
機器學習筆記——強化學習
1.什麼是強化學習?
現在的機器學習演算法中,大多都是學習怎麼做。而強化學習則是在不斷嘗試的過程中,尋找在特定情境下選擇哪種行為可以獲得最大回報(Reward)。
.2.強化學習(RL)和監督學習(SL),無監督學習(UL)的關係
(1)監督學習就是給一個訓練集(訓練集含有標籤)進行學習,得出一個“函式”,能夠對下一次新的輸入準確預測其輸出。而這種學習方式在互動式學習環境中不太適用,舉個例子:在一場很大的颱風中,不同位置,不同方向的風力不同,而駕駛員也不能單憑某個位置處某個方向的風力值進行粗略的飛行判斷而就草率行事,這個判斷將會影響飛機上乘客的安危以及下一秒飛機所處的情境,所以這可以說是一個互動式的學習環境,駕駛員需要不斷的嘗試並學習飛機在不同情境下的狀態以便更好的做出下一步判斷。在這裡,駕駛員就相當於強化學習,不斷嘗試,不斷學習,獲取該情境下的最大回報。這時利用RL就非常合適,因為RL不是利用正確的行為來指導,而是利用已有的訓練資訊來對行為進行評價。
(2)因為RL利用的並不是採取正確行動的experience,從這一點來看和無監督的學習確實有點像,但是還是不一樣的,無監督的學習的目的可以說是從一堆未標記樣本中發現隱藏的結構,而RL的目的是最大化reward signal。
(3)所以,總的來說,RL的特點在於:沒有監督者,只有一個reward訊號;反應回饋是延遲的;時間對RL的影響;一次的判決將會對後面的data產生影響
RL採用的是邊獲得樣例邊學習的方式,在獲得樣例之後更新自己的模型,利用當前的模型來指導下一步的行動,下一步的行動獲得reward之後再更新模型,不斷迭代重複直到模型收斂。在這個過程中,非常重要的一點在於“在已有當前模型的情況下,如果選擇下一步的行動才對完善當前的模型最有利”
在RL中,agents是具有明確的目標的,所有的agents都能感知自己的環境,並根據目標來指導自己的行為,因此RL的另一個特點是它將agents和與其互動的不確定的環境視為是一個完整的問題。在RL問題中,有四個非常重要的概念:
(1)規則(policy)
Policy定義了agents在特定的時間特定的環境下的行為方式,可以視為是從環境狀態到行為的對映,常用 π來表示。policy可以分為兩類:
確定性的policy(Deterministic policy): a=π(s)
隨機性的policy(Stochastic policy): π(a|s)=P[At=a|St=t]
其中,t是時間點,t=0,1,2,3,……
St∈S,S是環境狀態的集合,St代表時刻t的狀態,s代表其中某個特定的狀態;
At∈A(St),A(St)是在狀態St下的actions的集合,At代表時刻t的行為,a代表其中某個特定的行為。
(2)獎勵訊號(a reward signal)
Reward就是一個標量值,是每個time step中環境根據agent的行為返回給agent的訊號,reward定義了在該情景下執行該行為的好壞,agent可以根據reward來調整自己的policy。常用R來表示。
(3)值函式(value function)
Reward定義的是立即的收益,而value function定義的是長期的收益,它可以看作是累計的reward,常用v來表示。
(4)環境模型(a model of the environment)
整個Agent和Environment互動的過程可以用下圖來表示:
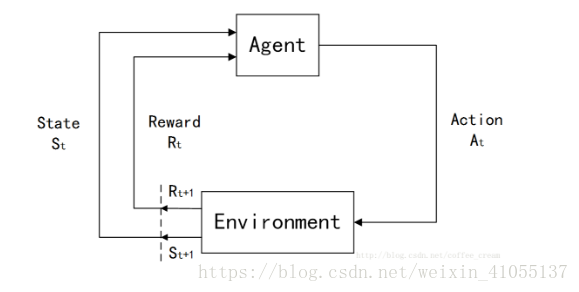
其中,t是時間點,t=0,1,2,3,……
St∈S,S是環境狀態的集合;
At∈A(St),A(St)是在狀態St下的actions的集合;
Rt∈R∈R 是數值型的reward。