
機器學習 使用python+OpenCV實現knn演算法手寫數字識別
阿新 • • 發佈:2019-01-24
基本上照搬了http://lib.csdn.net/article/opencv/30167的程式碼,只是改了一點bug和增加了一點功能
輸入就是直接在一個512*512大小的白色畫布上畫黑線,然後轉化為01矩陣,用knn演算法找訓練資料中最相近的k個,現在應該是可以對所有字元進行訓練和識別,只是訓練資料中還只有數字而已,想識別更多更精確的話就需要自己多跑程式碼多寫幾百次,現在基本上一個數字寫10次左右準確率就挺高了,並且每次識別的時候會將此次識別的數字和01矩陣存入訓練資料資料夾中,增加以後識別的正確率,識別錯了的話需要輸入正確答案來擴充訓練資料
/*--------------------------------------------------之前忘了說畫完按回車了--------------------------*/
這是效果圖:
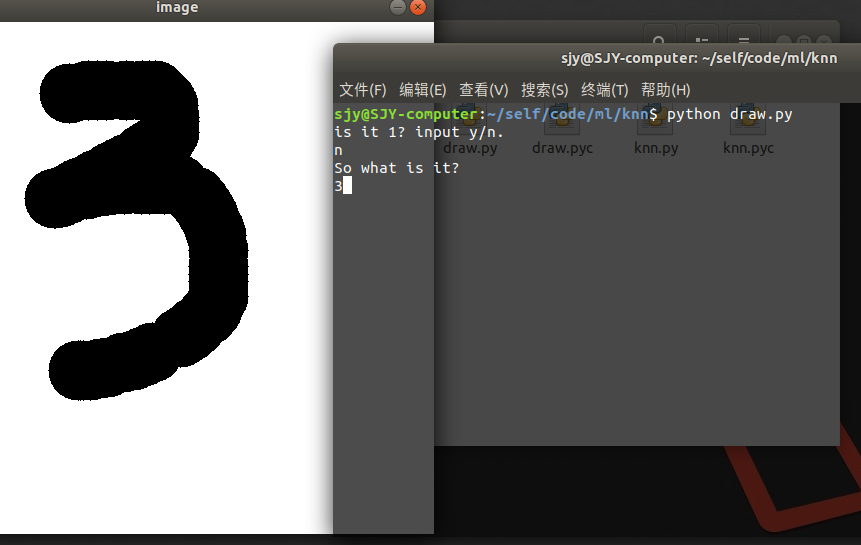
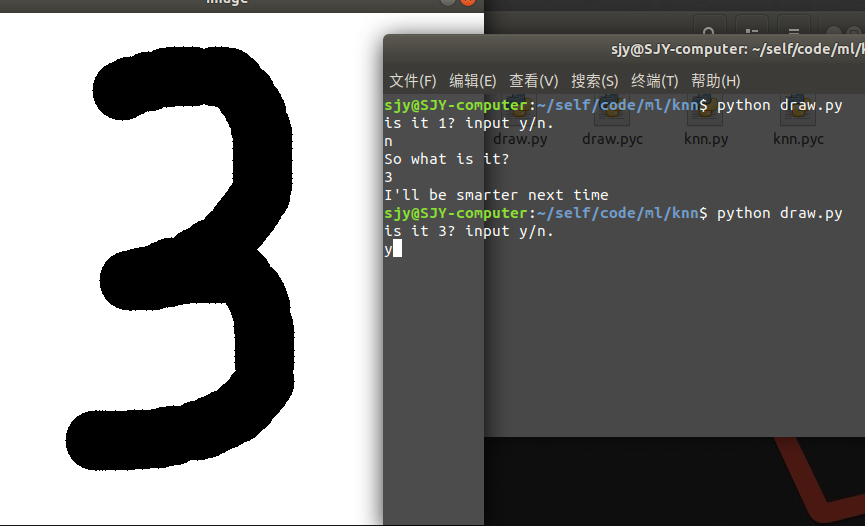
這是程式碼
knn.py
draw.pyfrom numpy import * import operator import time from os import listdir def classify(inputPoint,dataSet,labels,k): dataSetSize = dataSet.shape[0] diffMat = tile(inputPoint,(dataSetSize,1))-dataSet sqDiffMat = diffMat ** 2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances ** 0.5 sortedDistIndicies = distances.argsort() classCount = {} for i in range(k): voteIlabel = labels[ sortedDistIndicies[i] ] classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) return sortedClassCount[0][0] def img2vector(filename): returnVect = [] fr = open(filename) for i in range(32): lineStr = fr.readline() for j in range(32): returnVect.append(int(lineStr[j])) return returnVect def classnumCut(fileName): fileStr = fileName.split('.')[0] classNumStr = fileStr.split('_')[0] return classNumStr def trainingDataSet(): hwLabels = [] trainingFileList = listdir('trainingDigits') m = len(trainingFileList) trainingMat = zeros((m,1024)) for i in range(m): fileNameStr = trainingFileList[i] hwLabels.append(classnumCut(fileNameStr)) trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr) #print type(trainingMat) return hwLabels,trainingMat
#encoding:utf-8 import cv2 import numpy as np #mouse callback function from knn import * ix,iy=-1,-1 ENTER = 10 drawing = False #建立影象與視窗並將視窗與回撥函式繫結 def in_img(): for i in range(512): img[i,:]=255 cv2.namedWindow('image') cv2.setMouseCallback('image',draw_circle) while(1): cv2.imshow('image',img) if cv2.waitKey(20)& 0xFF == ENTER: cv2.imwrite( '1.jpg',img) break cv2.destroyAllWindows() def draw_circle(event,x,y,flags,param): global ix,iy,drawing if event==cv2.EVENT_LBUTTONDOWN: drawing=True ix,iy=x,y elif event==cv2.EVENT_MOUSEMOVE: if drawing==True: cv2.circle(img,(x,y),30,(0,0,0),-1) elif event==cv2.EVENT_LBUTTONUP: drawing=False def classnum(fileName): fileStr = fileName.split('.')[0] classNumStr = fileStr.split('_')[0] num = int(fileStr.split('_')[1]) return classNumStr,num def read_image(): img1 = cv2.imread('1.jpg', cv2.IMREAD_GRAYSCALE) res=cv2.resize(img1,(32,32),interpolation=cv2.INTER_CUBIC) cv2.imshow('2',res) pic=[] for i in range(32): for j in range(32): if res[i][j]<=200: res[i][j]=1 else: res[i][j]=0 pic.append(int(res[i][j])) hwLabels,trainingMat = trainingDataSet() classifierResult = classify(pic, trainingMat, hwLabels, 3) a = raw_input('is it '+ str(classifierResult)+'? input y/n.\n') c = 0 if a == 'n' or a == 'N': b = raw_input('So what is it?\n') trainingFileList = listdir('trainingDigits') m = len(trainingFileList) trainingMat = zeros((m,1024)) for i in range(m): fileNameStr = trainingFileList[i] x,y = classnum(fileNameStr) if x == b: if y > c: c = y c = c+1 newfile = 'trainingDigits/' + str(b)+'_'+str(c)+('.txt') f=open(newfile,'w') for i in range(32): for j in range(32): f.write(str(res[i][j])) f.write("\n") f.close() print "I'll be smarter next time" else: b = str(classifierResult) trainingFileList = listdir('trainingDigits') m = len(trainingFileList) trainingMat = zeros((m,1024)) for i in range(m): fileNameStr = trainingFileList[i] x,y = classnum(fileNameStr) if x == b: if y > c: c = y c = c+1 newfile = 'trainingDigits/' + str(b)+'_'+str(c)+('.txt') f=open(newfile,'w') for i in range(32): for j in range(32): f.write(str(res[i][j])) f.write("\n") f.close() def main(): global img img=np.zeros((512,512,3),np.uint8) in_img() read_image() if __name__=="__main__": main()
這是打包的程式碼和我自己寫的幾十個訓練資料
https://download.csdn.net/download/qq_40051709/10282410