淘寶開源專案TbSchedule的部署和使用
tbschedule專案其實可以分為兩部分:
- schedule管理控制檯。負責控制、監控任務執行狀態
- 實際執行job的客戶端程式。
在實際使用時,首先要啟動zookeeper, 然後部署tbschedule web介面的管理控制檯,最後啟動實際執行job的客戶機器。這裡zookeeper並不實際控制任務排程,它只是負責與N臺執行job的客戶端通訊,協調、管理、監控這些機器的執行資訊。實際分配任務的是tbschedule管理控制檯,控制檯從zookeeper獲取job的執行資訊。
tbSchedule通過控制ZNode的建立、修改、刪除來間接控制Job的執行,執行Job的客戶端會監聽它們對應ZNode
部署zookeeper
去http://zookeeper.apache.org/releases.html#download下載最新穩定版本。下載完成後解壓,將 /conf目錄下的XXX.cfg更名為zoo.cfg,因為zookeeper啟動時會在這個目錄下找zoo.cfg讀取配置資訊。這個檔案裡有幾個重要的引數需要說明一下:
-
tickTime=2000-
定義時間計量單位。這裡表示一個
tick為2秒。以後在配置時間相關的東西時,都是以tick為單位的。
-
定義時間計量單位。這裡表示一個
-
dataDir=/tmp- 定義快照(snapshot)檔案的儲存位置。zookeeper會將節點資訊定時寫入到這個目錄中。這個目錄必須存在,否則啟動時會報錯。
-
clientPort=2181- 指定客戶端連線埠。 zookeeper會在這個埠監聽連線請求。
-
server.1=127.0.0.1:2000:3000-
這個引數僅在叢集部署時起作用。格式為:
server.id=host:port:port。id表示伺服器的唯一標識,一般從1開始計數。第一個port表示zookeeper叢集機器之間的通訊埠,第二個port表示當叢集機器在選舉leader時使用的通訊埠。只有當叢集第一次啟動,或master機崩潰時,才會進行leader選舉。
-
這個引數僅在叢集部署時起作用。格式為:
配置完成後,切換到/bin目錄,執行:
./zkServer.sh start即可啟動zookeeper,預設會在後臺執行,如果想在前端執行,需要執行:
./zkServer.sh start-foregroundZookeeper叢集部署
叢集部署時,除了需要指定zoo.cfg中server.X:XXXX:XX:XX引數外,還要在每臺機器的dataDir目錄下建立一個名為myid的檔案,內容為當前機器的標識數字,與server.X中的X相同。完成配置後,依次啟動每個zookeeper即可。
注意,當你在啟動第一個zookeeper時控制檯會大量報錯,這是因為其它的zookeeper還沒有啟動。無視即可。
tbSchedule控制檯部署
tbSchedule就是個用servlet/JSP 寫的web專案,我們可以直接把war包部署到tomcat中,然後在瀏覽器訪問
http://localhost:8080/ScheduleConsole即可。
如果你想手動編譯、構建專案而不是使用war包,要小心一個坑,那就是執行
mvn clean install -Dmaven.test.skip=true時maven會報找不到構件的錯誤。查其原因,是因為這個專案太老了,當時是用maven2構建的,專案中用到的依賴版本也比較老了,而且它們所在的repository已經停用了,因此無法自動下載。解決方法,直接exclusion缺少的依賴即可:
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.3.3</version><exclusions><exclusion><groupId>com.sun.jmx</groupId><artifactId>jmxri</artifactId></exclusion><exclusion><groupId>com.sun.jdmk</groupId><artifactId>jmxtools</artifactId></exclusion><exclusion><groupId>javax.jms</groupId><artifactId>jms</artifactId></exclusion></exclusions></dependency>第一次訪問控制檯時會出現以下配置頁面:
第一行指定zookeeper的地址、埠,第二行是超時時間。使用者名稱和密碼在這裡沒有任何用處,無視即可。要注意的是第三行Zookeeper的根目錄,這並不是指的部署zookeeper時指定的dataDir,而是一個你自己指定的、與當前管理控制檯在同一個機器上的目錄,tbSchedule管理控制檯會將任務的配置資訊(如執行開始時間,排程策略)儲存到該目錄下,這樣下次啟動管理控制檯時就可以直接從目錄中讀取配置資訊了。
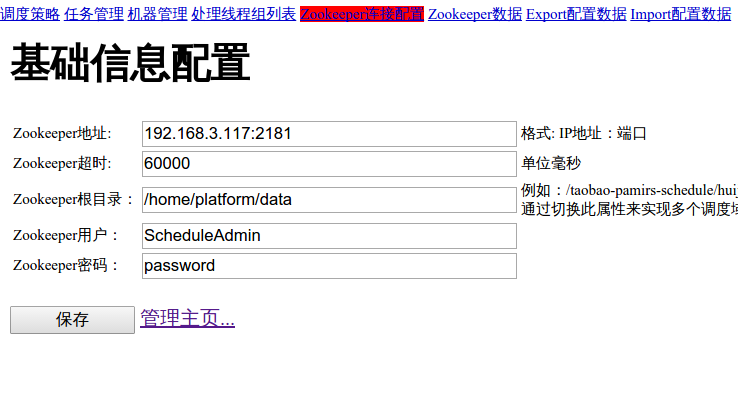
填寫完成後點儲存,此時上面會出現一行紅字,無視之。直接點選管理主頁即可進入管理頁面:
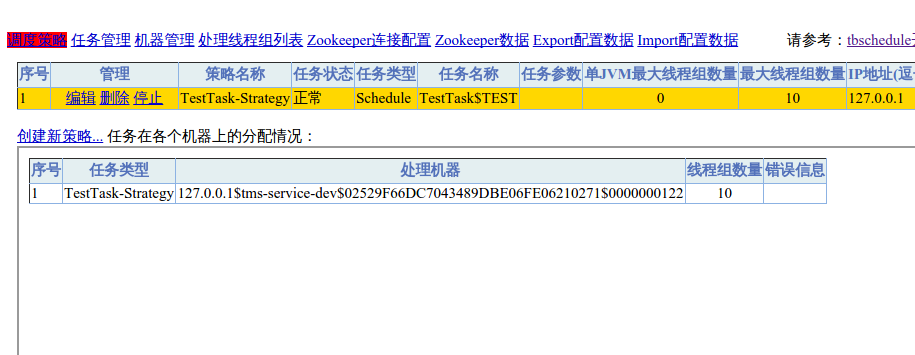
至此tbSchedule控制檯部署完畢。
tbSchedule客戶端編寫
tbSchedule專案的test/目錄下有很多測試類,可以執行
mvn test把測試跑一遍。跑之前要修改專案中schedule.xml檔案正確填寫zookeeper的連線地址。測試跑通則說明tbSchedule管理控制檯和zookeeper都部署無誤。
當我們要執行一個job時,需要建立新專案,引入tbschedule依賴,實現指定介面,然後打成jar包,通過
java -jar 你的jar名.jar啟動job。依賴如下:
<groupId>com.taobao.pamirs.schedule</groupId><artifactId>tbschedule</artifactId><version>3.2.16</version>同時別忘了整合spring。
Main方法程式碼如下:
publicstaticvoidmain(String[] args)throwsException{ApplicationContext ctx =newClassPathXmlApplicationContext("spring-config.xml");TBScheduleManagerFactory scheduleManagerFactory =newTBScheduleManagerFactory();Properties p =newProperties();
p.put("zkConnectString","192.168.3.117:2181");
p.put("rootPath","/home/platform/data");
p.put("zkSessionTimeout","60000");
p.put("userName","ScheduleAdmin");
p.put("password","password");
p.put("isCheckParentPath","true");
scheduleManagerFactory.setApplicationContext(ctx);
scheduleManagerFactory.init(p);
scheduleManagerFactory.setZkConfig(convert(p));}執行這個方法後,你的程式就會向zookeeper發起連線,註冊當前機器,請求任務佇列,最後根據排程配置執行job。
job的執行程式碼需要配置成一個spring bean:
<beanid="testTaskBean"class="com.anzhi.schedule.task.TestTaskBean"><propertyname="jdbcTemplate"ref="jdbcTemplate"/></bean>這個bean的骨架如下:
publicclassTestTaskBeanimplementsIScheduleTaskDealSingle<PassportModel>{/**
* 選擇任務. 從DB中讀取資料, 將取出的資料返回
* @param taskParameter
* @param ownSign
* @param taskItemNum
* @param taskItemList
* @param eachFetchDataNum
* @return
* @throws Exception
*/publicList<PassportModel> selectTasks(String taskParameter,String ownSign,int taskItemNum,List<TaskItemDefine> taskItemList,int eachFetchDataNum)throwsException{List<PassportModel>list=newArrayList<PassportModel>(1);list.add(newPassportModel());returnlist;}/**
* 向目標表中插入資料
* @param model
* @param ownSign
* @return
* @throws Exception
*/publicboolean execute(PassportModel model,String ownSign)throwsException{try{//insertData(model);System.out.println("執行任務");returntrue;}catch(Exception e){
e.printStackTrace();returnfalse;}}}其中泛型引數Passport是我們自定義的類。
tbSchedule的呼叫流程為:
-
執行
selectTasks()方法,該方法返回一個List物件,表示你選擇出的任務列表。 -
執行
execute()方法,tbschedule會遍歷你在selectTasks()方法中返回的List,然後對每一個元素都呼叫execute()方法。
任務排程的配置
進入tbSchedule管理控制檯,建立一個新策略:
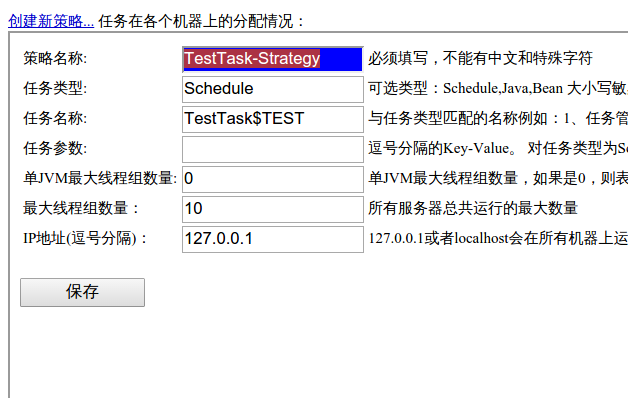
注意,任務名稱格式為建立的任務名$自定義字串。其中你自定義的字串會被傳遞到selectTasks()方法中的ownSign引數中。
任務管理 -> 建立新任務:
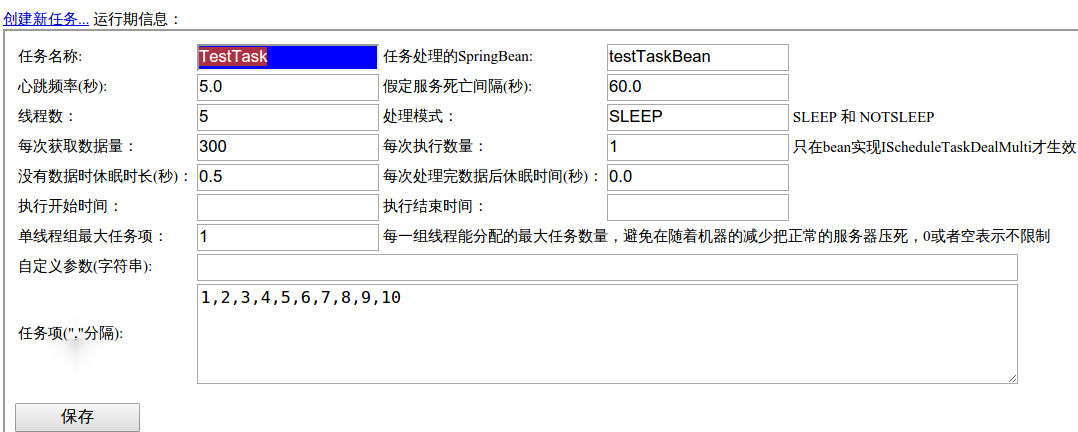
這是對單個job的排程配置資訊。
重要引數說明:
-
任務名稱
-
就是剛才在配置策略時填寫的名稱(
$之前的部分)。
-
就是剛才在配置策略時填寫的名稱(
-
處理模式
-
SLEEP模式- 當某一個執行緒任務處理完畢,從任務池中取不到任務的時候,檢查其它執行緒是否處於活動狀態。如果是,則自己休眠; 如果其它執行緒都已經因為沒有任務進入休眠,當前執行緒是最後一個活動執行緒的時候,就呼叫業務介面,獲取需要處理的任務,放入任務池中, 同時喚醒其它休眠執行緒開始工作。
-
NOTSLEEP模式- 當一個執行緒任務處理完畢,從任務池中取不到任務的時候,立即呼叫業務介面獲取需要處理的任務,放入任務池中。
-
-
任務項
- 一個執行緒組(會有多個執行緒)只執行一個任務。
- 一個任務項只能由一個任務處理器執行
- 任務處理器是一個邏輯性的概念,一個任務處理器只有一個執行緒組。
-
所以可以把任務劃分為1,2,3,4,5,6,7,8, 9, 10一共10個任務碎片,10個任務碎片會被分配到10(剛才在
建立排程策略中配置的)個執行緒組,那麼每個執行緒組對應1個任務碎片,執行時任務項引數又被傳遞到bean任務類selectTasks方法的List queryCondition引數,例如第1個執行緒組呼叫selectTasks方法是queryCondition引數條件為1 ,第2個執行緒組執行引數條件為2。 我們需要在方法中自己解析這個數值,根據值的不同執行不同部分的任務。因為一個執行緒組會有多個執行緒,因此可以實現平行計算。
執行job
完成以上工作後,執行編寫的job客戶端,job即可被排程執行。