
Netty專欄 (七)——— LengthFieldBasedFrameDecoder
LengthFieldBasedFrameDecoder - 引數說明
@author 魯偉林 網上諸多部落格對於LengthFieldBasedFrameDecode解碼器的使用,翻譯和解釋過於死板,難於理解,特別是其建構函式的6個引數的解釋,過於字面化解釋。該部落格儘量保證通俗易懂,幫組讀者理解和使用。讀者可以選擇讀英文文件。 工作量: 1. 詳細講解LengthFieldBasedFrameDecode中6個引數的作用和使用。maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip, failFast。 2. 給出多個例項,幫助理解和使用LengthFieldBasedFrameDecode解碼器。 GitHub專案地址:https://github.com/thinkingfioa/netty-learning/tree/master/netty-private-protocol 部落格地址:https://blog.csdn.net/thinking_fioa Netty專欄地址:https://blog.csdn.net/column/details/22861.html
1. LengthFieldBasedFrameDecoder作用
LengthFieldBasedFrameDecoder解碼器自定義長度解決TCP粘包黏包問題。所以LengthFieldBasedFrameDecoder又稱為: 自定義長度解碼器
1.1 TCP粘包和黏包現象
1. TCP粘包是指傳送方傳送的若干個資料包到接收方時粘成一個包。從接收緩衝區來看,後一個包資料的頭緊接著前一個數據的尾。
2. 當TCP連線建立後,Client傳送多個報文給Server,TCP協議保證資料可靠性,但無法保證Client發了n個包,服務端也按照n個包接收。Client端傳送n個數據包,Server端可能收到n-1或n+1個包。
1.2 為什麼出現粘包現象
1. 傳送方原因: TCP預設會使用Nagle演算法。而Nagle演算法主要做兩件事:1)只有上一個分組得到確認,才會傳送下一個分組;2)收集多個小分組,在一個確認到來時一起傳送。所以,正是Nagle演算法造成了傳送方有可能造成粘包現象。
2. 接收方原因: TCP接收方採用快取方式讀取資料包,一次性讀取多個快取中的資料包。自然出現前一個數據包的尾和後一個收據包的頭粘到一起。
1.3 如何解決粘包現象
1. 新增特殊符號,接收方通過這個特殊符號將接收到的資料包拆分開 - DelimiterBasedFrameDecoder特殊分隔符解碼器
2. 每次傳送固定長度的資料包 - FixedLengthFrameDecoder定長編碼器
3. 在訊息頭中定義長度欄位,來標識訊息的總長度 - LengthFieldBasedFrameDecoder自定義長度解碼器
2. LengthFieldBasedFrameDecoder怎麼使用
1. LengthFieldBasedFrameDecoder本質上是ChannelHandler,一個處理入站事件的ChannelHandler
2. LengthFieldBasedFrameDecoder需要加入ChannelPipeline中,且位於鏈的頭部
3. LengthFieldBasedFrameDecoder - 6個引數解釋
LengthFieldBasedFrameDecoder是自定義長度解碼器,所以建構函式中6個引數,基本都圍繞那個定義長度域,進行的描述。
1. maxFrameLength - 傳送的資料幀最大長度
2. lengthFieldOffset - 定義長度域位於傳送的位元組陣列中的下標。換句話說:傳送的位元組陣列中下標為${lengthFieldOffset}的地方是長度域的開始地方
3. lengthFieldLength - 用於描述定義的長度域的長度。換句話說:傳送位元組陣列bytes時, 位元組陣列bytes[lengthFieldOffset, lengthFieldOffset+lengthFieldLength]域對應於的定義長度域部分
4. lengthAdjustment - 滿足公式: 傳送的位元組陣列bytes.length - lengthFieldLength = bytes[lengthFieldOffset, lengthFieldOffset+lengthFieldLength] + lengthFieldOffset + lengthAdjustment
5. initialBytesToStrip - 接收到的傳送資料包,去除前initialBytesToStrip位
6. failFast - true: 讀取到長度域超過maxFrameLength,就丟擲一個 TooLongFrameException。false: 只有真正讀取完長度域的值表示的位元組之後,才會丟擲 TooLongFrameException,預設情況下設定為true,建議不要修改,否則可能會造成記憶體溢位
7. ByteOrder - 資料儲存採用大端模式或小端模式
程式碼:
public LengthFieldBasedFrameDecoder(
ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset,
int lengthFieldLength,int lengthAdjustment, int initialBytesToStrip,
boolean failFast) {
//...
}劃重點: 參照一個公式寫,肯定沒問題:
公式: 傳送資料包長度 = 長度域的值 + lengthFieldOffset + lengthFieldLength + lengthAdjustment
4. 舉例解釋引數如何寫
客戶端多次傳送"HELLO, WORLD"字串給服務端。"HELLO, WORLD"共12位元組(12B)。長度域中的內容是16進位制的值,如下:
1. 0x000c -----> 12
2. 0x000e -----> 14
4.1 場景1
資料包大小: 14B = 長度域2B + "HELLO, WORLD"

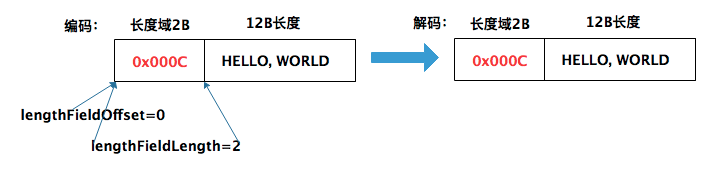
解釋:
如上圖,長度域的值為12B(0x000c)。希望解碼後保持一樣,根據上面的公式,引數應該為:
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment = 0 = 資料包長度(14) - lengthFieldOffset - lengthFieldLength - 長度域的值(12)
4. initialBytesToStrip = 0 - 解碼過程中,沒有丟棄任何資料
4.2 場景2
資料包大小: 14B = 長度域2B + "HELLO, WORLD"


解釋:
上圖中,解碼後,希望丟棄長度域2B欄位,所以,只要initialBytesToStrip = 2即可。其他與場景1相同
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment = 0 = 資料包長度(14) - lengthFieldOffset - lengthFieldLength - 長度域的值(12)
4. initialBytesToStrip = 2 解碼過程中,沒有丟棄2個位元組的資料
4.3 場景3
資料包大小: 14B = 長度域2B + "HELLO, WORLD"。與場景1不同的是:場景3中長度域的值為14(0x000E)

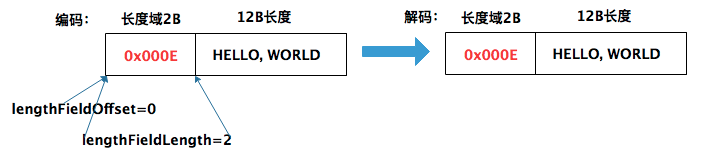
解釋:
如上圖,長度域的值為14(0x000E)。希望解碼後保持一樣,根據上面的公式,引數應該為:
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment = -2 = 資料包長度(14) - lengthFieldOffset - lengthFieldLength - 長度域的值(14)
4. initialBytesToStrip = 0 - 解碼過程中,沒有丟棄任何資料
4.4 場景4
場景4在長度域前新增2個位元組的Header。長度域的值(0x00000C) = 12。總資料包長度: 17=Header(2B) + 長度域(3B) + "HELLO, WORLD" 

解釋
如上圖。編碼解碼後,長度保持一致,所以initialBytesToStrip = 0。引數應該為:
1. lengthFieldOffset = 2
2. lengthFieldLength = 3
3. lengthAdjustment = 0 = 資料包長度(17) - lengthFieldOffset(2) - lengthFieldLength(3) - 長度域的值(12)
4. initialBytesToStrip = 0 - 解碼過程中,沒有丟棄任何資料
4.5 場景5
與場景4不同的地方是: Header與長度域的位置換了。總資料包長度: 17=長度域(3B) + Header(2B) + "HELLO, WORLD" 

解釋
如上圖。編碼解碼後,長度保持一致,所以initialBytesToStrip = 0。引數應該為:
1. lengthFieldOffset = 0
2. lengthFieldLength = 3
3. lengthAdjustment = 2 = 資料包長度(17) - lengthFieldOffset(0) - lengthFieldLength(3) - 長度域的值(12)
4. initialBytesToStrip = 0 - 解碼過程中,沒有丟棄任何資料
4.6 場景6 - 終極複雜案例
如下圖,"HELLO, WORLD"域前有多個欄位。總資料長度: 16 = HEADER1(1) + 長度域(2) + HEADER2(1) + "HELLO, WORLD" 

1. lengthFieldOffset = 1
2. lengthFieldLength = 2
3. lengthAdjustment = 1 = 資料包長度(16) - lengthFieldOffset(1) - lengthFieldLength(2) - 長度域的值(12)
4. initialBytesToStrip = 0 - 解碼過程中,沒有丟棄任何資料
4.7 實際案例
我在專案Netty-private-protocol開發實際使用了LengthFieldBasedFrameDecoder自定義長度編碼器。在訊息Header的前面新增4個位元組(int型),用於表示整個資料包的長度,歡迎一起交流。所以,我的引數是:
1. lengthFieldOffset = 0
2. lengthFieldLength = 4
3. lengthAdjustment = -4 = 資料包長度(msgLen) - lengthFieldOffset(0) - lengthFieldLength(4) - msgLen
4. initialBytesToStrip = 0
5. 總結
請記住公式: 傳送資料包長度 = 長度域的值 + lengthFieldOffset + lengthFieldLength + lengthAdjustment。
參考
- 1. 英文版