
python中使用jieba進行中文分詞
原始碼下載的地址:https://github.com/fxsjy/jieba
演示地址:http://jiebademo.ap01.aws.af.cm/
一 “結巴”中文分詞:做最好的 Python 中文分片語件 。
- 支援三種分詞模式:
- 精確模式,試圖將句子最精確地切開,適合文字分析;
- 全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義;
- 搜尋引擎模式,在精確模式的基礎上,對長詞再次切分,提高召回率,適合用於搜尋引擎分詞。
- 支援繁體分詞
- 支援自定義詞典
- MIT 授權協議
二 Jieba中文分片語件,可用於中文句子/詞性分割、詞性標註、未登入詞識別,支援使用者詞典等功能。該元件的分詞精度達到了97%以上。下載介紹在Python裡安裝Jieba。
1. 安裝方式一:
2)安裝 D:\>cd D:\Download\jieba-0.39
D:\Download\jieba-0.39>python setup.py install
2. 安裝方式二:
三 原理及演算法
1)基於Trie樹結構實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖(DAG) 2)採用了動態規劃查詢最大概率路徑, 找出基於詞頻的最大切分組合
3)對於未登入詞,採用了基於漢字成詞能力的HMM模型,使用了Viterbi演算法
4)從原始碼的角度分為三部分對jieba中文分詞進行分析,
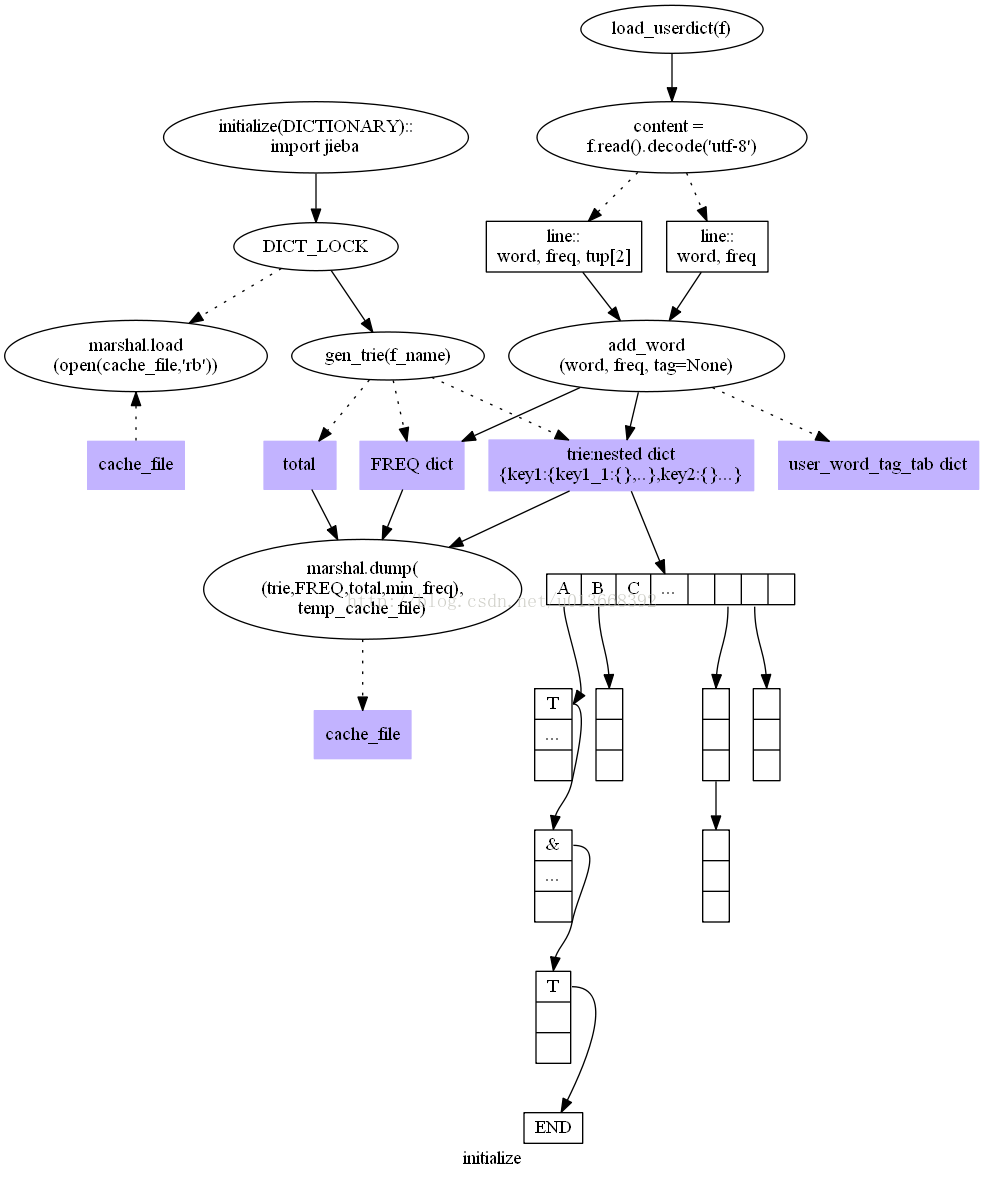
第一部分 Jieba分詞的初始化,包括核心詞典和使用者詞典的載入,這一部分涉及最基礎的資料結構,有:
trie又稱字首樹或字典樹,jieba中的具體實現是一個巢狀的dict,它用於儲存詞典;
FREQ在jieba中的具體實現是一個dict,它儲存詞和詞頻的對應關係;
min_freq儲存最小的詞頻;
total儲存所有詞的詞頻的總和。
第二部分 DAG和動態規劃演算法
第三部分 介紹 jieba 中文分片語件中的HMM模型和Viterbi演算法應用
四 實踐例子
1. example 1:分詞
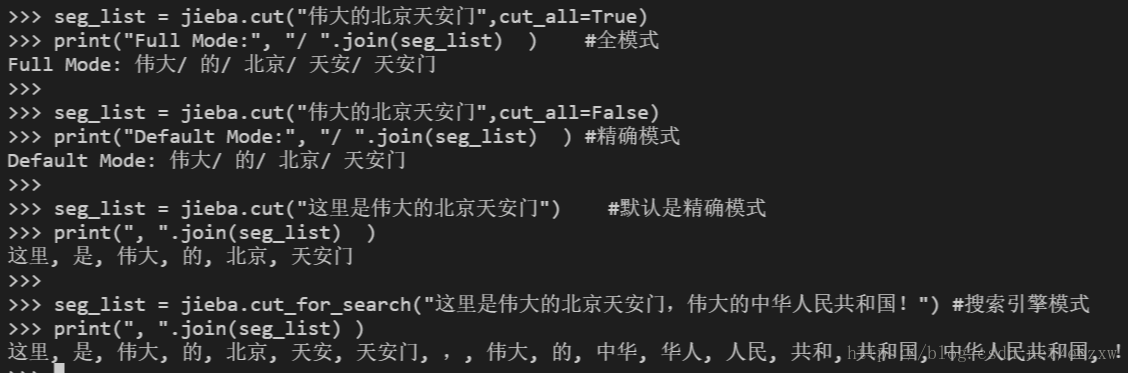
#encoding=utf-8 import jieba seg_list = jieba.cut("偉大的北京天安門",cut_all=True) print("Full Mode:", "/ ".join(seg_list) ) #全模式 seg_list = jieba.cut("偉大的北京天安門",cut_all=False) print("Default Mode:", "/ ".join(seg_list) ) #精確模式 seg_list = jieba.cut("這裡是偉大的北京天安門") #預設是精確模式 print(", ".join(seg_list) ) seg_list = jieba.cut_for_search("這裡是偉大的北京天安門,偉大的中華人民共和國!") #搜尋引擎模式 print(", ".join(seg_list) )
jieba.cut方法接受兩個輸入引數: 1) 第一個引數為需要分詞的字串 2)cut_all引數用來控制是否採用全模式 jieba.cut_for_search方法接受一個引數:需要分詞的字串,該方法適合用於搜尋引擎構建倒排索引的分詞,粒度比較細 注意:待分詞的字串可以是gbk字串、utf-8字串或者unicode
jieba.cut以及jieba.cut_for_search返回的結構都是一個可迭代的generator,可以用list(jieba.cut(...))轉化為list ,
也可以使用for迴圈來獲得分詞後得到的每一個詞語(unicode)。
2. example 2:使用字定義詞典
可以指定自己自定義的詞典,以便包含jieba詞庫裡沒有的詞。
雖然jieba有新詞識別能力,但是自行新增新詞可以保證更高的正確率 。
注意: 自定義詞典不要用Windows記事本儲存,這樣會加入BOM標誌,導致第一行的詞被誤讀。
- jieba.load_userdict(file_name) # file_name為自定義詞典的路徑
詞典格式:一個詞佔一行;每一行分三部分,一部分為詞語,一部分為詞頻,最後為詞性(可省略),用空格隔開
驗證下來,這裡詞典裡面的詞頻主要是是為解決歧義而設定的,用於計算成詞的組合概率
,如下userdict.txt
- 雲端計算 5
- 李小福 2 nr
- 創新辦 3 i
- easy_install 3 eng
- 好用 300
- 韓玉賞鑑 3 nz
具體程式碼:
#encoding=utf-8
import sys
sys.path.append("../")
import jieba
import jieba.posseg as pseg
test_sent = "李小福是創新辦主任也是雲端計算方面的專家;"
test_sent += "例如我輸入一個帶“韓玉賞鑑”的標題,在自定義詞庫中也增加了此詞為N型別,python 的正則表示式是好用的"
print("\n====下面結果未自定義詞典====")
words = jieba.cut(test_sent)
print("Result words:", "/ ".join(words) )
print("\n====下面是自定義userdict分詞====")
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print("Result words:", "/ ".join(words) ) 輸出結果如下,可以看到使用自定義字典的前後差異:

這方面的參考有: "通過使用者自定義詞典來增強歧義糾錯能力" --- https://github.com/fxsjy/jieba/issues/14
3. 詞性標註
標註句子分詞後每個詞的詞性,採用和ictclas相容的標記法
ICTCLAS 漢語詞性標註集 詳細參考https://blog.csdn.net/ebzxw/article/details/80306463
用法示例:
import jieba.posseg as pseg
test_sent = "李小福是創新辦主任也是雲端計算方面的專家;"
test_sent += "例如我輸入一個帶“韓玉賞鑑”的標題,在自定義詞庫中也增加了此詞為N型別,python 的正則表示式是好用的"
result = pseg.cut(test_sent)
for w in result:
print(w.word, "/", w.flag, ", ",)
print("\n========")
4. 關鍵詞提取
核心呼叫方法:jieba.analyse.extract_tags(sentence,topK) #需要先import jieba.analyse
sentence為待提取的文字 , topK為返回幾個TF/IDF權重最大的關鍵詞,預設值為20
用法程式碼示例:#encoding=utf-8
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags.py [file name] -k [top k]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
#'''
if len(args) < 1:
print(USAGE)
sys.exit(1)
#'''
file_name = args[0]
#file_name=u"story.txt"
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
tags = jieba.analyse.extract_tags(content, topK=topK)
print(",".join(tags) )
5. 並行分詞
原理:將目標文字按行分隔後,把各行文字分配到多個python程序並行分詞,然後歸併結果,從而獲得分詞速度的可觀提升
基於python自帶的multiprocessing模組,目前暫不支援windows
- jieba.enable_parallel(4) # 開啟並行分詞模式,引數為並行程序數
- jieba.disable_parallel() # 關閉並行分詞模式
實驗結果:在4核3.4GHz Linux機器上,對金庸全集進行精確分詞,獲得了1MB/s的速度,是單程序版的3.3倍。
import urllib2
import sys,time
import sys
sys.path.append("../../")
import jieba
jieba.enable_parallel(4)
url = sys.argv[1]
content = open(url,"rb").read()
t1 = time.time()
words = list(jieba.cut(content))
t2 = time.time()
tm_cost = t2-t1
log_f = open("1.log","wb")
for w in words:
print >> log_f, w.encode("utf-8"), "/" ,
print 'speed' , len(content)/tm_cost, " bytes/second" 6. Tokenize:返回詞語在原文的起始位置(輸入引數只接受unicode)
#預設模式
result = jieba.tokenize(u'永和服裝飾品有限公司')
for tk in result:
print "word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2])

#搜尋模式
result = jieba.tokenize(u'永和服裝飾品有限公司',mode='search')
for tk in result:
print "word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]) 
7. ChineseAnalyzer for Whoosh搜尋引擎
引用: from jieba.analyse import ChineseAnalyzer用法示例:https://github.com/fxsjy/jieba/blob/master/test/test_whoosh.py8. 命令列分詞
使用示例:python -m jieba news.txt > cut_result.txt
命令列選項(翻譯):
使用: python -m jieba [options] filename
結巴命令列介面。
固定引數:
filename 輸入檔案
可選引數:
-h, --help 顯示此幫助資訊並退出
-d [DELIM], --delimiter [DELIM]
使用 DELIM 分隔詞語,而不是用預設的' / '。
若不指定 DELIM,則使用一個空格分隔。
-p [DELIM], --pos [DELIM]
啟用詞性標註;如果指定 DELIM,詞語和詞性之間
用它分隔,否則用 _ 分隔
-D DICT, --dict DICT 使用 DICT 代替預設詞典
-u USER_DICT, --user-dict USER_DICT
使用 USER_DICT 作為附加詞典,與預設詞典或自定義詞典配合使用
-a, --cut-all 全模式分詞(不支援詞性標註)
-n, --no-hmm 不使用隱含馬爾可夫模型
-q, --quiet 不輸出載入資訊到 STDERR
-V, --version 顯示版本資訊並退出
如果沒有指定檔名,則使用標準輸入。
--help 選項輸出:
$> python -m jieba --help
Jieba command line interface.
positional arguments:
filename input file
optional arguments:
-h, --help show this help message and exit
-d [DELIM], --delimiter [DELIM]
use DELIM instead of ' / ' for word delimiter; or a
space if it is used without DELIM
-p [DELIM], --pos [DELIM]
enable POS tagging; if DELIM is specified, use DELIM
instead of '_' for POS delimiter
-D DICT, --dict DICT use DICT as dictionary
-u USER_DICT, --user-dict USER_DICT
use USER_DICT together with the default dictionary or
DICT (if specified)
-a, --cut-all full pattern cutting (ignored with POS tagging)
-n, --no-hmm don't use the Hidden Markov Model
-q, --quiet don't print loading messages to stderr
-V, --version show program's version number and exit
If no filename specified, use STDIN instead.
9.延遲載入機制
jieba 採用延遲載入,import jieba 和 jieba.Tokenizer() 不會立即觸發詞典的載入,一旦有必要才開始載入詞典構建字首字典。如果你想手工初始 jieba,也可以手動初始化。
import jieba
jieba.initialize() # 手動初始化(可選)
在 0.28 之前的版本是不能指定主詞典的路徑的,有了延遲載入機制後,你可以改變主詞典的路徑:
jieba.set_dictionary('data/dict.txt.big')
其他詞典:
下載你所需要的詞典,然後覆蓋 jieba/dict.txt 即可;或者用 jieba.set_dictionary('data/dict.txt.big')
五 遺留問題
1. 使用 jieba.load_userdict() 自定義詞典,每一行為詞語、詞頻、詞性。 這裡詞頻在程式碼裡怎麼使用,什麼變數來表示。詞頻一般設多大。