
前饋神經網路(matlab例項)
定義回顧
前饋網路也稱前向網路。這種網路只在訓練過程會有反饋訊號,而在分類過程中資料只能向前傳送,直到到達輸出層,層間沒有向後的反饋訊號,因此被稱為前饋網路。感知機( perceptron)與BP神經網路就屬於前饋網路。
對於一個3層的前饋神經網路N,若用X表示網路的輸入向量,W1~W3表示網路各層的連線權向量,F1~F3表示神經網路3層的啟用函式。
那麼神經網路的第一層神經元的輸出為:
O1 = F1( XW1 )
第二層的輸出為:
O2 = F2 ( F1( XW1 ) W2 )
輸出層的輸出為:
O3 = F3( F2 ( F1( XW1 ) W2 ) W3 )
若啟用函式F1~F3都選用線性函式,那麼神經網路的輸出O3將是輸入X的線性函式。因此,若要做高次函式的逼近就應該選用適當的非線性函式作為啟用函式。
例項
描述
有一批Iris花,已知這批Iris花可分為3個品種,現需要對其進行分類。不同品種的Iris花的花萼長度、花萼寬度、花瓣長度、花瓣寬度會有差異。我們現有一批已知品種的Iris花的花萼長度、花萼寬度、花瓣長度、花瓣寬度的資料。
一種解決方法是用已有的資料訓練一個神經網路用作分類器。
BP網路例項
實驗步驟
將Iris資料集分為2組,每組各75個樣本,每組中每種花各有25個樣本。其中一組作為以上程式的訓練樣本,另外一組作為檢驗樣本。為了方便訓練,將3類花分別編號為1,2,3 。
使用這些資料訓練一個4輸入(分別對應4個特徵),3輸出(分別對應該樣本屬於某一品種的可能性大小)的前向網路。
程式碼
%讀取訓練資料
[f1,f2,f3,f4,class] = textread('trainData.txt' , '%f%f%f%f%f',150);
%特徵值歸一化
[input,minI,maxI] = premnmx( [f1 , f2 , f3 , f4 ]') ;
%構造輸出矩陣
s = length( class) ;
output = zeros( s , 3 ) ;
for i = 1 : s
output( i , class( i ) ) = 1 ;
end
%建立神經網路
net = newff( minmax(input) , [10 3 訓練曲線如下:
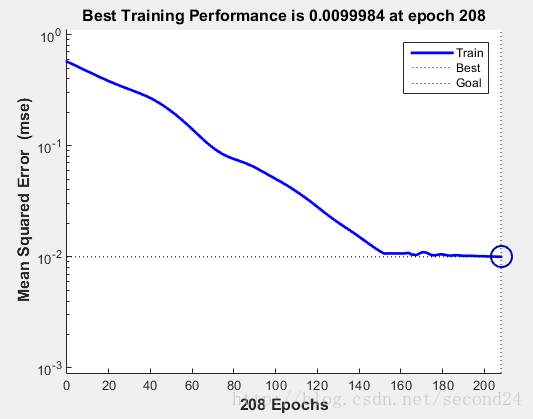
訓練140次左右收斂。最後程式輸出的識別率在95%左右。
引數設定對神經網路效能的影響
<1>隱含層節點個數
隱含層節點的個數對於識別率的影響並不大,但是節點個數過多會增加運算量,使得訓練較慢。
<2>啟用函式的選擇
啟用函式無論對於識別率或收斂速度都有顯著的影響。在逼近高次曲線時,S形函式精度比線性函式要高得多,但計算量也要大得多。
<3>學習率的選擇
學習率影響著網路收斂的速度,以及網路能否收斂。學習率設定偏小可以保證網路收斂,但是收斂較慢。相反,學習率設定偏大則有可能使網路訓練不收斂,影響識別效果。