
用R語言進行關聯分析
關聯是兩個或多個變數取值之間存在的一類重要的可被發現的某種規律性。關聯分析目的是尋找給定資料記錄集中資料項之間隱藏的關聯關係,描述資料之間的密切度。
幾個基本概念
1. 項集
這是一個集合的概念,在一籃子商品中的一件消費品即為一項(Item),則若干項的集合為項集,如{啤酒,尿布}構成一個二元項集。
2. 關聯規則
一般記為的形式,X為先決條件,Y為相應的關聯結果,用於表示資料內隱含的關聯性。如:,表示購買了尿布的消費者往往也會購買啤酒。
關聯性強度如何,由三個概念——支援度、置信度、提升度來控制和評價。
例:有10000個消費者購買了商品,其中購買尿布1000個,購買啤酒2000個,購買麵包500個,同時購買尿布和麵包800個,同時購買尿布和麵包100個。
3. 支援度(Support)
支援度是指在所有項集中{X, Y}出現的可能性,即項集中同時含有X和Y的概率:
該指標作為建立強關聯規則的第一個門檻,衡量了所考察關聯規則在“量”上的多少。通過設定最小閾值(minsup),剔除“出鏡率”較低的無意義規則,保留出現較為頻繁的項集所隱含的規則。
設定最小閾值為5%,由於{尿布,啤酒}的支援度為800/10000=8%,滿足基本輸了要求,成為頻繁項集,保留規則;而{尿布,麵包}的支援度為100/10000=1%,被剔除。
4. 置信度(Confidence)
置信度表示在先決條件X發生的條件下,關聯結果Y發生的概率:
這是生成強關聯規則的第二個門檻,衡量了所考察的關聯規則在“質”上的可靠性。相似的,我們需要對置信度設定最小閾值(mincon)來實現進一步篩選。
具體的,當設定置信度的最小閾值為70%時,置信度為800/1000=80%,而的置信度為800/2000=40%,被剔除。
5. 提升度(lift)
提升度表示在含有X的條件下同時含有Y的可能性與沒有X這個條件下項集中含有Y的可能性之比:
該指標與置信度同樣衡量規則的可靠性,可以看作是置信度的一種互補指標。
R中Apriori演算法
演算法步驟:
1. 選出滿足支援度最小閾值的所有項集,即頻繁項集;
2. 從頻繁項集中找出滿足最小置信度的所有規則。
> library(arules) #載入arules包
> click_detail =read.transactions("click_detail.txt",format="basket",sep=",",cols=c(1)) #讀取txt文件(文件編碼為ANSI)
> rules <- apriori(click_detail, parameter =list(supp=0.01,conf=0.5,target="rules")) #呼叫apriori演算法
> rules
set of419 rules
> inspect(rules[1:10]) #檢視前十條規則
解釋
1) library(arules):載入程式包arules,當然如果你前面沒有下載過這個包,就要先install.packages(arules)
2) click_detail =read.transactions("click_detail.txt",format="basket",sep=",",cols=c(1)):讀入資料
read.transactions(file, format =c("basket", "single"), sep = NULL,
cols = NULL, rm.duplicates =FALSE, encoding = "unknown")
file:檔名,對應click_detail中的“click_detail.txt”
format:檔案格式,可以有兩種,分別為“basket”,“single”,click_detail.txt中用的是basket。
basket: basket就是籃子,一個顧客買的東西都放到同一個籃子,所有顧客的transactions就是一個個籃子的組合結果。如下形式,每條交易都是獨立的。
檔案形式:
item1,item2
item1
item2,item3
讀入後:
items
1 {item1,
item2}
2 {item1}
3 {item2,
item3}
single: single的意思,顧名思義,就是單獨的交易,簡單說,交易記錄為:顧客1買了產品1, 顧客1買了產品2,顧客2買了產品3……(產品1,產品2,產品3中可以是單個產品,也可以是多個產品),如下形式:
trans1 item1
trans2 item1
trans2 item2
讀入後:
items transactionID
1 {item1} trans1
2 {item1,
item2} trans2
sep:檔案中資料是怎麼被分隔的,預設為空格,click_detail裡面用逗號分隔
cols:對basket, col=1,表示第一列是資料的transaction ids(交易號),如果col=NULL,則表示資料裡面沒有交易號這一列;對single,col=c(1,2)表示第一列是transaction ids,第二列是item ids
rm.duplicates:是否移除重複項,預設為FALSE
encoding:寫到這裡研究了encoding是什麼意思,發現前面txt可以不是”ANSI”型別,如果TXT是“UTF-8”,寫encoding=”UTF-8”,就OK了.
3) rules <- apriori(click_detail,parameter = list(supp=0.01,conf=0.5,target="rules")):apriori函式
apriori(data, parameter = NULL, appearance = NULL, control = NULL)
data:資料
parameter:設定引數,預設情況下parameter=list(supp=0.1,conf=0.8,maxlen=10,minlen=1,target=”rules”)
supp:支援度(support)
conf:置信度(confidence)
maxlen,minlen:每個項集所含項數的最大最小值
target:“rules”或“frequent itemsets”(輸出關聯規則/頻繁項集)
apperence:對先決條件X(lhs),關聯結果Y(rhs)中具體包含哪些項進行限制,如:設定lhs=beer,將僅輸出lhs含有beer這一項的關聯規則。預設情況下,所有項都將無限制出現。
control:控制函式效能,如可以設定對項集進行升序sort=1或降序sort=-1排序,是否向使用者報告程序(verbose=F/T)
補充
通過支援度控制:rules.sorted_sup = sort(rules, by=”support”)
通過置信度控制:rules.sorted_con = sort(rules, by=”confidence”)
通過提升度控制:rules.sorted_lift = sort(rules, by=”lift”)
Apriori演算法
兩步法:
1. 頻繁項集的產生:找出所有滿足最小支援度閾值的項集,稱為頻繁項集;
2. 規則的產生:對於每一個頻繁項集l,找出其中所有的非空子集;然後,對於每一個這樣的子集a,如果support(l)與support(a)的比值大於最小可信度,則存在規則a==>(l-a)。
頻繁項集產生所需要的計算開銷遠大於規則產生所需的計算開銷
頻繁項集的產生
幾個概念:
1, 一個包含K個項的資料集,可能產生2^k個候選集

2,先驗原理:如果一個項集是頻繁的,則它的所有子集也是頻繁的(理解了頻繁項集的意義,這句話很容易理解的);相反,如果一個項集是非頻繁的,則它所有子集也一定是非頻繁的。
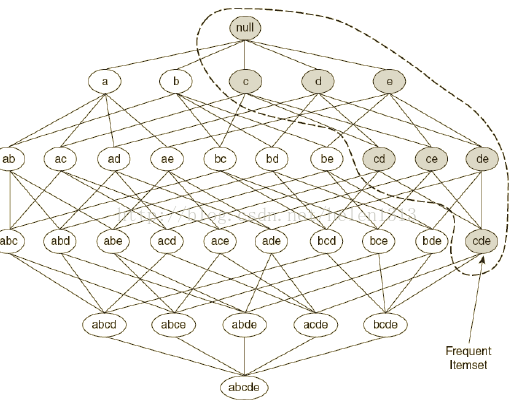
3基於支援度(SUPPORT)度量的一個關鍵性質:一個項集的支援度不會超過它的子集的支援度(很好理解,支援度是共同發生的概率,假設項集{A,B,C},{A,B}是它的一個自己,A,B,C同時發生的概率肯定不會超過A,B同時發生的概率)。
上面這條規則就是Apriori中使用到的,如下圖,當尋找頻繁項集時,從上往下掃描,當遇到一個項集是非頻繁項集(該項集支援度小於Minsup),那麼它下面的項集肯定就是非頻繁項集,這一部分就剪枝掉了。
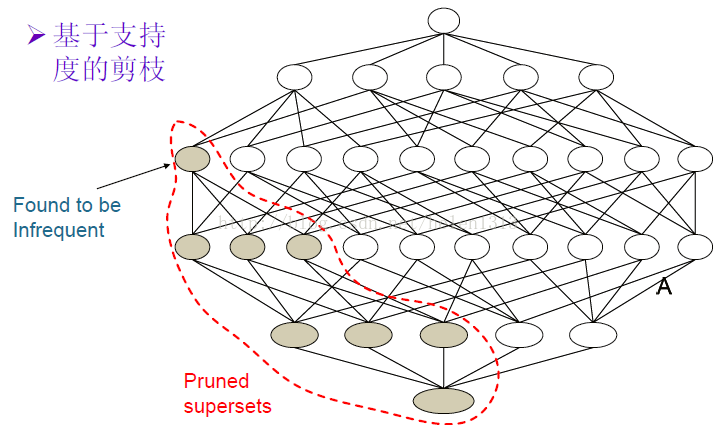
一個例子(百度到的一個PPT上的):
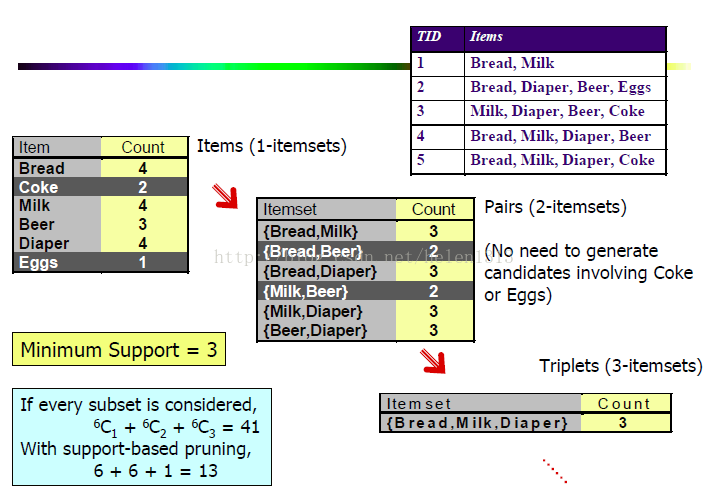
當我在理解頻繁項集的意義時,在R上簡單的復現了這個例子,這裡採用了eclat演算法,跟apriori應該差不多:
程式碼:
item <- list(
c("bread","milk"),
c("bread","diaper","beer","eggs"),
c("milk","diaper","beer","coke"),
c("bread","milk","diaper","beer"),
c("bread","milk","diaper","coke")
)
names(item) <- paste("tr",c(1:5),sep = "")
item
trans <- as(item,"transactions") #將List轉為transactions型
rules = eclat(trans,parameter = list(supp = 0.6,
target ="frequent itemsets"),control = list(sort=1))
inspect(rules) #檢視頻繁項集
執行後結果:
>inspect(rules)
items support
1{beer,
diaper} 0.6
2{diaper,
milk} 0.6
3{bread,
diaper} 0.6
4{bread,
milk} 0.6
5{beer} 0.6
6{milk} 0.8
7{bread} 0.8
8{diaper} 0.8
以上就是該例子的所有頻繁項集,然後我發現少了{bread,milk,diaper}這個項集,回到例子一看,這個項集實際上只出現了兩次,所以是沒有這個項集的。
規則的產生
每個頻繁k項集能產生最多2k-2個關聯規則
將項集Y劃分成兩個非空的子集X和Y-X,使得X ->Y-X滿足置信度閾值
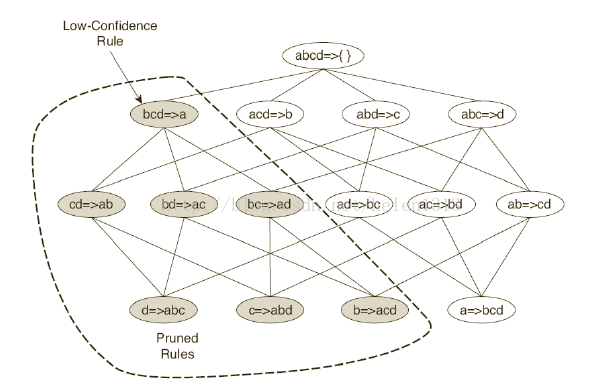
定理:如果規則X->Y-X不滿足置信度閾值,則X’->Y-X’的規則一定也不滿足置信度閾值,其中X’是X的子集
Apriori按下圖進行逐層計算,當發現一個不滿足置信度的項集後,該項集所有子集的規則都可以剪枝掉了。
http://m.blog.csdn.net/blog/whelen1313/38061777