
利用中文維基語料和Gensim訓練 Word2Vec 的步驟
word2vec 包括CBOW 和 Skip-gram,它的相關原理網上很多,這裡就不多說了。簡單來說,word2vec是自然語言中的字詞轉為計算機可以理解的稠密向量,是one-hot詞彙表的降維表示,代表每個詞的特徵以及保持住了詞彙間的關係。此處記錄將中文詞彙轉為詞向量的過程。
1. 下載中文語料
中文的語料可以從維基百科下載,這些語料庫經常會更新,但都很全面。中文語料下載地址:(https://dumps.wikimedia.org/zhwikisource/20180620/)。因為我只是想熟悉這個過程,就只下了一個比較小的包,只有兩百多兆。
2. 解析語料包
從維基百科下載到的語料包是無法直接使用的,好在有人幫我們解決了這個問題。利用WikiExtractor抽取步驟1下載得到的語料原始包。WikiExtractor下載地址:(
開啟cmd,輸入以下命令解析維基語料,當然首先要把路徑切換到你儲存預料包和WikiExtractor的路徑:
- python WikiExtractor.py -b 400M -o extracted zhwiki-latest-pages-articles.xml.bz2
400M 代表提取出來的單個檔案最大為 400M,這時會產生目錄extracted/AA,其中有一個檔案wiki_00,耗時大概10-15分鐘左右。。因為我的檔案只有兩百多兆,所以為了保險起見我這裡用了400M解析,如果不設定解析檔案的大小,就會預設提出檔案大小為1M,這樣會有很多個檔案,所以為了便於操作,還是直接設定你想要的檔案大小進行解析。
3.繁體轉簡體
維基百科的中文資料是繁簡混雜的,裡面包含大陸簡體、臺灣繁體、港澳繁體等多種不同的資料。有時候在一篇文章的不同段落間也會使用不同的繁簡字。
這裡我使用了opencc 進行繁簡轉換,地址:(https://code.google.com/archive/p/opencc/downloads),我用的是win7系統,所以下載的是 opencc-0.4.2-win32.zip,下完解壓,然後把wiki_00拷貝到opencc資料夾下面,在cmd裡輸入:
- opencc.exe -i wiki_00 -o zh_wiki -c zht2zhs.ini
-i表示輸入檔案,-o表示輸出檔案,檔名zh_wiki,zht2zhs.ini表示繁體轉換為簡體,Traditional to Simplified。
4. 去掉特殊字元
經過上述步驟得到的中文預料中會夾雜著一些特殊字元,如「」「」『』等,新建一個.py檔案,去掉這些特殊字元,程式碼:
# -*- coding: utf-8 -*-
import os
import re
import codecs
def replace_func(input_file):
p1 = re.compile(r'-\{.*?(zh-hans|zh-cn):([^;]*?)(;.*?)?\}-')
p2 = re.compile(r'[(][,;。?!\s]∗[)]')
p3 = re.compile(r'[「『]')
p4 = re.compile(r'[」』]')
outfile = codecs.open(input_file + '_str', 'w', 'utf-8')
with codecs.open(input_file, 'r', 'utf-8') as myfile:
for line in myfile:
line = p1.sub(r'\2', line)
line = p2.sub(r'', line)
line = p3.sub(r'“', line)
line = p4.sub(r'”', line)
outfile.write(line)
outfile.close()
def run():
data_path = '.\\extrated\\AA\\'
data_names = ['zh_wiki']
for data_name in data_names:
replace_func(data_path + data_name)
print('{0} has been processed !'.format(data_name))
if __name__ == '__main__':
run() 5 分詞
利用 jieba,將得到的中文文字進行分詞,並且儲存嚇到新的文字中,以便在gensim中使用:
我這裡將得到的分詞後的本文儲存為:wikidata_segment.txt
import numpy as np
import pandas as pd
import jieba
import os
rootdir = 'E:/Deep_Learning/jupyter_codes/wikepedia chinese/extrated/AA/' # 這是我儲存預料的路徑
oldtxtname = 'zh_wiki_str' #純簡體文字
newtxtname = 'wikidata_segment.txt'
#對wikdpidia中文文字進行分詞,儲存為 wikidata_sic_segment.txt
def segment_txt(rootdir, oldtxtname, newtxtname):
test_dir = rootdir + newtxtname # 儲存已經分詞過的中文文字
if os.path.exists(test_dir): return #如果已經分詞過,則不再進行分詞
else:
with open(rootdir + oldtxtname,'rb') as f:
document = f.read()
document_cut = jieba.cut(document, cut_all =False)
# print('/'.join(document_cut))
result = ' '.join(document_cut)
result = result.encode('utf-8')
with open(test_dir,'wb+') as f1:
f1.write(result)6. 用Gensim 進行訓練
用Gensim對預處理過的中文預料進行訓練,得到word2vec:
我的模型名為:wiki_science.model(因為我的預料庫是與學科相關的~)
from gensim.models import word2vec
import logging
##訓練word2vec模型
def load_model(modelname):
#如果模型存在,則直接匯入模型
if os.path.exists(modelname):
print ('load model>>>>>')
model = word2vec.Word2Vec.load(modelname)
else:
print('train model>>>>>')
#否則,訓練模型。
#獲取日誌資訊
logging.basicConfig(format = '%(asctime)s:%(leveltime)s:%(message)s',level = logging.INFO)
#載入分詞後的文字,使用的是Ttext2Corpus類
sentences = word2vec.Text8Corpus(r'E:\Deep_Learning\jupyter_codes\wikepedia chinese\extrat\AA\wikidata_segment.txt')
#訓練模型,部分引數如下
model = word2vec.Word2Vec(sentences,size = 100,hs = 1,min_count =1,window =6)
print('-----------------分割線---------------------------')
#保留模型,方便重用
model.save(modelname)
return model至此,已經獲得了word2vec,儲存到了wiki_science.model裡,下次要用的時候就可以直接呼叫模型,省去了很長的訓練時間。
7.訓練效果
簡單測試下訓練的效果怎麼樣

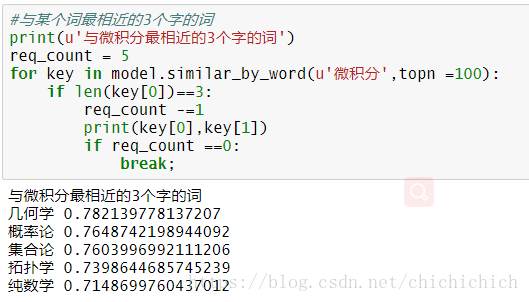
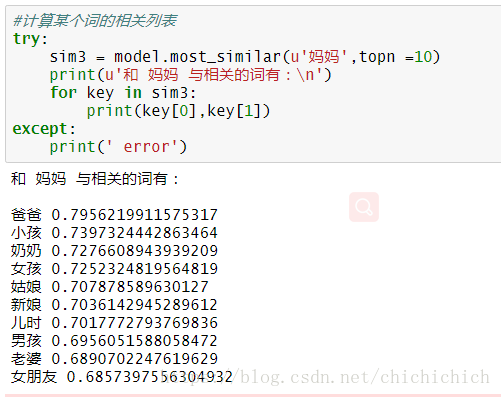

其實接下來可以用T-SNE 對模型進行視覺化,視覺化的結果會很直觀的顯示出同類的詞聚集在一起的效果,這一步以後再補上。其實很多訓練好的模型可以讓我們使用,我們在實際要用的時候不需要自己訓練,下載訓練好的詞向量,用遷移學習方法用就可以了。