
[python] 使用Jieba工具中文分詞及文字聚類概念
阿新 • • 發佈:2019-01-24
一. Selenium爬取百度百科摘要
簡單給出Selenium爬取百度百科5A級景區的程式碼:
內容如下圖所示,共204個國家5A級景點的摘要資訊。這裡就不再敘述:# coding=utf-8 """ Created on 2015-12-10 @author: Eastmount """ import time import re import os import sys import codecs import shutil from selenium import webdriver from selenium.webdriver.common.keys import Keys import selenium.webdriver.support.ui as ui from selenium.webdriver.common.action_chains import ActionChains #Open PhantomJS driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe") #driver = webdriver.Firefox() wait = ui.WebDriverWait(driver,10) #Get the Content of 5A tourist spots def getInfobox(entityName, fileName): try: #create paths and txt files print u'檔名稱: ', fileName info = codecs.open(fileName, 'w', 'utf-8') #locate input notice: 1.visit url by unicode 2.write files #Error: Message: Element not found in the cache - # Perhaps the page has changed since it was looked up #解決方法: 使用Selenium和Phantomjs print u'實體名稱: ', entityName.rstrip('\n') driver.get("http://baike.baidu.com/") elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input") elem_inp.send_keys(entityName) elem_inp.send_keys(Keys.RETURN) info.write(entityName.rstrip('\n')+'\r\n') #codecs不支援'\n'換行 #load content 摘要 elem_value = driver.find_elements_by_xpath("//div[@class='lemma-summary']/div") for value in elem_value: print value.text info.writelines(value.text + '\r\n') #爬取文字資訊 #爬取所有段落<div class='para'>的內容 class='para-title'為標題 [省略] time.sleep(2) except Exception,e: #'utf8' codec can't decode byte print "Error: ",e finally: print '\n' info.close() #Main function def main(): #By function get information path = "BaiduSpider\\" if os.path.isdir(path): shutil.rmtree(path, True) os.makedirs(path) source = open("Tourist_spots_5A_BD.txt", 'r') num = 1 for entityName in source: entityName = unicode(entityName, "utf-8") if u'故宮' in entityName: #else add a '?' entityName = u'北京故宮' name = "%04d" % num fileName = path + str(name) + ".txt" getInfobox(entityName, fileName) num = num + 1 print 'End Read Files!' source.close() driver.close() if __name__ == '__main__': main()
二. Jieba中文分詞
Python中分分詞工具很多,包括盤古分詞、Yaha分詞、Jieba分詞等。
中文分詞庫:http://www.oschina.net/project/tag/264/segment
其中它們的基本用法都相差不大,但是Yaha分詞不能處理如“黃琉璃瓦頂”或“圜丘壇”等詞,所以使用了結巴分詞。
1.安裝及入門介紹
參考地址:http://www.oschina.net/p/jieba
下載地址:https://pypi.python.org/pypi/jieba/
Python 2.0我推薦使用"pip install jieba"或"easy_install jieba"全自動安裝,再通過import jieba來引用(第一次import時需要構建Trie樹,需要等待幾秒時間)。
安裝時如果出現錯誤"unknown encoding: cp65001",輸入"chcp 936"將編碼方式由utf-8變為簡體中文gbk。
結巴中文分詞涉及到的演算法包括:
(1) 基於Trie樹結構實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖(DAG);
(2) 採用了動態規劃查詢最大概率路徑, 找出基於詞頻的最大切分組合;
(3) 對於未登入詞,採用了基於漢字成詞能力的HMM模型,使用了Viterbi演算法。
結巴中文分詞支援的三種分詞模式包括:
(1) 精確模式:試圖將句子最精確地切開,適合文字分析;
(2) 全模式:把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義問題;
(3) 搜尋引擎模式:在精確模式的基礎上,對長詞再次切分,提高召回率,適合用於搜尋引擎分詞。
同時結巴分詞支援繁體分詞和自定義字典方法。
#encoding=utf-8
import jieba
#全模式
text = "我來到北京清華大學"
seg_list = jieba.cut(text, cut_all=True)
print u"[全模式]: ", "/ ".join(seg_list)
#精確模式
seg_list = jieba.cut(text, cut_all=False)
print u"[精確模式]: ", "/ ".join(seg_list)
#預設是精確模式
seg_list = jieba.cut(text)
print u"[預設模式]: ", "/ ".join(seg_list)
#新詞識別 “杭研”並沒有在詞典中,但是也被Viterbi演算法識別出來了
seg_list = jieba.cut("他來到了網易杭研大廈")
print u"[新詞識別]: ", "/ ".join(seg_list)
#搜尋引擎模式
seg_list = jieba.cut_for_search(text)
print u"[搜尋引擎模式]: ", "/ ".join(seg_list) 程式碼中函式簡單介紹如下:
程式碼中函式簡單介紹如下:jieba.cut():第一個引數為需要分詞的字串,第二個cut_all控制是否為全模式。
jieba.cut_for_search():僅一個引數,為分詞的字串,該方法適合用於搜尋引擎構造倒排索引的分詞,粒度比較細。
其中待分詞的字串支援gbk\utf-8\unicode格式。返回的結果是一個可迭代的generator,可使用for迴圈來獲取分詞後的每個詞語,更推薦使用轉換為list列表。
2.新增自定義詞典
由於"國家5A級景區"存在很多旅遊相關的專有名詞,舉個例子:
[輸入文字] 故宮的著名景點包括乾清宮、太和殿和黃琉璃瓦等
[精確模式] 故宮/的/著名景點/包括/乾/清宮/、/太和殿/和/黃/琉璃瓦/等
[全 模 式] 故宮/的/著名/著名景點/景點/包括/乾/清宮/太和/太和殿/和/黃/琉璃/琉璃瓦/等
顯然,專有名詞"乾清宮"、"太和殿"、"黃琉璃瓦"(假設為一個文物)可能因分詞而分開,這也是很多分詞工具的又一個缺陷。但是Jieba分詞支援開發者使用自定定義的詞典,以便包含jieba詞庫裡沒有的詞語。雖然結巴有新詞識別能力,但自行新增新詞可以保證更高的正確率,尤其是專有名詞。
基本用法:jieba.load_userdict(file_name) #file_name為自定義詞典的路徑
詞典格式和dict.txt一樣,一個詞佔一行;每一行分三部分,一部分為詞語,另一部分為詞頻,最後為詞性(可省略,ns為地點名詞),用空格隔開。
強烈推薦一篇詞性標註文章,連結如下:
http://www.hankcs.com/nlp/part-of-speech-tagging.html
#encoding=utf-8
import jieba
#匯入自定義詞典
jieba.load_userdict("dict.txt")
#全模式
text = "故宮的著名景點包括乾清宮、太和殿和黃琉璃瓦等"
seg_list = jieba.cut(text, cut_all=True)
print u"[全模式]: ", "/ ".join(seg_list)
#精確模式
seg_list = jieba.cut(text, cut_all=False)
print u"[精確模式]: ", "/ ".join(seg_list)
#搜尋引擎模式
seg_list = jieba.cut_for_search(text)
print u"[搜尋引擎模式]: ", "/ ".join(seg_list)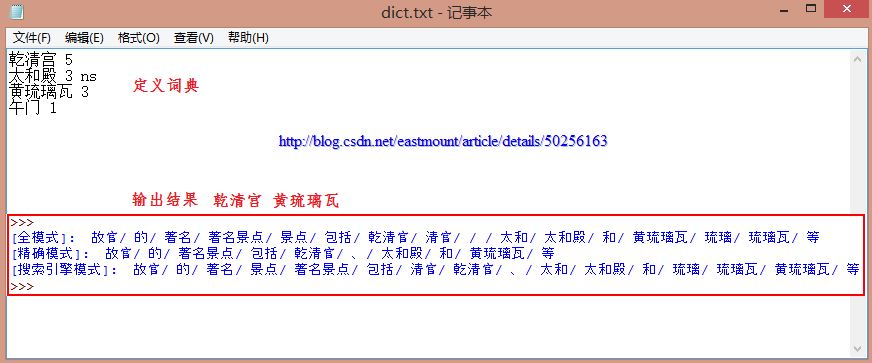
3.關鍵詞提取
在構建VSM向量空間模型過程或者把文字轉換成數學形式計算中,你需要運用到關鍵詞提取的技術,這裡就再補充該內容,而其他的如詞性標註、並行分詞、獲取詞位置和搜尋引擎就不再敘述了。
基本方法:jieba.analyse.extract_tags(sentence, topK)
需要先import jieba.analyse,其中sentence為待提取的文字,topK為返回幾個TF/IDF權重最大的關鍵詞,預設值為20。
#encoding=utf-8
import jieba
import jieba.analyse
#匯入自定義詞典
jieba.load_userdict("dict.txt")
#精確模式
text = "故宮的著名景點包括乾清宮、太和殿和午門等。其中乾清宮非常精美,午門是紫禁城的正門,午門居中向陽。"
seg_list = jieba.cut(text, cut_all=False)
print u"分詞結果:"
print "/".join(seg_list)
#獲取關鍵詞
tags = jieba.analyse.extract_tags(text, topK=3)
print u"關鍵詞:"
print " ".join(tags)>>>
分詞結果:
故宮/的/著名景點/包括/乾清宮/、/太和殿/和/午門/等/。/其中/乾清宮/非常/精美/,/午門/是/紫禁城/的/正門/,/午門/居中/向陽/。
關鍵詞:
午門 乾清宮 著名景點
>>> 4.對百度百科獲取摘要分詞
從BaiduSpider檔案中讀取0001.txt~0204.txt檔案,分別進行分詞處理再儲存。
#encoding=utf-8
import sys
import re
import codecs
import os
import shutil
import jieba
import jieba.analyse
#匯入自定義詞典
jieba.load_userdict("dict_baidu.txt")
#Read file and cut
def read_file_cut():
#create path
path = "BaiduSpider\\"
respath = "BaiduSpider_Result\\"
if os.path.isdir(respath):
shutil.rmtree(respath, True)
os.makedirs(respath)
num = 1
while num<=204:
name = "%04d" % num
fileName = path + str(name) + ".txt"
resName = respath + str(name) + ".txt"
source = open(fileName, 'r')
if os.path.exists(resName):
os.remove(resName)
result = codecs.open(resName, 'w', 'utf-8')
line = source.readline()
line = line.rstrip('\n')
while line!="":
line = unicode(line, "utf-8")
seglist = jieba.cut(line,cut_all=False) #精確模式
output = ' '.join(list(seglist)) #空格拼接
print output
result.write(output + '\r\n')
line = source.readline()
else:
print 'End file: ' + str(num)
source.close()
result.close()
num = num + 1
else:
print 'End All'
#Run function
if __name__ == '__main__':
read_file_cut()
5.去除停用詞
在資訊檢索中,為節省儲存空間和提高搜尋效率,在處理自然語言資料(或文字)之前或之後會自動過濾掉某些字或詞,這些字或詞即被稱為Stop Words(停用詞)。這些停用詞都是人工輸入、非自動化生成的,生成後的停用詞會形成一個停用詞表。但是,並沒有一個明確的停用詞表能夠適用於所有的工具。甚至有一些工具是明確地避免使用停用詞來支援短語搜尋的。[參考百度百科]
#encoding=utf-8
import jieba
#去除停用詞
stopwords = {}.fromkeys(['的', '包括', '等', '是'])
text = "故宮的著名景點包括乾清宮、太和殿和午門等。其中乾清宮非常精美,午門是紫禁城的正門。"
segs = jieba.cut(text, cut_all=False)
final = ''
for seg in segs:
seg = seg.encode('utf-8')
if seg not in stopwords:
final += seg
print final
#輸出:故宮著名景點乾清宮、太和殿和午門。其中乾清宮非常精美,午門紫禁城正門。
seg_list = jieba.cut(final, cut_all=False)
print "/ ".join(seg_list)
#輸出:故宮/ 著名景點/ 乾清宮/ 、/ 太和殿/ 和/ 午門/ 。/ 其中/ 乾清宮/ 非常/ 精美/ ,/ 午門/ 紫禁城/ 正門/ 。三. 基於VSM的文字聚類演算法
這部分主要參考2008年上海交通大學姚清壇等《基於向量空間模型的文字聚類演算法》的論文,因為我的實體對齊使用InfoBox存在很多問題,發現對齊中會用到文字內容及聚類演算法,所以簡單講述下文章一些知識。
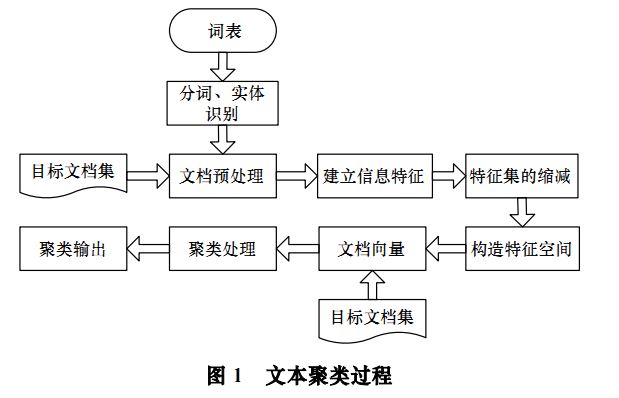 文字聚類的主要依據聚類假設是:同類的文件相似度較大,而非同類文件相似度較小。同時使用無監督學習方法,聚類不需要訓練過程以及不需要預先對文件手工標註類別,因此具有較高的靈活性和自動化處理能力。主要分為以下部分:
文字聚類的主要依據聚類假設是:同類的文件相似度較大,而非同類文件相似度較小。同時使用無監督學習方法,聚類不需要訓練過程以及不需要預先對文件手工標註類別,因此具有較高的靈活性和自動化處理能力。主要分為以下部分:(1) 預處理常用方法
文字資訊預處理(詞性標註、語義標註),構建統計詞典,對文字進行詞條切分,完成文字資訊的分詞過程。
(2) 文字資訊的特徵表示
採用方法包括布林邏輯型、概率型、混合型和向量空間模型。其中向量空間模型VSM(Vector Space Model)是將文件對映成向量的形式,(T1, T2, ..., Tn)表示文件詞條,(W1, W2, ..., Wn)文件詞條對應權重。建立文字特徵主要用特徵項或詞條來表示目標文字資訊,構造評價函式來表示詞條權重,盡最大限度區別不同的文件。
(3) 文字資訊特徵縮減
VSM文件特徵向量維數眾多。因此,在文字進行聚類之前,應用文字資訊特徵集進行縮減,針對每個特徵詞的權重排序,選取最佳特徵,包括TF-IDF。推薦向量稀疏表示方法,提升聚類的效果,其中(D1, D2, ..., Dn)表示權重不為0的特徵詞條。
(4) 文字聚類
文字內容表示成數學課分析形勢後,接下來就是在此數學基礎上進行文字聚類。包括基於概率方法和基於距離方法。其中基於概率是利用貝葉斯概率理論,概率分佈方式;基於聚類是特徵向量表示文件(文件看成一個點),通過計算點之間的距離,包括層次聚類法和平面劃分法。
後面我可能也會寫具體的Python聚類演算法,VSM計算相似度我前面已經講過。同時,他的實驗資料是搜狐中心的10個大類,包括汽車、財經、IT、體育等,而我的資料都是旅遊,如何進一步聚類劃分,如山川、河流、博物館等等,這是另一個難點。
最後還是那句話:不論如何,希望文章對你有所幫助,如果文章中有錯誤或不足之處,還請海涵~寫文不易,且看且分析。加油!!!
(By:Eastmount 2015-12-11 深夜3點 http://blog.csdn.net/eastmount/)