DC學院資料分析師(入門)學習筆記----高階爬蟲技巧
對於網站來說,實際上是不願意讓大家去爬取它的內容的,因為爬蟲可能會對真實的使用者帶來不太好的影響(很多網站會限制流量,尤其是對爬蟲產生的流量,會對伺服器帶來一定的壓力)。所以網站會對爬蟲有一定的抵制,如果不注意爬蟲的技巧,有可能就被網站封殺IP,以致暫停了。
那麼如何能夠輕鬆繞過部分的反爬蟲限制,書寫我們的爬蟲呢??
1.設定程式休止時間
連續不斷的進行爬蟲的抓取,就會被網站監測出來是一個爬蟲程式。所以,我們應該在能夠接受的速度內,儘量降低一下自己爬取的頻率(中間停1-5秒,再去爬下一個),以免對這些網站產生不必要的影響,這樣做也對網站的負荷會比較好。
n
import time
time.sleep(n)
2.設定代理
設定代理的原因主要有兩個:
①、有時候需要爬取的網站,通過我們的網路IP沒有辦法去進行訪問。所以需要設定代理。如:在教育網裡訪問外網的網站;國內的IP有時候無法訪問國外的網站等。
②、有時候,不管我們怎麼設定我們的爬取頻率,在爬取如新浪微博、Facebook等這些很成熟的網站的時候,這些網站的反爬蟲技術很高超,所以會很快的檢測到我們的機器爬蟲程式,從而會把我們登入訪問的ip地址封掉。比如針對facebook,它會禁止這個ip地址再去訪問它的網站,即使我們重新啟動爬蟲,從無論是正常從瀏覽器訪問還是爬蟲訪問,Facebook
那麼,通過代理伺服器如何進行呢??
傳統:通常直接使用我們的電腦去訪問網頁。
通過代理伺服器:我們傳送一個網路的請求,會首先發送到代理伺服器上,代理伺服器再把這個請求轉發到網頁所在的網站伺服器。網站伺服器回覆的反饋會先發送到代理伺服器上,代理伺服器再發送給我們的電腦。在這種情況下,只要我們的電腦和代理伺服器的連線是合理快速的,代理伺服器和網站伺服器的連線是順暢快速的,通過代理伺服器往往就可以加速我們訪問目標網頁的速度,甚至我們可以訪問到一些我們之前無法訪問的網頁內容。
那麼,如何通過python訪問代理伺服器呢??
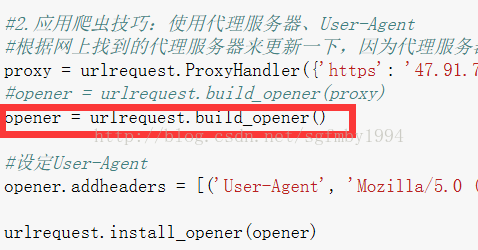
#使用urllib.request的兩個方法進行代理的設定 proxy = urlrequest.ProxyHandler({'https': '47.91.78.201:3128'}) opener = urlrequest.build_opener(proxy)
代理伺服器的存在,可以應對網站禁止某個IP訪問的反爬蟲措施,代理伺服器有著不同的匿名型別,通常我們會挑選中、高級別的代理伺服器來訪問網頁。(使用低級別的是沒有用的,網站還是能夠知道我們的真實IP,對於我們的爬取時沒有任何幫助的,因為它還是能夠封掉我們的真實IP)

3.設定User-Agent
網站是可以識別我們是否在使用Python進行爬取,需要我們在傳送網路請求時,把header部分偽裝成瀏覽器。
opener.addheaders = [('User-Agent','...')] 用不同瀏覽器訪問的header字串,放入上述程式碼省略號的部分即可。
常用的瀏覽器header有:
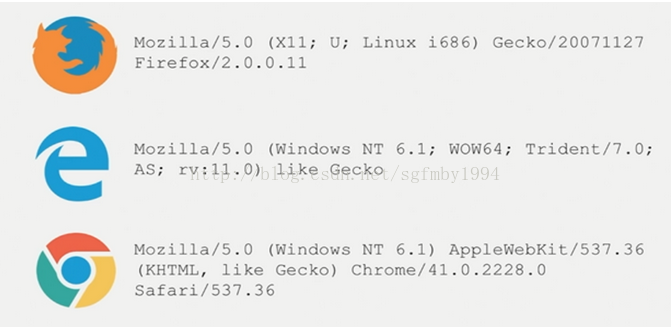
網上檢視還有這些:
1.QQ瀏覽器: Mozilla/5.0 (compatible; MSIE 10.0; WindowsNT6.1; WOW64; Trident/6.0; QQBrowser/7.7.24962.400)(我在程式碼中用的是這個)
2. IE瀏覽器:Mozilla/5.0(compatible; MSIE 10.0;Windows NT 6.1; WOW64; Trident/6.0)
示例:Place PulseGoogle街景圖爬取
這是MIT的學術專案,爬取不同城市的街景地圖,然後讓人去手工標註圖片中的城市哪個更安全,更有趣等等。
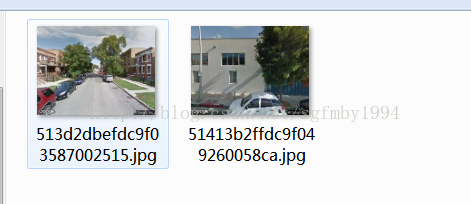
舉個例子,下面這兩個城市的圖景。如果認為左邊更好的話,就點選左邊的城市,如果認為差不多的話就點選等號,
如果認為右邊更好的話,就點選右邊的城市。
MIT會統計這些標註結果。
這個資料集是這樣的:(左邊城市是什麼,右邊城市是什麼,某人的打分)
下載下來:

結構:
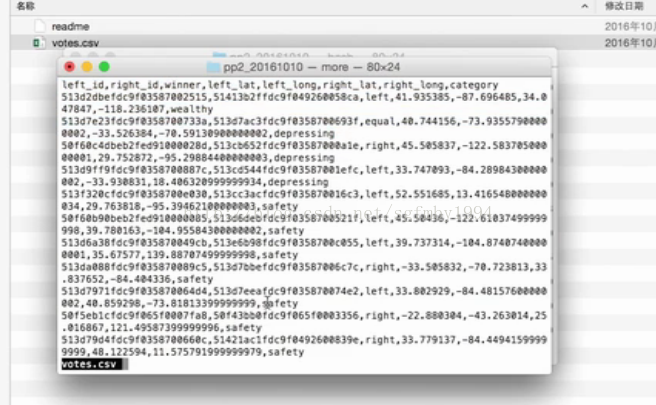
逗號來分隔每一個屬性裡面的值
核心任務:
把對應每一個圖片ID的谷歌街景圖片,根據它告訴我們的這個圖片所在的GPS的經緯度的位置,利用readme中看到的google map的api,把這個圖片下載下來。
程式碼及註釋:
# coding=utf-8
import urllib.request as urlrequest
import time
import random
# 1.準備工作:載入包,定義儲存目錄,連線API
IMG_PATH = './imgs/{}.jpg' # 最終會把下載的圖片存到這個目錄下面
DATA_FILE = './data/votes.csv'
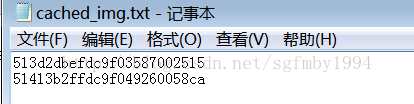
# 記錄一下已經下載了哪些圖片,把圖片id放在裡面,這樣如果下載中止也能知道哪些已經下載了,
# 這樣在下載一個圖片之前,我們可以先判斷一下這個圖片的id是否在這個檔案中有,如果有,就不用再下載了。
STORED_IMG_ID_FILE = './data/cached_img.txt'
STORED_IMG_IDS = set() # 把已經下載的圖片的id放在一個集合裡面
# readme中提到的google針對下載街景地圖的api
# 我們需要修改的是location,即經緯度
IMG_URL = 'https://maps.googleapis.com/maps/api/streetview?size=400x300&location={},{}'
# 2.應用爬蟲技巧:使用代理伺服器、User-Agent
# 根據網上找到的代理伺服器來更新一下,因為代理伺服器可以執行的時間也是有限制的
proxy = urlrequest.ProxyHandler({'https': '173.213.108.111:3128'}) # 設定代理伺服器的地址
#opener = urlrequest.build_opener(proxy)
opener = urlrequest.build_opener()
# 設定User-Agent
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (compatible; MSIE 10.0; WindowsNT 6.1; WOW64; Trident/6.0; QQBrowser/7.7.24962.400) ')]
urlrequest.install_opener(opener)
# 3.讀取圖片的id
with open(STORED_IMG_ID_FILE) as input_file:
for line in input_file:
STORED_IMG_IDS.add(line.strip())
# 4.根據提供的votes.csv,進行google街景圖片的爬取
with open(DATA_FILE) as input_file: # 讀取votes.csv
skip_first_line = True
for line in input_file:
if skip_first_line: # 因為第一行是屬性行,所以跳過
skip_first_line = False
continue
# 根據逗號就行拆分成各個屬性(這些屬性在readme中可以看到)
left_id, right_id, winner, left_lat, left_long, right_lat, right_long, category = line.split(',')
# 針對左邊的圖片
if left_id not in STORED_IMG_IDS: # 如果左邊的圖片還沒有下載
print('saving img {}...'.format(left_id))
urlrequest.urlretrieve(IMG_URL.format(left_lat, left_long), IMG_PATH.format(left_id)) # 檔案命名為這個圖片的id
STORED_IMG_IDS.add(left_id) # 把已經下載的圖片的id加進集合中
with open(STORED_IMG_ID_FILE, 'a') as output_file: # 把已經下載的圖片的id新新增進cached_img.txt中
output_file.write('{}\n'.format(left_id))
time_interval = random.uniform(1, 5)
time.sleep(time_interval) # wait some time, trying to avoid google forbidden (of crawler)
# 針對右邊的圖片
if right_id not in STORED_IMG_IDS:
print('saving img {}...'.format(right_id))
urlrequest.urlretrieve(IMG_URL.format(right_lat, right_long), IMG_PATH.format(right_id))
STORED_IMG_IDS.add(right_id)
with open(STORED_IMG_ID_FILE, 'a') as output_file:
output_file.write('{}\n'.format(right_id))
time_interval = random.uniform(1, 5)
time.sleep(time_interval) # wait some time, trying to avoid google forbidden (of crawler)
國外伺服器的代理地址,可以在 http://www.kuaidaili.com/free/outha/這個網站中找到。
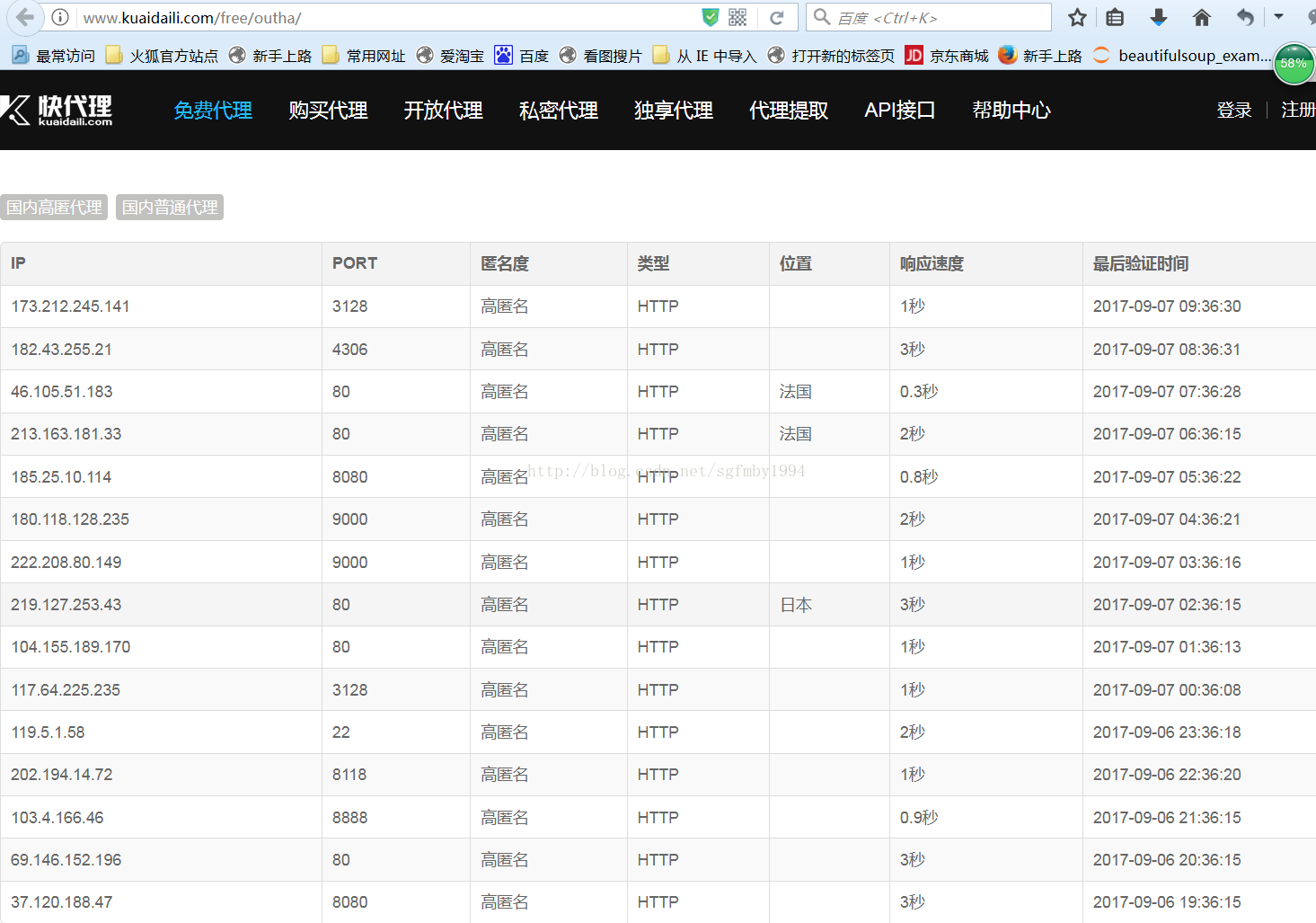
可以看到每個地址對應ip地址所在的國家,匿名的程度等等。
這裡需要注意我們不能使用低階(Transparent)代理。
先來執行不使用代理伺服器的程式:
速度很慢,儲存不動,google在大陸訪問起來還是比較困難的。
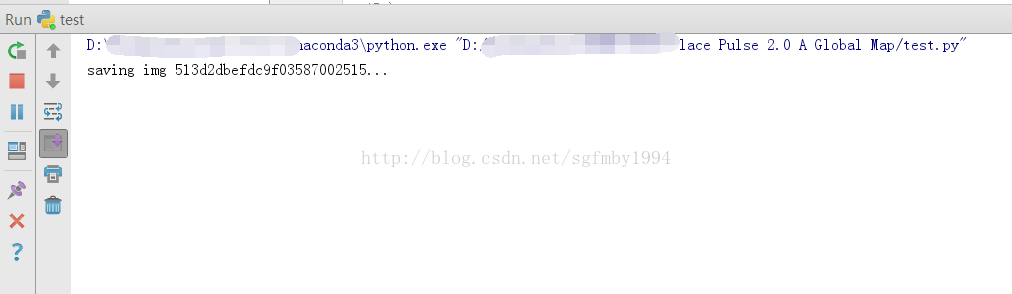
執行設定代理伺服器的程式:

可以順利進行,這說明我們成功連線到了代理的一個伺服器上,再通過這個代理伺服器連線到了google上。
在資料夾裡可以檢視到我們從googlemap中下載到的圖片以及圖片的id。