
知識圖譜導論----相關筆記
1.知識圖譜引言
1.1 知識圖譜的發展歷史與現有應用
(1) 深度自然語言理解需要知識的支撐。
(2)IBM Watson 在知識競賽節目《危險邊緣Jeopardy!》中上演“人機問答大戰”,並取勝。
(3) 1998年語義網的概念被提出。
1.2 知識圖譜的基本概念
- 已有的知識圖譜:
(1)語言知識圖譜
WordNet: 155,327個單詞,同義詞集117,597個,同義詞集之間由22中關係連線
(2)事實性知識圖譜
OpenCyc :23.9萬個實體,1.5萬個關係屬性,209.3萬個事實三元組
FreeBase: 4000多萬實體,上萬個屬性關係,24多億個事實三元組
DBpedia: 400多萬個實體,48293種屬性關係,10億個事實三元組
YAGO2: 980萬實體,超過100個屬性關係,1億多個事實三元組
百科詞條:詞條數1000萬個
百科互動:800萬詞條,5萬個分類,68億文字
(3)領域知識圖譜
Kinships:描述人物之間的親屬關係,104個實體,26種關係,10800個三元組
UMLS: 醫學領域,描述醫學概念之間的聯絡,135個實體,49種關係,6800個三元組
Cora: 2497個實體,7種關係,39255個三元組
(4)機器自動構建的知識圖譜
NELL: 519萬實體,306種關係,5億候選三元組
Knowledge Vault: 4500萬實體,4469種關係,2.7億三元組
- 歷史:Cyc--->WordNet---->知網---->Wikipedia------>Dbpedia,Yago,freebase
- 應用:問答、精準搜尋、關係搜尋、分類瀏覽、推薦、推理
- 涉及的領域:Semantic Web、Database、NLP
- 知識圖譜本質上是一種語義網路。其節點代表實體或概念,邊代表實體/概念之間的各種語義關係。
- 三個層面問題:知識體系(表示)---->知識獲取----->知識服務
- 知識圖譜概覽(基於符號的表示)
(1) 知識庫是一個有向圖
多關係資料(multi-relational data)
節點:實體/概念
邊:關係/屬性
關係事實=(head,relation,tail)
- 知識體系組織形式
(1)Ontology vs.Knowledge Base
Ontology:共享概念化的規範
Knowledge:服從於ontology控制的知識單元的載體
(2)公理:Formal Ontologyvs. Lightweight Ontology
Formal Ontology:大量使用公理
Lightweight Ontology:很少或不使用公理
(3)Ontology
樹狀結構,不同層節點之間有嚴格的IsA關係
優點:可以適用於知識推理
缺點:無法表示概念的二義性(運動員:體育?人物?)
(4)Taxonomy
樹狀結構,上下位節點之間非嚴格的IsA關係
優點:可以表示概念的二義性
缺點:不適用於推理,無法避免概念冗餘(餐廳?美食?機構?地點?)
(5)Folksonomy
類別標籤,更加開放
優點:能夠涵蓋更多的概念
缺點:如何進行標籤管理
(6)目前的知識資源多是採用Folksonomy與Taxonomy相結合的組織形式。但是能夠覆蓋的類別還很少
(7)類別屬性定義不統一
已有的體系框架:
GeoNames
DBpedia Ontology
TexonConcept Ontology
KOS
Schema.org: 1) 面對站長,而不是面對知識
2)體系覆蓋度不足,侷限於英文
3)細緻化不足
- Ontology Matching
建立體系間的Alignment
(1)挖掘概念之間的SameAs關係
(2)評測:Ontology Alignment Evaluation Initiative
關鍵:概念之間相似度的計算
- KG的基本概念
Node(概念/Concept)、(領域/Domain/Topic)、(實體/例項/Entity/Objects/Instance)
Node (值/Value): 實體(Entity)、字串(String)、 數字(Number)、時間(Date)、列舉(Enumerate)
邊(關係):Subclass、Type、Relation、Property/Attribute
關係:Taxonomic Relation vs. Non-taxonomic Relation
Taxonomic Relation:is-a/Hypernym-Hyponym
Non-taxonomic Relation:概念之間的相互作用
Node:高階三元組
(1)與時間、地點相關
(2)事件
- 知識分類:百科知識、領域知識、事實性知識、主觀性知識、場景知識、語言知識、常識知識
- 系統架構圖
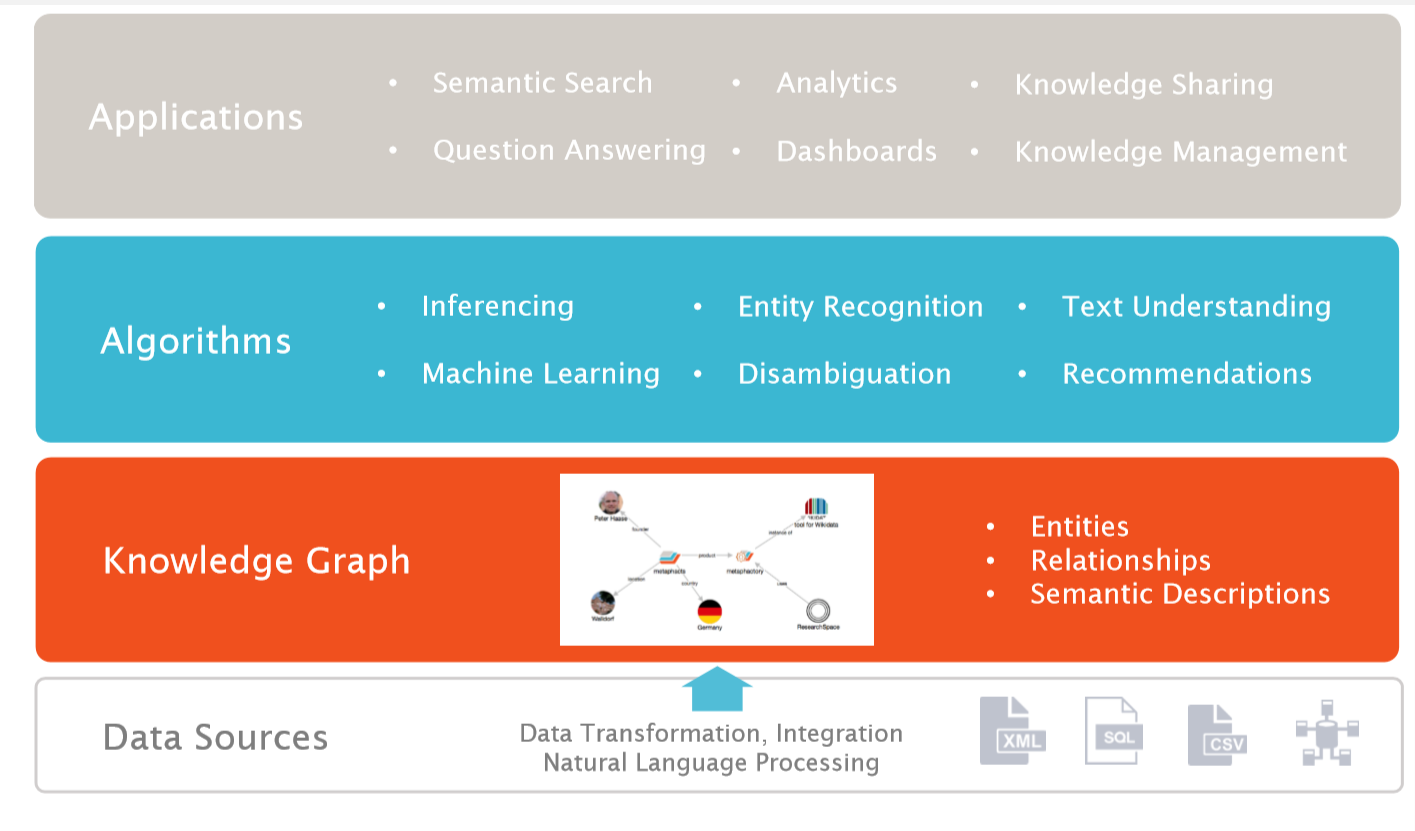
1.3知識圖譜的生命週期
(1) 領域知識建模
輸入:目標領域(醫療、金融)、應用場景
輸出:領域知識本體、領域實體類別體系、 實體屬性、 領域語義關係、語義關係之間的關係
關鍵技術:Ontology Engineering
(2)知識獲取
輸入:領域知識本體、海量資料:文字、垂直站點、百科
輸出:領域知識(實體集合、實體關係/屬性)
主要技術:資訊抽取、文字挖掘
(3)知識整合
輸入:抽取出來的知識、現有的知識庫、知識本體
輸出:知識置信度、 統一知識庫
關鍵技術:Ontology Matching、 Entity Linking
(4)知識儲存/查詢/推理
輸入:大規模知識庫知識
輸出:知識庫儲存/查詢/推理服務
主要技術:知識表示、知識查詢語言、儲存/檢索引擎、推理引擎
(5)總結:知識建模(建模領域知識結構)---->知識獲取(獲取領域內的事實知識)---->知識整合(估計知識
的可信度,將碎片知識組裝成知識網路)----->知識儲存(提供高效能的知識服務)
1.4代表性知識圖譜
(1)人工構建知識圖譜: WordNet、Cyc
(2)基於Wikipedia的知識圖譜:Yago、DBPedia、Freebase
(3)文字抽取知識圖譜:NELL
(4)WordNet的應用:在自然語言處理中被廣泛應用、作為詞義消歧的目標知識庫、作為高質量的Taxonomy、用於計算語義相似度 (5)基於Wikipedia的知識庫
相同的思路 : 從Wikipedia豐富的半結構化資訊中挖掘知識: 包括:Infobox,Category,超連結,Table,List…..
不同之處在於:如何處理有歧義的屬性對映、如何構建知識庫的Taxonomy
這些知識庫具有相同的資料模型:
1)一個知識庫包含一個集合 的實體
2)實體被劃分到不同的類別中
3)類別通過上下文關係等關係相互關聯
4)類別和實體都通過屬性和相互之間的關係來描述
5)關係可以通過蘊含關係來進行推理
(6)DBPedia
1) 2007年開始,主要目的是構建一個社群,通過社群成員來定義和撰寫模板,從維基百科中抽取結構化資訊,並將其釋出到Web上。
2)通過人工的方式構建了Taxonomy(280個類別,覆蓋50%的維基百科實體)
3)抽取方法:DIEF-Dbpedia Information Extraction Framework
4)使用RDF來表示抽取出來的知識。
5)支援複雜的結構化query,SPASQL語言查詢;支援與web上其他資料集的連結和整合
(7)Yago(Yet AnotherGreat Ontology)
1)德國馬普研究所2007年開始的專案
2)融合WordNet和Wikipedia
3)Yago Taxonomy構建: 使用WordNet的Taxonomy作為基礎、將Wikipedia中的類別加入到WordNet中
4)Yago的語義關係:
人工定義了100多種語義關係
抽取方法:主要採用手寫的規則抽取
InfoboxHarvesting:資訊框
Word-LevelTechniques:重定向頁
Category Harvesting:類別資訊抽取
Type Extraction:維基類別、WordNet類別
(8)Freebase
1)Metaweb公司2000年開始構建,2010年被Google收購
2)從Wikipedia和其他資料來源(如IMDB、MusicBrainz)中匯入知識
3)核心想法:在wikipedia中,人們編輯文章;在Freebase中,人們編輯結構化知識。
4)使用者是Freebase知識構建的核心
編輯實體:建立實體、將實體分到類別、增加/修改屬性/關係、上傳圖片
編輯Schema: 定義新類別、定義類別的屬性
Review: 驗證知識的準確性、投票、刪除錯誤知識
DataGame:尋找別名、抽取事件日期、使用Yahoo圖片搜尋、加入圖片
(9)NELL
1)2009年開始的CMU專案
2)輸入:初始本體(800類別和關係)、每個謂詞的一些例項(10-20個種子例項)、web、間歇人工干預
3)任務:持續執行、抽取更多知識來補充給定本體、學習如何更好的構建抽取模型
4)結構:超過9千萬例項(不同置信度)
5)抽取步驟: 把名詞短語劃分到給定類別、 分類名詞短語之間的語義關係、 識別新的推理規則,用於發現新的關係例項(PathRank)、
名詞短語被對映到概念,動詞短語被對映到關係
(10)知識圖譜
1) 實體及其之間關係的語義描述:使用形式化知識表示(如RDF、RDFS、OWL)
2)Entities:真實世界物件和抽象概念
3)Relationships:將實體按語義關係連結成一張大網
4)Sematic descriptions:類別和屬性
5)有時包含支援推理的公理知識(如規則)
2.知識圖譜的表示與推理
2.1基於符號的知識表示與推理
- 知識及知識表示
- 符號表示知識的方法及實現:Logic、Semantic Net 、Frame、Script、語義網知識表示語言體系
- Knowledge=Facts+Rules+Control Strategy+(有時)Faiths
- 知識的類別體系:
(1)Facts:陳述性知識
(2)Rules:程式性知識
(3)Controle Strategy:元知識
- 知識表示(knowledge representation)
(1)知識表示同時是認知科學和AI中的科學問題;在認知科學中,KR關注如何儲存和處理資訊;
在人工智慧中,KR關注如何表示關於世界的資訊,並通過常識和事實得出結論
(2)一個知識表示是事物本身的一個代替,使我們可以通過思考而不是行動來確定事物的後果
(3)一個知識表示是一個本體約定(ontological commitment)集合
- 知識表示的主要方法
- 自然語言
- 符號表示方法(logic,sematic Net,Frame,Script,語義網只是表示體系)
- 許多其他的方法,如分散式表示方法
- 知識表示語言的元件
- Syntax(句法):知識表示語言中使用到的原子符號,原子符號如何組成合法的語句
- Semantics(語義):知識表示中的一個句子在世界上對應的事實,用於決定一個句子的真值。
- Inference(推理):如何從已有知識中得到新知識的機制
- 謂詞邏輯(predicate logic)
- 關於物件的邏輯,用於表示關於實體物件的知識
- 相比命題邏輯,謂詞邏輯提供了一套更為靈活且緊湊的知識表示方式,它提供了表示和推理物件屬性及不同物件間關係的機制
- 物件的表示:
- 使用terms來表示物件
- Terms是物件的名字,Logical function讓我們可以用有限的term來緊湊的表示無限的物件
- 命題(Proposition)
- Predicate:謂詞是一個動詞片語,用於描述物件的屬性,或是不同物件之間的關係
- 命題是謂詞+應用於該謂詞的一個term元組,表示一個屬性或objects之間的關係
- 複雜的命題可以通過邏輯連線詞來構建
- 量詞
- 通過量詞機制,允許宣告關於一個集合的物件的知識,而不需要一一列舉它們
- Logical KB
- 一個邏輯知識庫包含:
- 用於描述謂詞之間關係的公理
- 謂詞的定義
- 事實集合
- 使用者可以查詢特定的知識庫
- 一個邏輯知識庫包含:
- 推理機制
- 相等變換
- 蘊含推理
- 假言推理(三段論)
- Universal Elimination
- Existential Elimination
- Existential Introduction
- 用邏輯表示知識的優缺點
- 優點:有語義、表達能力強
- 缺點:不高效、不可判定性、無法表達過程知識、無法做預設推理
- Semantic Net(語義網)
- Semantic Net是一個通過語義關係連線的概念網路
- Semantic Net將知識表示為相互連線的點和邊模式
- Node表示實體、屬性、事件、值等
- Links表示物件之間的語義關係
- 通常使用的語義關係
- IS-A
- Part-of
- Modifiles: on ,down,up,bottom,moveto,……
- 領域特定的link型別:(醫療:症狀、治療、病因;金融:收購、持有、母公司)
- Semantic Net中的推理
- Inheritance(繼承)
- Intersection search(交集搜尋)
- Frame(框架)
- Frame表示
- 知識通過Frame的形式表示,每一個Frame表示一種典型的原型化場景(a stereotypical situation)
- Frame-Based KR類似於面向物件程式設計,區別在於編碼的物件不同
- 一個Frame類似於資料庫中的資料記錄結構或資料庫記錄
- Frame包含slot names和slot filters
- 一個Frame的slot集合能夠表示與該框架相關的物件
- 一個slot可以指向其它的Frame,Procedure,slot
- 兩類Frame
- Class Frame:類似於面向物件程式設計裡面的Class
- Individual or Instance Frame:類似於面向物件程式設計裡面的Object
- Slot類似於OO裡面的variables/methods
- 不同的Frame通常被組織成一個層次體系結構
- Instance Frame ----instance_of---->Class Frame
- Class Frame------subclass_of------>Class Frame
- 子類可以從父類繼承屬性和預設屬性值
- 知識通過Frame的形式表示,每一個Frame表示一種典型的原型化場景(a stereotypical situation)
- Frame表示上的推理
- 能夠推理類別之間和類別與例項之間的ISA關係
- 能夠使用slots和slot value來推理屬性知識
- 物件可以繼承所有父類的屬性
- 可以繼承原型屬性值,同時也可以覆蓋原型屬性值
- Frame表示的優缺點
- 優點:
- 直接表示領域知識領域
- 支援預設推理
- 高效
- 支援過程知識(slot filter可以是一個過程)
- 缺點:
- 表達能力受限制
- 缺乏標準
- 更像一種方法論而不是一種特定的表示
- 沒有直接與reasoning/inference機制關聯
- 優點:
- FrameNet--Frame知識庫
- 圍繞框架構建,論元標籤在不同框架之間共享
- 包含4000多英文謂詞,200000人工標註的句子
- 包括框架、詞元、框架關係、例句及篇章
- 漢語框架網(Chinese FrameNet)
- 山西大學漢語框架網與語義計算研究室
- Frame表示
- Script(指令碼)
- Script表示
- 指令碼與框架類似,有一組槽組成,用來表示特定領域內的一組事件的發生序列
- 類似於Frame表示
- 使用繼承和slots
- 描述原型知識(stereotypical knowledge),但是關注事件知識
- 基於Conceptual Dependency Theory構建
- Script定義
- 一個指令碼是一個事件序列,包含了一組緊密相關的動作及改變狀態的框架
- 一個指令碼是一個描述特定上下文中的原型事件序列
- Script的組成元素
- 進入條件:給出指令碼中所描述事件的前提條件
- 角色:用來表示在指令碼所描述事件中可能出現的有關人物的槽
- 道具:用來表示在指令碼所描述事件中可能出現的有關物體的槽
- 場景:描述事件發生的真實順序。一個事件可以由多個場景組成,而每個場景可以是其它指令碼
- 結局:給出在指令碼所描述事件發生以後所產生的結果
- Script的推理
- 基於指令碼事件因果鏈的推理
- 只有符合特定條件的指令碼才會發生
- 只有符合結束條件的指令碼才會結束
- 事件和事件直接的因果鏈順序推理
- 預測未知事件
- 基於指令碼事件因果鏈的推理
- Script的特點
- 缺點:
- 指令碼結構與框架結構相比表達能力更受約束
- 表示範圍更窄
- 優點:
- 適合於表達預先構思好的特定的知識或順序性動作及事件,如理解故事情節等
- 適用於自然語言理解中的閱讀理解等應用
- 缺點:
- Script表示
- Sematic Web知識表示語言
- 資料全球資訊網(Web of Data)
- 全球開發的知識共享平臺
- 使用語義網技術
- 在Web上釋出結構化資料
- 在不同資料來源中的資料之間建立連線
- 特徵
- Web上的事物擁有唯一 的URI
- 事物之間由連結關聯
- 事物之間連結顯式存在並擁有型別
- Web上資料的結構顯式存在
- 語義網資訊描述語言
- 語義網提供了一套為描述資料而設計的表示語言和工具,用形式化的描述一個知識領域內的概念、術語和關係
- HTML描述文件和文件之間的連結
- RDF,RDFS,OWL和XML能夠描述事物和事物之時間的關係,如人,會議,飛機和飛機元件
- 主要元件
- 包括一系列的W3C標準和工具:
- Resource Description Framework(RDF)
- RDF Schema(RDFS)
- Web Ontology Language(OWL)
- SPARQL, an RDF query language
- RDF
- RDF是一種表述物件和物件之間關係的簡單語言
- 使用(subject,predicate,object)三元組的形式來陳述關於物件(使用URI標識的resources)的知識,也就是兩個物件之間的帶類別連結
- RDF是一個通用模型,可以用各種不同的格式來表示,XML,N-Triples,N3,Json-LD等
- RDF Schema
- RDFS是RDF的一個擴充套件,提供了一個用於描述RDF resources的屬性(properties)和類別(classes)的術語表(vocabulary)
- 上述詞表被組織成一個帶類別的層次體系結構(typed hierarchy)
- Class,subClassOf,type:描述類別子類
- Property,subPropertyOf:屬性層次體系結構
- domain,range:定義新術語
- 術語表
- RDFS提供了定義術語表(vocabularies)的能力 :屬性集合和類別集合;與其他術語表中的術語的關
- RDF和RDFS
- RDF(S)提供了很小的本體約定(ontological commitment)來建模primitives
- 一個用於知識表示的詞彙表(subClassOf、subPropertyOf、domain、range)
- 可以用來定義術語表(vacabulary)
- 不能準確描述語義
- 缺少推理模型
- 本體Ontology
- 本體提供了人和機器之間更好的交流機制
- 本體通過概念標準化(standardize)和形式化(formalize)詞語的意義
- 本體的五元組表示O={C,R,F,A,I}
- C-概念集合,通常以Taxonomy形式組織
- R-關係,描述概念和例項之間語義關係的集合
- F-函式,一組特殊的關係,關係中第n個元素的值由其他n-1元素的值確定
- A-公理,
- I-具體個體
- Web Ontology Language=OWL
- OWL進一步提供了更多的術語來描述屬性和類別
- 相比於RDFS的擴充套件
- 構建類別
- 構造屬性
- 屬性特徵
- 屬性和類別間關係
- 包括一系列的W3C標準和工具:
- 資料全球資訊網(Web of Data)
2.2基於分散式的知識表示與推理
- 知識圖譜表示學習方法分類
(1)張量分解
(2)基於翻譯的模型
(3)神經網路模型 - 張量表示知識模型
(1)知識圖譜中三元組結構是(頭部實體h,關係r,尾部實體t),其中r連線頭尾實體。
表示知識圖譜中的實體,以表示知識圖譜中的關係,則可以用一個三維矩陣表示知識圖譜。
(2)張量分解得到實體,關係表示
(3)分解的目標函式 - 基於翻譯的模型TransE
(1)用向量表示實體和關係。關係事實=(head,relation,tail),對應向量(h,r,t)
(2)翻譯模型的學習
勢能函式:對真實的三元組(h,r,t),要求h+r=t;錯誤的不滿足該條件
目標函式
(3)生成負樣本的方法
負樣本生成策略:
1)隨機選取實體h'(t'),替換(h,r,t)中的h(t),生成負樣本(h',r,t)或(h,r,t')
2)在選擇替換實體的時候,不是完全隨機在實體集合中選擇,而是在適合關係r關係的集合中隨機選擇
(4)知識圖譜資料問題
1)有多種關係“1-1”,“1-N”,“N-1”,“N-N"
2)解決方案:TrensR,TransH,TransD
3)實體和關係通常會出現在多個不同的三元組中,類似於一詞多義,實體和關係在不同的三元組中常呈現出不同的含義。
4)利用協方差描述關係的不確定性 - 神經網路方法
(1)神經網路模型:Neural Tensor Network、SemanticMatchingEnergyNetwork
(2)Neural Tensor Network
關係表示 g(h,r,t)、勢能函式表示、實體表示、訓練目標和方法、訓練集中正樣本、負樣本、引數、優化方法:L-BFGS
(3)SemanticMatchingEnergyNetwork
1)評測任務與資料集
三元組分類
任務描述:判定給定的三元組是否是正確的
評測標準:這是二分類任務,以分類準確率為評測指標
資料集:常用的資料集有WN11,FB13,FB15k
連結預測
任務描述:挖掘三元組中的實體或關係,然後在實體(關係)集中選擇實體(關係)將其補全
評測標準:計算正確實體的排名,排名卻靠前,模型越優。計算測試集所有三元組頭尾部實體的平均排名和排在前10的比例 資料集:常用資料集有WN18,FB15k
、