
Android 實現 Ocr手機號掃描
阿新 • • 發佈:2019-01-25
這個演算法主要針對下圖中這種獨立存在的一串手機號的識別,如果是 ” 手機號:13651761352 “
這種字串,會直接被過濾演算法過濾掉,因為在捕捉字元的過程中,會捕捉到至少14位字元,不符合手機號的11位特徵,這種過濾條件,可以在Demo中自行調整
Demo截圖:
圖一

圖二

圖三
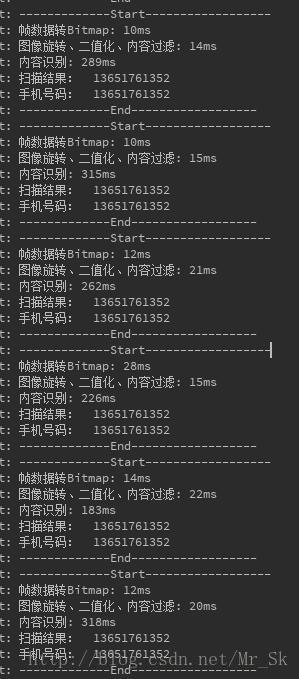
圖四

圖五

圖一:是掃描線沒有對準手機號碼,未捕捉到手機號的狀態,這種狀態下,每一幀都會在10-30ms之內被確定掃描線沒有對準一個> 手機號而被過濾掉,不交給tess-two解析,直接放棄這一幀資料
圖二:是掃描線對準了手機號,經過過濾演算法後,捕捉到一個包含11位字元的蚊子塊,基本確認存在手機號
圖三:是 圖二 狀態下的識別結果
圖四:是被水印干擾的手機號所得到的二值化圖片
圖五:是清除水印後取到的手機號區域(只適用於圖五這種文字底部的干擾)
使用方法
在project 的build.gradle中新增
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}在module的build.gradle中新增
dependencies {
compile 'com.github.SiKang123:ImgTranslator:lastVersion' 在Application中初始化
ImageTranslator.getInstance().init(ApplicationContext);傳入需要識別的圖片
Bitmap bmp=需要識別的圖片,在掃描識別的場景中,就是相機預覽圖中取出的掃描區域;
Translator translator = new PhoneNumberTranslator();
//開始識別
ImageTranslator.getInstance().translate(translator, rotateToDegrees(bmp, 90), new ImageTranslator.TesseractCallback() {
@Override 程式碼提交
這種方法還可以針對 身份證掃描、郵箱掃描、銀行卡號 等做相應的識別演算法,如果有感興趣的朋友願意分享自己的演算法,非常歡迎提交程式碼,提交程式碼格式如下:
以手機號識別為例,我建立了一個PhoneNumberTranslator類 假如你想實現一個郵箱掃描:
1、實現一個演算法類,繼承Translator,實現如下三個抽象方法
public class EmailTranslator extends Translator{
/**
* 你使用的字型檔名字
*/
@Override
public String initLanguage() {
return "email";
}
/**
* @params 從相機預覽圖中傳入的 掃描區域Bitmap
* 在這裡實現你對圖片中的email的過濾、捕捉等處理,然後返回捕捉到的email區域bitmap
* 如果可以斷定圖片中沒有email,return null即可
*/
@Override
public Bitmap catchText(Bitmap bitmap) {
return emailBitmap;
}
/**
* 對於掃描結果的篩選
* 如果catchText() 捕捉到了email,那麼這個包含email的Bitmap會交由 tess-two識別,最終的識別結果,會用正則公式來篩選需要的內容
* 比如這裡返回了一個email的正則表示式,最終會將識別結果中的所有email返回,如果不需要篩選,這裡return "" 即可
*/
@Override
public String filterRule() {
return "^(\w)+(\.\w+)*@(\w)+((\.\w+)+)$";
}
}2、提交你的字型檔
將你使用的字型檔檔案提交到 https://github.com/SiKang123/tessdata ,比如這裡用的是email字型檔,那麼就將email.traineddata 檔案,提交到這個地址
3、提交你的程式碼,我測試後,上線程式碼