
分批次插入mysql:一次性插入mysql兩萬以上資料造成資料庫假死
專案距離上線的日期越來越近了,需要規範一下資料庫中的資料,就需要從前端頁面上匯入系統資料到mysql資料庫。匯入3萬資料,期間會有校驗,最後分別插入到四張表中,本庫插入3張表,雲平臺插入一張表,執行到一半的時候就前端頁面假死了,最後通過分批插入資料解決問題,以下是實驗並解決的過程。
1.實驗條件
筆記本型號:戴爾,I3處理器,12G記憶體條
2.專案框架
本專案為前後端分離。
前端:Angular
後端:SSM+Dubbo+Mysql資料庫
3.實驗過程
插入資料庫的是批量的插入,最後的sql語句類似於insert into t_test (cloumn_a,cloumn_b) values(1,2),(3,4),(5,6).
①一次性批量插入資料庫(四張表)
結果:dubbo超時,由於中間需要有其他的操作,例如,學號重複的校驗,身份證號的校驗等,導致還沒有到插入資料庫的一步就已經dubbo超時了,我們設定的dubbo超時時間是3s.
②一次性批量插入資料庫(單表插入)
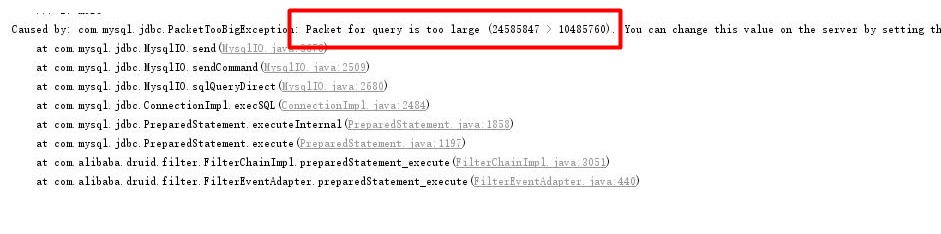
我們將dubbo超時時間設定到保證不會超時,如10min,mysql報錯,意思為傳輸的資料包太大了,超過了資料庫配置的可接收的最大值.
使用命令連線mysql,使用命令檢視mysql的配置:show VARIABLES like '%max_allowed_packet%';發現太小,然後設定的大一點,設定為20M,set global max_allowed_packet = 2*1024*1024*10
將學號重複的校驗去掉,其中會為每條資料設定UUID(業務需要),測試資料量是3W,結果是可以入庫,資料量大小是4.8min左右.
③公共方法tool中分批次1000一批次(單表插入)
我們將dubbo超時時間設定到保證不會超時,如10min,將學號重複的校驗去掉,其中會為每條資料設定UUID(業務需要),測試資料量是3W,結果是可以入庫,資料量大小是4min左右.
④除去入庫和和學號校驗,基礎程式碼迴圈設定uuid
結果:1min
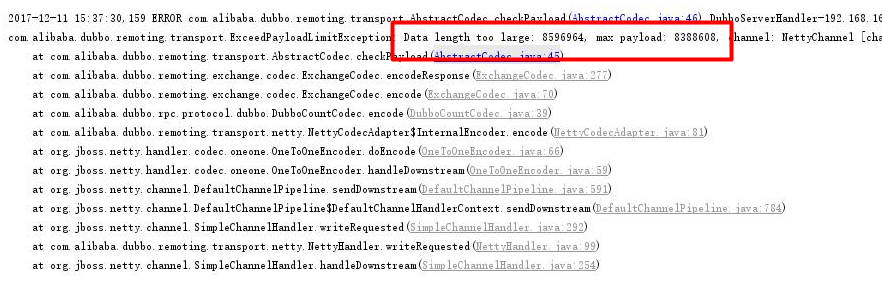
⑤除去學號校驗,入庫4張表,基礎程式碼迴圈設定uuid
dubbo報錯,dubbo不支援這麼大的資料包
4.解決方法
在自己業務處理的程式碼中同樣分批處理,分批處理的程式碼如下:private static int batchCount=500; //500條資料一批次@Override
@Transactional(rollbackFor = Exception.class)
public int insertAll(List<T> records) {
int result = 0;
if (records != null) {
int recCount = records.size();
if (recCount > 0 && recCount <= batchCount) {
for (T record : records) {
wrapBaseEntity(record);
}
result = getRealDao().insertAll(records);
}
if (recCount > batchCount) {
int times = recCount / batchCount;
int residue = recCount % batchCount;
if (residue > 0) {
times = times + 1;
}
for (int i = 0; i < times; i++) {
if (i == times - 1) {
for (T record : records.subList(batchCount * i, recCount)) {
wrapBaseEntity(record);
}
result = result + getRealDao().insertAll(records.subList(batchCount * i, recCount));
} else {
for (T record : records.subList(batchCount * i, batchCount * (i + 1))) {
wrapBaseEntity(record);
}
result = result + getRealDao().insertAll(records.subList(batchCount * i, batchCount * (i + 1)));
}
}
}
}
return result;
}