是規範化的相關係數,所以S的取值範圍就在[0,1]之間,
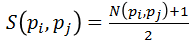
正最近鄰相似度,
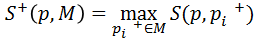
負最近鄰相似度,
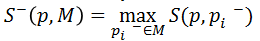
相對相似度,取值範圍在[0,1]之間,值越大代表相似度越高,
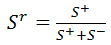
所以,檢測器是追蹤器的監督者,因為檢測器要改正追蹤器的錯誤;而追蹤器是訓練檢測器時的監督者,因為要用追蹤器的結果對檢測器的分類結果進行監督。用另一段程式對訓練過程進行監督,而不是由人來監督,這也是稱P-N學習為“半監督”機器學習的原因。
TLD的工作流程如下圖所示。首先,檢測器由一系列包圍框產生樣本,經過級聯分類器產生正樣本,放入樣本集;然後使用追蹤器估計出物體的新位置,P專家根據這個位置又產生正樣本,N專家從這些正樣本里選出一個最可信的,同時把其他正樣本標記為負;最後用正樣本更新檢測器的分類器引數,並確定下一幀物體包圍框的位置。