
深度學習語言模型的通俗講解(Deep Learning for Language Modeling)
阿新 • • 發佈:2019-01-24
感想
這是臺灣大學Speech Processing and Machine Learning Laboratory的李巨集毅 (Hung-yi Lee)的次課的內容,他的課有大量生動的例子,把原理也剖析得很清楚,感興趣的同學可以去看看,這裡是我對它的一次課的筆記,我覺得講得不錯,把語言模型的過程都講清楚了,例子都很好懂,所以分享給大家。
介紹
語言模型:估計單詞序列的概率值,其中單詞序列為:w1,w2,…,wn。我們要求得概率為P(w1,w2,…,wn)語言模型應用場景:(1)是語音識別,不同的單詞序列可以有相同的發音,我們就可以通過語言模型來進行判斷,如下面的例子


語音識別出現的機率比破壞海灘的機率大,因此輸出就是語音識別。
(2)應用:句子生成(sentence generation),比如你在設計對話系統的時候,現在有好多句子都可以進行迴應,我們就可以用語言模型(language model)選擇文法最對的句子。
傳統的語言模型
N-gram
怎樣估計P(w1,w2,…,wn)?我們可以收集很大的文字資料作為訓練集,但是有一些單詞序列可能不會出現在訓練集(你自己的語料庫)中。

我們把w1,…,wn拆分成很多個部分,我們計算每一個部分的機率,然後把機率連乘起來,就得到了語言模型序列的概率。其中的start是句子開始的地方認為加上的。例如

然後我們從訓練集中估計,如P(beach)|nice)
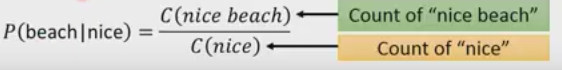
如果計算概率考慮前1個字就是2-gram,考慮前兩個字就是3-gram…….
基於神經網路的語言模型
神經網路的訓練過程很簡單,前期收集一個很大的語料庫
神經網路的輸入和輸出為

然後我們最小化交叉熵,有了神經網路以後,我們來算一個句子的機率,先把句子拆成下面的形式,2-gram的形式。如果我們用神經網路的話,這裡的機率就不是統計出來的,是神經網路預測出來的。

然後我們最小化交叉熵,有了神經網路以後,我們來算一個句子的機率,先把句子拆成下面的形式,2-gram的形式。如果我們用神經網路的話,這裡的機率就不是統計出來的,是神經網路預測出來的。

P(b|a):神經網路預測下一個單詞的機率。
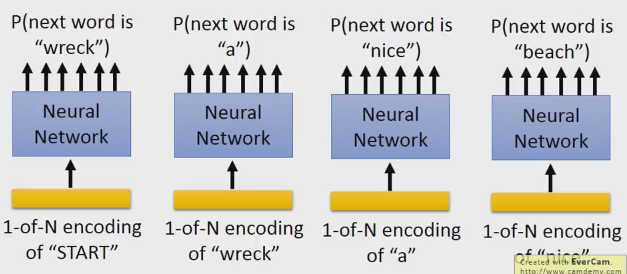
我們需要加一個“start”的token,用1-of-N.然後讓它預測下一個是wreck的機率,然後你把wrech拿出來,用1-of-N編碼wreck,來預測下一個是a的機率。
這裡解釋一下1-of-N就是常說的onehot編碼,把資料用一個向量表示,在向量的維數中,target的那一維是1,其它的維都是0的編碼方式。
基於RNN的語言模型
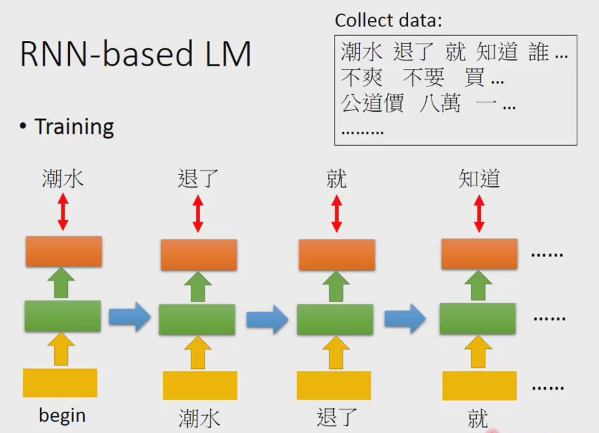
輸入起始後,output就是潮水,輸入潮水後,output就是退了,這樣一直持續下去。
怎樣通過RNN計算P(w1,w2,…,wn)?
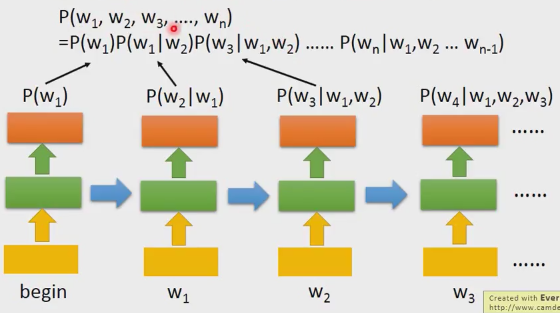
把RNN訓練出來以後,你把begin作為輸出,你就得到p(w1)的機率,你把w1輸進去,你就得到P(w2|w1),以此類推,然後連乘起來,我們就得到句子的機率。RNN可以對long-term資訊進行建模,我們也可以用其它層數更深的RNN或者LSTM模型。
語言模型用神經網路的原因
N-gram的挑戰
最大的問題是,概率估計得不是很精準,特別是n-gram中的n很大的時候,如果需要保證精度的話,那麼我們需要的資料量很大,但是實際上我們不可能活得那麼多訓練資料,資料會變得稀疏。
由於訓練資料集的原因,Dog後面接jumped,cat後面接ran的機率是0,實際上不是真正是0.因為dog是可以jump的,cat是可以ran的。那我們怎麼解決呢?

不要把他們的機率賦值為0,我們給它一個小小的概率,這個叫做smoothing。怎樣把n-gram做好,裡面有很大的學問,不在本文討論範疇,請有興趣的人士查閱相關的資料。
矩陣分解
提到資料稀疏,我們就會想到矩陣分解
如上表格,橫軸代表歷史,縱軸代表詞彙。如圖,cat和jumped對應的單元代表P(jumped|cat),表格大部分的空格是0,其實不是真正的是0,是因為訓練樣例不夠大,導致和0空格對應樣例的訓練資料沒有的緣故。上表可以類比推薦系統,歷史就是使用者,詞彙就是產品…。空格是0,並不代表它以後不會買,以後還是有機率買的,只是因為你統計的數目不夠多,沒有那方面的資料。
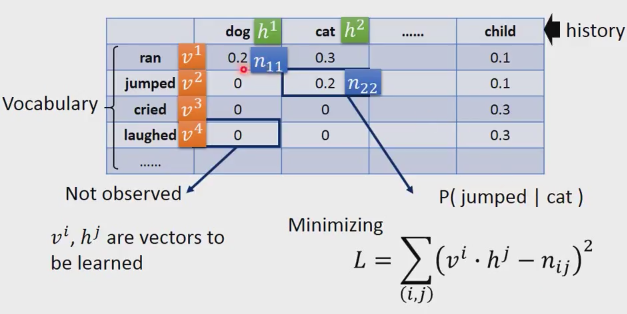
我們把詞彙用v來表示,比如ran就是v1,jumped就是v2等等。History也是一樣用h表示。表格裡的概率值我們用n加兩個下標來表示,第一個就是n11,斜線的第二個就是n22.
V和h是向量,是學出來的。
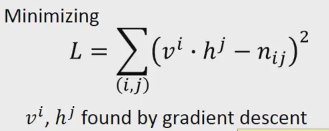
你想求的是當vi和vj做內積的時候,跟nij越接近越好。比如說v1和h1做內積的時候,跟n11越接近越好。
通過上面的訓練,你就可以把上面table中為0的值算出來,通過如下的計算公式。
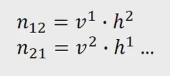
這個有什麼好處呢?

Dog和cat有相近的h dog和h cat。如果v jumped 和h cat的內積很大,那麼v jumped h dog的值也就跟著很大。即使我們的訓練資料集裡面沒有dog jumped的語料。矩陣分解也相當於做了smoothming,不過是自動做的,前面的n-gram的smoothing是人為做的。
矩陣分解(Matric Factorization)是可以寫成神經網路的,
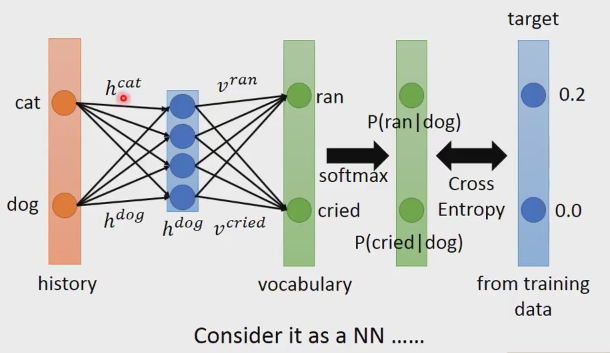
假設dog history寫成上圖hdog的形式,h dog和v ran做內積,h dog和v cried做內積,這樣每個vocabulary就可以得到一數值,這些數值的和你不能當成概率來看,因為他們的和可能不是1,甚至有可能是負的。我們就加一個softmax層,這樣我們就可以得到P(ran|dog)和P(cried|dog)。在訓練的時候,p(ran|dog)的機率是0.2,P(cried|dog)的機率是0,這樣就作為你的訓練目標(target),也就是我們輸入後,網路得到的預測結果和target做cross entropy,我們就最小化這個函式;我們就可以把它想成神經網路。我們的input的就是history,input的大小就是history的大小。Input和上圖h dog相連線的權重,就是h cat, h dog.假設input的編碼方式是1-of-N的編碼。
原因:n-gram是暴力的方法,引數很多,神經網路引數很少。
語言模型用RNN的原因
引數能進一步減少。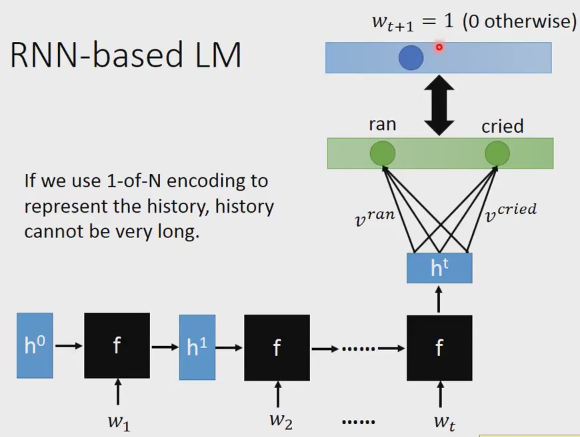
考慮前t個詞彙,詞把w1作為輸入產生h1,w2作為輸入產生h2,…,wt輸進去產生ht, 最後的ht就是這整個history的表達,不管你的history有多長,rnn引數都不會變多。Ht和Vocabulary裡面的每一個word v相乘,你學習的目標詞彙wt+1=1,其它的詞彙就是0,相當於一個one-hot編碼。
參考文獻
[1]. MLDS Lecture 4: Deep Learning forLanguage Modeling.
https://www.youtube.com/watch?v=Jvigef51rqk&index=4&list=PLJV_el3uVTsPMxPbjeX7PicgWbY7F8wW9