
學習KNN(二)KNN演算法手寫數字識別的OpenCV實現
阿新 • • 發佈:2019-01-03
在OpenCV的安裝檔案路徑/opencv/sources/samples/data/digits.png下,有這樣一張圖:

圖片大小為1000*2000,有0-9的10個數字,每5行為一個數字,總共50行,共有5000個手寫數字,每個數字塊大小為20*20。
為了後續方便處理,我們先寫一段小程式把這5000個圖截取出來:
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
int main()
{
char ad[128]={0};
int filename = 0 擷取之後每個以數字命名的資料夾內就都有500張圖片了,需要注意的是OpenCV的imwrite是沒有自動建立資料夾功能的,所以路徑應該提前存在。
OpenCV提供的KNN演算法建構函式:
C++: CvKNearest::CvKNearest()
C++: CvKNearest::CvKNearest(const Mat& trainData, const Mat& responses, const Mat& sam-
pleIdx=Mat(), bool isRegression=false, int max_k=32 ) 訓練函式為:
C++: bool CvKNearest::train(
const Mat& trainData, //訓練資料
const Mat& responses,//對應的響應值
const Mat& sampleIdx=Mat(),//樣本索引
bool isRegression=false,//是否是迴歸,否則是分類問題
int maxK=32, //最大K值
bool updateBase=false//是否更新資料,是,則maxK需要小於原資料大小 ) 查詢函式為:
C++: float CvKNearest::find_nearest(
const Mat& samples,//按行儲存的測試資料
int k, //K 值
Mat* results=0,//預測結果
const float** neighbors=0, //近鄰指標向量
Mat* neighborResponses=0, //近鄰值
Mat* dist=0 //距離矩陣) const
C++: float CvKNearest::find_nearest(
const Mat& samples,
int k,
Mat& results,
Mat& neighborResponses,
Mat& dists) const 但是由於KNN的特點,其實並沒有train的功能,所以train只是相當於儲存下來訓練樣本,而且會在執行建構函式中執行訓練過程。
在之前,我們已經把5000張圖分別放進了10個資料夾裡了,現在我們把其中的每個類別中前400張拿出來做訓練資料,其餘的測試,程式碼如下:
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/ml/ml.hpp>
using namespace std;
using namespace cv;
char ad[128]={0};
int main()
{
Mat traindata ,trainlabel;
int k=5,testnum=0,truenum=0;
//讀取訓練資料 4000張
for (int i = 0; i < 10; i++)
{
for (int j =0;j<400;j++)
{
sprintf_s(ad, "D:\\data\\%d\\%d.jpg",i,j);
Mat srcimage = imread(ad);
srcimage = srcimage.reshape(1,1);
traindata.push_back(srcimage);
trainlabel.push_back(i);
}
}
traindata.convertTo(traindata,CV_32F);
CvKNearest knn( traindata, trainlabel, cv::Mat(), false, k );
cv::Mat nearests( 1, k, CV_32F);
//讀取測試資料 1000張
for (int i = 0; i < 10; i++)
{
for (int j =400;j<500;j++)
{
testnum++;
sprintf_s(ad, "D:\\data\\%d\\%d.jpg",i,j);
Mat testdata = imread(ad);
testdata = testdata.reshape(1,1);
testdata.convertTo(testdata,CV_32F);
int response = knn.find_nearest(testdata,k,0,0,&nearests,0);
if (response==i)
{
truenum++;
}
}
}
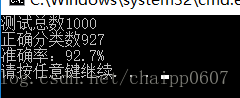
cout<<"測試總數"<<testnum<<endl;
cout<<"正確分類數"<<truenum<<endl;
cout<<"準確率:"<<(float)truenum/testnum*100<<"%"<<endl;
return 0;
}在上述程式碼中,用的特徵就是每個位置的畫素值,一個樣本拉成一維後的列是20*20*3=1200。
最後是一些個人想法,為什麼KNN在手寫數字的資料庫中表現優異,我覺得主要是因為影象較簡單,數字在影象中的位置很規則,都在中間,這兩個特點非常利於KNN做距離的計算。