
【Mapreduce】利用job巢狀,多重Mapreduce,求解二度人脈
與《【Mapreduce】利用單表關聯在父子關係中求解爺孫關係》(點選開啟連結)一樣的鍵值對。
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma只是這次是假設一個沒有重複,也就是不會出現Tom Lucy-Lucy Tom這樣的好友關係表。
任務是求其其中的二度人脈、潛在好友,也就是如下圖:
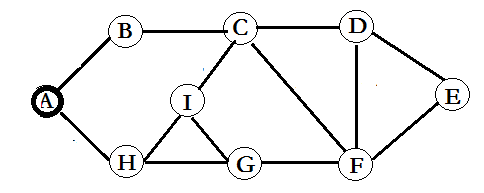
比如I認識C、G、H,但C不認識G,那麼C-G就是一對潛在好友,但G-H早就認識了,因此不算為潛在好友。
最終得出的是,如下的一個,沒有重複的,首字母接近A再前的,也就Tom Mary-MaryTom只輸出Mary Tom,因為M比T更接近A:
Alice Jesse
Alice Jone
Alice Mark
Alice Philip
Alice Tom
Alma Terry
Ben Jone
Ben Mary
Ben Tom
Jack Lucy
Jack Terry
Jesse Jone
Jesse Mark
Jesse Philip
Jesse Tom
Jone Mary
Jone Tom
Mark Philip
Mary Tom思路如下:
首先,我們進行第一個MapReduce:
1、與《【Mapreduce】利用單表關聯在父子關係中求解爺孫關係》(
例如Tom Lucy這個輸入行就在Map階段搞出Tom Lucy-Lucy Tom這樣的互逆關係。
2、之後Map-reduce會自動對context中相同的key合併在一起。
例如由於存在Tom Lucy、Tom Jack,顯然會產生一個Tom:{Lucy,Jack}
這是Reduce階段以開始的鍵值對。
3、這個鍵值對相當於Tom所認識的人。先進行如下的輸出,1代表Tom的一度人脈
Tom Lucy 1
Tom Jack 1
潛在好友顯然會在{Lucy,Jack}這個Tom所認識的人產生,對這個陣列做笛卡爾乘積,形成關係:{<Lucy,Lucy>,<Jack,Jack>,<Lucy,Jack>,<Jack,Lucy>}
將存在自反性,前項首字母大於後項剔除,也就是<Lucy,Lucy>這類無意義的剔除,<Lucy,Jack>,<Jack,Lucy>認定為一個關係,將剩餘關係進行如下的輸出,其中2代表Tom的二度人脈,也就是所謂的潛在好友:
Lucy Jack 2
此時,第一個MapReduce,輸出如下:
Alice Jack 1
Alice Terry 1
Jack Terry 2
Alma Philip 1
Alma Mark 1
Mark Philip 2
Ben Lucy 1
Jack Jesse 1
Jack Tom 1
Jack Jone 1
Alice Jack 1
Jesse Tom 2
Jesse Jone 2
Jone Tom 2
Alice Jesse 2
Alice Tom 2
Alice Jone 2
Jesse Terry 1
Jack Jesse 1
Jack Terry 2
Jack Jone 1
Jone Lucy 1
Jack Lucy 2
Ben Lucy 1
Jone Lucy 1
Lucy Tom 1
Lucy Mary 1
Ben Jone 2
Ben Tom 2
Ben Mary 2
Jone Tom 2
Jone Mary 2
Mary Tom 2
Alma Mark 1
Mark Terry 1
Alma Terry 2
Lucy Mary 1
Philip Terry 1
Alma Philip 1
Alma Terry 2
Philip Terry 1
Alice Terry 1
Mark Terry 1
Jesse Terry 1
Alice Philip 2
Alice Mark 2
Alice Jesse 2
Mark Philip 2
Jesse Philip 2
Jesse Mark 2
Jack Tom 1
Lucy Tom 1
Jack Lucy 2
這時,形式已經很明朗了,再進行第二個Mapreduce,任務是剔除本身就存在的關係,也就是在潛在好友中剔除本身就認識的關係。
將上述第一個Mapreduce的輸出,關係作為key,後面的X度人脈這個1、2值作為value,進行Mapreduce的處理。
那麼例如<Jack Lucy>這個關係,之所以會被認定為潛在好友,是因為它所對應的值陣列,裡面一個1都沒有,全是2,也就是它們本來不是一度人脈,而<Alma Mark>這對,不能成為潛在好友,因為他們所對應的值陣列,裡面有1,存在任意一對一度人脈、直接認識,就絕對不能被認定為二度人脈。
將被認定為二度人脈的關係輸出,就得到最終結果。
其實這個Mapreduce就是做了一件類似《【Mapreduce】去除重複的行》(點選開啟連結)的事情,只是在Reduce增加的一個輸出判斷。
因此程式碼如下:
import java.io.IOException;
import java.util.ArrayList;
import java.util.Random;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MyMapReduce {
//第一輪MapReduce
public static class Job1_Mapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] line = value.toString().split(" ");// 輸入檔案,鍵值對的分隔符為空格
context.write(new Text(line[0]), new Text(line[1]));
context.write(new Text(line[1]), new Text(line[0]));
}
}
public static class Job1_Reducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
ArrayList<String> potential_friends = new ArrayList<String>();
//這裡一定要用string存,而不是用Text,Text只是一個類似指標,一個MapReduce的引用
//換成用Text來存,你會驚訝,為何我存的值都一模一樣的?
for (Text v : values) {
potential_friends.add(v.toString());
if (key.toString().compareTo(v.toString()) < 0) {// 確保首字母大者再前,如Tom Alice則輸出Alice Tom
context.write(new Text(key + "\t" + v), new Text("1"));
} else {
context.write(new Text(v + "\t" + key), new Text("1"));
}
}
for (int i = 0; i < potential_friends.size(); i++) {// 潛在好友集合自己與自己做笛卡爾乘積,求出潛在的二度人脈關係
for (int j = 0; j < potential_friends.size(); j++) {
if (potential_friends.get(i).compareTo(//將存在自反性,前項首字母大於後項的關係剔除
potential_friends.get(j)) < 0) {
context.write(new Text(potential_friends.get(i) + "\t"
+ potential_friends.get(j)), new Text("2"));
}
}
}
}
}
//第二輪MapReduce
public static class Job2_Mapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] line = value.toString().split("\t");//輸入檔案,鍵值對的分隔符為\t
context.write(new Text(line[0] + "\t" + line[1]), new Text(line[2]));//關係作為key,後面的X度人脈這個1、2值作為value
}
}
public static class Job2_Reducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
//檢查合併之後是否存在任意一對一度人脈
boolean is_potential_friend = true;
for (Text v : values) {
if (v.toString().equals("1")) {
is_potential_friend = false;
break;
}
}
//如果沒有,則輸出
if (is_potential_friend) {
String[] potential_friends = key.toString().split("\t");
context.write(new Text(potential_friends[0]), new Text(
potential_friends[1]));
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
// 判斷output資料夾是否存在,如果存在則刪除
Path path = new Path(otherArgs[1]);// 取第1個表示輸出目錄引數(第0個引數是輸入目錄)
FileSystem fileSystem = path.getFileSystem(conf);// 根據path找到這個檔案
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);// true的意思是,就算output有東西,也一帶刪除
}
//設定第一輪MapReduce的相應處理類與輸入輸出
Job job1 = new Job(conf);
job1.setMapperClass(Job1_Mapper.class);
job1.setReducerClass(Job1_Reducer.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(Text.class);
// 定義一個臨時目錄,先將任務的輸出結果寫到臨時目錄中, 下一個job以臨時目錄為輸入目錄。
FileInputFormat.addInputPath(job1, new Path(otherArgs[0]));
Path tempDir = new Path("temp_"
+ Integer.toString(new Random().nextInt(Integer.MAX_VALUE)));
FileOutputFormat.setOutputPath(job1, tempDir);
if (job1.waitForCompletion(true)) {//如果第一輪MapReduce完成再做這裡的程式碼
Job job2 = new Job(conf);
FileInputFormat.addInputPath(job2, tempDir);
//設定第二輪MapReduce的相應處理類與輸入輸出
job2.setMapperClass(Job2_Mapper.class);
job2.setReducerClass(Job2_Reducer.class);
FileOutputFormat.setOutputPath(job2, new Path(otherArgs[1]));
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(Text.class);
FileSystem.get(conf).deleteOnExit(tempDir);//搞完刪除剛剛的臨時建立的輸入目錄
System.exit(job2.waitForCompletion(true) ? 0 : 1);
}
}
}需要注意的問題都寫在註釋的。
使用到多重Mapreduce其實很簡單的,一句類似等待執行緒結束的job1.waitForCompletion(true)將其從原來的System.exit移出來,作為判斷條件,再於裡面的條件結構設定並提交job2,等job2完成,再結束這個程式即可。