
像電腦科學家一樣思考python
18 繼承(inheritance)
繼承 是面向物件程式設計 的一種語言特性;
它能 通過對現有的某個類稍作修改的方式 定義一個新的類。
現有的類 稱為 父類, 新的類 稱為子類。
之所以被稱為 繼承,是因為 子類 包含有 父類中的方法。
17 類 和 方法
17.1 面向物件特性
Python 是一門 面向物件的程式語言。
給出 面向物件程式設計 的定義 並不簡單?我們可以給出 它的一些特性:
- 程式 是由物件定義和函式定義組成,並且 大部分的計算都是用物件的操作來表達;
- 每個物件的定義 對應真實世界的 某些物件或概念,並且操作那個物件的函式 對應了真實世界中 物件之間互動的方式。
迄今為止,我們還沒有利用 Python提供的 面向物件程式設計特性,
嚴格的來說,這些特性 並不是必須的:
它們中 大部分都是我們已經做過的事情 的另一種選擇方案;
但是,這種方案 更加簡潔,更能準確表達程式的結構。
例如:在 Time 程式中,類定義 和 其函式定義 並沒有明顯的關聯。
但實際上,(有關聯)每個函式都至少接受一個 時間物件 作為引數。
這就是 方法 的由來:一個方法,即,一個和某特定 類 相關聯的函式。
我們已經見過、使用過內建型別 的方法,
下面我們的 目標是:為 使用者自定義的型別 定義 方法。
方法 和 函式在語義上是一樣的,但在語法上有兩個區別:
1.方法定義 寫在 類定義之內,更明確地表示 方法和該類的關聯;
2.呼叫 方法和函式 的語法形式不同。
如果能夠 輕鬆地在 定義函式和定義方法 之間轉換,
也就能夠 在任意情況下 選擇最合適的形式了。
17.5 init 方法和 str 方法
__init__ init 方法 是一個特殊的方法,當物件初始化時會被呼叫;
__str__ str 方法 是另一個特殊方法,它用來返回物件的字串形式,當你列印物件時,Python 會呼叫 str 方法。
當我編寫一個新類時,我總是開始先寫
__init__,以便初始化物件,然後會寫__str__,以便列印除錯。
class Time(object):
"""Represents the time of a day.""" 例項化一個time,列印一下:
time = Time(3)
print(time)17.7 過載操作符
定義 其他的 特殊方法,例如:__add__ 可以將 +操作符 過載,
即,使用 +操作符 將兩個時間物件相加。
def int_to_time(seconds):
time = Time()
minutes,time.second = divmod(seconds,60)
time.hour,time.minute = divmod(minutes,60)
return time
class Time(object):
"""Represents the time of a day."""
def __init__(self,hour=0,minute=0,second=0):
self.hour = hour
self.minute = minute
self.second = second
def __str__(self):
return '%.2d:%.2d:%.2d'%(self.hour,self.minute,self.second)
def __add__(self,other):
seconds = self.time_to_int()+other.time_to_int()
return int_to_time(seconds)
def time_to_int(self):
return self.hour*60*60+self.minute*60+self.second17.8 基於型別的分發
(type-based dispatch)
def __add__(self,other):
if isinstance(other,Time): # other 是否是 Time型別 的一個例項?
return self.add_time(other)
else:
return self.increment(other)
def add_time(self,other):
seconds = self.time_to_int()+other.time_to_int()
return int_to_time(seconds)
def increment(self,seconds):
seconds += self.time_to_int()
return int_to_time(seconds)分發:
結合 __add__ 和 increment 兩個版本的加法方法,
在呼叫時,如果 other 是一個時間物件,那麼呼叫方法 __add__ ;
否則,認為該引數是一個整數,呼叫方法 increment 。
但是,即使有兩種加法,也不能處理所有情況:例如,
increment 要求時間物件必須出現在左側,出現在右側時不知如何解決。
好在,這裡有一個很好的解決方案:右加法(right-side add)
def __radd__(self,other):
return self.__add__(other)17.9 多型
基於型別的分發很有用,但是,我們並不是總需要它;
因為,通常可以 編寫 可處理不同型別的引數 的函式 來避免。
可以處理多個型別的函式 稱為 多型(polymorphic)。例如:
def histogram(s):
d = dict()
for c in s:
if c not in d:
d[c] = 1
else:
d[c] = d[c]+1
return d這個函式 對列表、元組、字典等型別都可以,(只要 s 的元素是可雜湊的,可以作為 d 的鍵即可。)
總的來說,如果函式內部 所有的操作都支援某種型別,那麼這個函式 就可以用於(支援)這個型別。
17.10 除錯
雖然,在程式的任意時刻,向物件上新增 屬性都是合法的;
但是,在init方法中,初始化全部的屬性,是一個好習慣。
hasattr 可以檢視 一個物件是否擁有某個屬性;
__dict__:是一個特殊方法,像是一個存放屬性的字典。
利用它,實現一個函式:以遍歷物件的所有屬性,並輸出其值。
def print_attributes(obj): # 列印每個屬性的名稱和相應的值
for attr in obj.__dict__:
print(attr,getattr(obj,attr))17.11 介面與實現
將 介面與實現分開,意味著:
你需要將屬性隱藏起來。
程式的其他部分的程式碼(類定義之外的),應當使用方法來讀寫物件的狀態,
而不應當直接訪問屬性。這個原則叫做資訊隱藏(information hiding)
類 所提供的方法,應該不依賴於 其屬性的表達形式
例如:我們如何表達時間的概念?
時間物件的屬性是,hour、minute、second
還是另一種方案,統一將這些屬性轉換成一個單一的整數。
16 類 和 函式
16.1 時間
class Time(object):
"""Represents the time of day."""
time = Time()
time.hour = 11
time.minute = 59
time.second = 3016.3 純函式
純函式 和 修改器——原型 和 補丁(prototype and patch)
這是一種 應對複雜問題的方法,從一個簡單的原型開始,並逐漸解決更多的問題。
# 純函式:僅僅返回一個值,並不修改作為實參傳入的任何物件,
# 也沒有如顯示值或獲得使用者輸入之類的副作用
def add_time(t1,t2):
sum = time()
sum.hour = t1.hour+t2.hour
sum.minute = t1.minute+t2.minute
sum.second = t1.second+t2.second
return sum【注】:這個函式,並沒能處理 時分秒 的進位問題。
16.3 修改器(modifier)
有時候,使用函式 修改傳入的引數物件 是很有用的。
這種情況下,修改 對呼叫者 是可見的。這樣工作的函式 稱為 修改器。
def increment(time,seconds):
time.seconds += seconds任何 可以使用修改器做到的功能 都可以使用 純函式實現。
事實上,有的程式語言 只允許使用 純函式。(錯誤更少,開發更快,效率更高)
推薦:總的來說,儘量編寫純函式,只在 有絕對說服力的原因時 使用修改器,這種方法可以稱作 函數語言程式設計風格
16.4 原型和計劃
原型和計劃 VS 有規劃開發
- 原型和計劃方法 在你對問題的理解並不深入時尤為有效。
(我編寫一個可以進行基本計算的原型,再測試它,從中發現錯誤並打補丁) - 有規劃開發方法——對應你對問題有了更高階的理解
例如:時間物件實際上是 六十進位制的3位數,
秒:個位數;分:60位數;時:360位數
於是,考慮整個問題的另一種解決方法是:時間物件與整數的轉換(計算機本身知道如何做整數的運算(進位等))
def time_to_int(time):
minutes = time.hour*60+time.minute
seconds = minutes*60+time.second
return seconds
def int_to_time(seconds):
time = Time()
minutes,time.second = divmod(seconds,60)
time.hour,time.minute = sivmod(minutes,60)
return time
def add_time(t1,t2)
seconds = time_to_int(t1)+time_to_int(t2)
return int_to_time(seeconds)有意思的是,有時候 把一個問題弄得更難(或者更通用),反而會讓它簡單(因為會有更少的特殊情況和更少的出錯機會)
16.5 除錯
不變式:總是為真的條件
如:三個值都大於0,且 minute 和 hour 應當是整數,minute 和 second 的值應當在 0 到 60 之間
編寫程式碼來檢查 不變式 可以幫助我們探測錯誤並尋找錯誤根源:例如
def valid_time(time): # 不合法 時間物件
if tiem.hour<0 or time.minute<0 or time.second<0
return False
if time.minute>=60 or time.second>=60
return False
return True
# 方法一 使用 raise 檢查引數(在函式開頭)
def add_time(t1,t2)
if not valid_time(t1) and not valid_time(t2):
raise ValueError, 'invalid Time object'
seconds = time_to_int(t1)+time_to_int(t2)
return int_to_time(seeconds)
# 方法二 使用 assert 檢查引數
def add_time(t1,t2)
assert valid_time(t1) and valid_time(t2)
seconds = time_to_int(t1)+time_to_int(t2)
return int_to_time(seeconds)assert 語句很有用,它會檢查一個給定的不變式,並當檢查失敗時 丟擲異常。
它 區分了 處理普通條件的程式碼 和 檢查錯誤的程式碼
15 類 和 物件
15.1 使用者定義型別
我們已經使用了很多 python 的 內建型別,現在我們要定義一個 新型別。
型別 類(class)
class Point(object) # 定義頭,新的類:point,是內建型別object的一種
"""Represents a point in 2-D space.""" # 定義體,解釋文件字串
blank = Point() # 例項化例項化(Instantiation):新建一個物件的過程 稱為例項化。
關於python中的object的理解
當我們自己去定個一個類及例項化它的時候,和上面的物件們又是什麼關係呢?
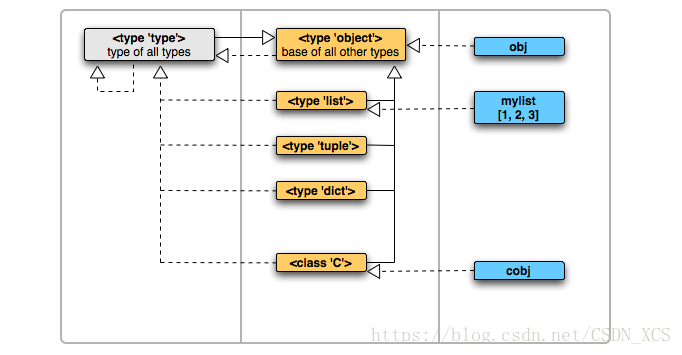
白板上的虛線表示源是目標的例項,實線表示源是目標的子類。
即,左邊的是右邊的型別,而上面的是下面的父親。
虛線是跨列產生關係,而實線只能在一列內產生關係。除了type和object兩者外。
15.2 屬性(Attribute)
屬性(Attribute):一個物件的 有命名的元素
# 變數 blank 引用向 一個Point物件,它包含兩個屬性。
# 每個屬性 引用 一個浮點數
blank.x = 3.0
blank.y = 4.0
# 找到blank 引用的物件,並取得它的 x屬性的值。
print(blank.x)15.5 物件是可變的
def grow_rectangle(rect,dwidth,dheight)
rect.width += dwidth
rect.height += dheight可以將 blank 這個例項,作為函式實參 按照通常的方式傳遞。
(在函式內修改值,blank 也會被修改)
函式 也可以返回例項。
15.6 複製(copy.copy)
使用別名的 常用替代方案是 複製物件。
(因為跟蹤掌握 所有引用到一個給定物件 的變數,是困難的)
p2 = copy.copy(p1) copy模組 裡有一個copy函式 可以複製任何物件。
【注】:此處,copy.copy為淺複製(shallow copy),只複製物件和該物件包含的引用,但步複製內嵌物件。
box3 = copy.deepcopy(box) copy模組 裡有一個deepcopy函式 不但複製物件,且複製物件中的物件,稱為深複製(deep copy)。
【注】:此時,box3和box是兩個完全分開的物件。
15.7 除錯
如果 訪問了一個並不存在的屬性,會得到錯誤:
AttributeError: xxx instance has no attribute ‘xx’
type(p) 詢問物件的型別
hasattr(p,'x') 某物件是否有某個屬性
14 檔案(跳過)
13 案例(跳的)
12 元組(跳過)
12.1 元組是不可變的
元組和列表很像,都是一個值的序列,且值可以是任意型別,且按照整數下標索引
但是,元組是不可變的。
t1 = ('a','b','c','d') 新建元組(小括號+逗號)
l1 = ['a','b','c','d'] 新建列表(中括號+逗號)
str = 'abcd' 新建字串
t2 = tuple('abcd') 另一種新建一個元組(本質是 將其他型別 轉換為元組),
列表的大多數操作(下標操作符、切片操作符)均可作用於元組;
但是,元組的元素不能被修改。更類似字串一些?
12.4 元組賦值
收集(gather):將所有的引數 收集到一個元組上;
分散(scatter):有一個序列,將他們作為各個引數分開。
12.5 列表 和 元組
zip 是一個內建函式,接收多個序列,將他們“拉”到一起,成為一個元組列表
11 字典
字典類似於列表。
在列表中,下標 必須是 整數;
在字典中,下標 (幾乎)可以是任意型別。
可以把 字典看作 下標(稱為鍵)集合 與 值集合之間的 對映。
每一個 鍵,都對映到一個值上。
鍵和值之間的關聯 被稱為 鍵值對(key-value pair),或者有時稱為一項(item)
eng2sp = dict() 新建一個不包含任何項的字典;
eng2sp['one'] = 'uno' 新增新項,使用方括號操作符;
print eng2sp 列印字典;
【注】:列印時發現,字典中各項的順序是不可預料的;
但好在順序並不重要,只要 鍵 總是對映到 值 上。
len(eng2sp) 返回鍵的個數;
'one' in eng2sp 檢視一個值 是不是 字典中的鍵;
vals = eng2sp.values() 檢視一個值 是不是 字典的值;
'uno' in vals
in 操作符,對於列表,python 使用搜索演算法。(列表越長,搜尋時間越長)
對於字典,python用一個稱為 散列表(hashtable) 的演算法。(時間與字典規模無關)
11.1 使用 字典 作為計數器集合
假定給定一個字串,你想要計算每個字母出現的次數。有幾種可能的實現方法:
- 建立26個變數;
- 建立一個包含26個元素的列表;
- 建立一個字典。
實現(implementation) 是進行某種計算的一個具體方式。
def histogram(s) # 統計字串 s 中字元出現的次數
d = dict()
for c in s:
if c not in d:
d[c] = 1 # 字元是鍵,次數是值
else:
d[c] =+ 1
return d直方圖(histogram):統計出現的頻率
h.get('a',0) 字典中的一個方法,接受一個 鍵和一個 預設值
11.2 迴圈 和 字典
for 迴圈遍歷字典,鍵
def print_hist(h):
for c in h: # 使用鍵來遍歷
print c,h[c]11.3 反向查詢
查詢(lookup):指 根據 鍵 找到 值;
反向查詢:是指根據 值 找到 鍵。(速度遠遠慢於 查詢)
並沒有進行 反向查詢的簡單語法,需要使用遍歷
另外,可能存在多個鍵對映在同一個值上的情況(或者挑選其中一個鍵?或者儲存所有鍵在一個列表裡?)
11.4 字典 和 列表
列表 可以在字典中 以值的形式出現。
字典1:字元中 的字元是鍵,出現的頻率是值;
反轉字典1:字元中 出現的頻率作為 鍵,確實以該頻率出現的字元 是 值。
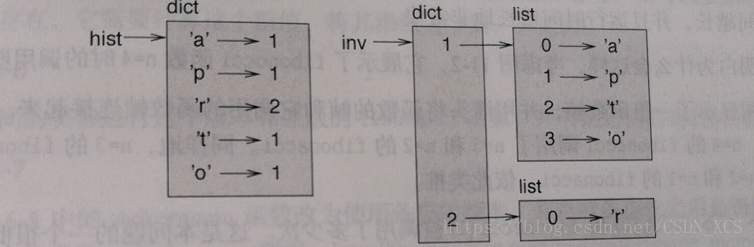
def inverse_dict(d): # 原字典是 d,反轉後的字典是 inverse
inverse = dict()
for key in d
val = d[key]
if val not in inverse:
inverse[val] = key
else:
inverse[val].append(key) # inverse的值是 列表
return inverse鍵 必須是 可雜湊的(hashable),像列表這樣的可變型別是 不可雜湊的。
雜湊 是一個函式,接受(任意型別)的值,並返回一個整數
11.5 備忘(Memo)
解決 Fibonacci 數列遞迴時,效率低的問題的一個方案是:
記錄已經計算過的值,並將它們儲存在一個字典中。
將之前計算的值儲存起來,以便後面使用的方法 稱為備忘(Memo)
known = {0:0,1:1} # known是一個已知的 Fibonacci數 的字典
def fibonacci(n): # 注意! known 被之間訪問了
if n in known:
return known[n]
res = fibinacci(n-1)+fibonacci(n-2)
known[n] = res
return res
known 是 在函式之外建立的,屬於被稱為
__main__的特殊幀。
__main__之中的變數有時被稱為 全域性變數,它們可以被任意函式訪問,一般情況下需要在函式中使用 global 宣告!
為什麼此處 known 沒有用 global 宣告,直接使用了呢?
如果,全域性變數是可變的,你可以不用宣告它,就直接進行【修改】——即,新增、刪除、替換
但是,如果想要給全域性變數重新賦值!則需要宣告它:
known = {0:0,1:1}
def example():
global known # 注意區別
known = dict()11.8 除錯
當你使用更大的資料集時,通過 列印和手動檢查資料的方式 來除錯已經 變得笨拙了。下面是一些除錯大資料集的建議:
- 縮小輸入:如果可能,減小資料的尺寸(逐步增大)
- 檢查資料集的概要資訊和型別,而不是整個資料集:如字典中條目的數目,列表中數的和
- 編寫自檢查邏輯,使程式碼自動檢查:(如求平均,檢查結果是否比最大數小,或者最小數大)
- 美化輸出:格式化輸出,更容易發現錯誤。pprint 函式(更人性化的可讀格式列印)
10 列表(List)
10.1 列表是一個序列
列表 是 值的序列。
在字串中,這些值是 字元;
在列表中,這些值可以是 任何型別,且可以是 不同型別的。
10.2 列表是可變的
可以把 列表看作是 下標和元素的關聯。這種關聯稱為對映(mapping)。
每一個下標 對映到 元素中的一個。
10.3 遍歷一個列表
當僅僅需要讀取列表元素本身時,for 迴圈的遍歷方式很好
for cheese in cheeses:
print cheese當 需要寫入或更新元素時,則需要下標,常見的方式是使用函式range 和 len:
for i in range(len(numbers)): #range(n) 返回一個下標的列表:0到n-1
numbers[i] = numbers[i]*210.4 操作
+ 操作符 拼接列表
* 操作符 重複列表
t[1:3], t[:] 切片;
因為列表是可變的,在進行摺疊、拉伸或破壞操作之前,複製一份很有必要
10.6 列表的方法
t.append('d') 在尾部新增新元素;
t.extend(t2) 將另一個列表的所有元素 附加到當前列表中
t.sort() 將列表元素從低到高排序
(列表的方法全都是無返回值的)
10.7 化簡、對映和過濾
化簡(reduce):將一個序列的元素值合起來 到一個單獨的變數的操作
- 累加器(accumulator):
sum(t)
對映(map):它將一個函式 “對映”到一個序列的每一個元素上
- 例如:將列表的元素都大寫
過濾(filter):它選擇列表中的某些元素,並過濾掉其他的元素。
列表中的絕大多數操作都可以用 化簡、對映和過濾 的組合來表達。
因為 這些操作非常常見,Python 提供了語言特性 直接支援它們。
10.8 刪除元素
如果 你知道要刪除元素的下標:
x = t.pop()刪除該元素,並返回該元素的值;不提供下標,是指最後一個元素del t[1]直接刪除del t[1:5]刪除多個元素(從第一個下標開始,到第二個下標為止(不包含))
如果你知道 待刪除元素的值:
t.remove('b')返回值是None
10.9 列表 和 字串
字元的列表 != 字串
t = list(s) 將 一個字串 轉換為 一個字元的列表;
t = s.split() 將字串(一句話) 拆成一個個單詞放在列表裡;
delimiter = ' ' split 的逆操作,接受字串列表,拼接成長字串。
delimiter.join(t)
liist 是內建函式,應避免將其用作變數名
10.10 物件 和 值
兩個列表是 相等的(equivalent);
但卻不一定是 相同的(identical)。
對於同一個物件的兩個引用,它們引用的物件是相同的,且一定有也是相等的;
對於不同物件的兩個引用,它們有可能是相等的,但不能說它們是相同的。
10.11 別名
當一個物件有多個引用,且引用有不同的名稱時,稱這個物件有別名(aliase)
如果,處理的是可變物件,避免使用別名會更安全。(除非知道自己在使用)
【注意】:以下兩句,是有很大區別滴!
a = [1,2,3]
b = a # b,a 兩個變數引用 同一個物件
c = a[:] # c 和 a是相等的,但,不是相同的,引用不同的物件!
b[1]=3 # b,a 發生相同的改變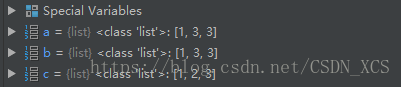
10.12 列表引數
當 將一個列表作為引數 傳入函式中,函式會得到 這個列表的一個引用。
如果函式修改了列表引數,則 呼叫者 也能看到該修改。
區分,修改列表的操作 和 新建列表的操作 很重要!
t1 = [1,2]
t1.append(3) # 修改 t1,增加了一個元素
t2 = t1+[4] # t1 不發生變換,新建了列表 t2
del t1[0] # 刪除 t1 的第一個元素
t3 = t1[1:] # t1 不變, 新建了列表 t310.13 除錯
- 列表的大部分 方法,都是修改引數並返回 None 的;(因為列表是可變的)
相對應,字串的方法,都是新建一個字串,原字串不變;(字串不可變)
補充列表的方法的文件 - 選擇一種風格,堅持不變!
列表的問題之一 就是,同樣的事情有太多種可能的做法! - 通過複製,來避免別名。
8. 字串
8.1 字串是一個序列
字串 是一個字元 序列(sequence)
可以使用 方括號操作符 來訪問單獨的字元,
方括號中的 表示式稱為下標(index)
fruit = 'banana'
letter = fruit[1] # 則 letter 中存放 a對電腦科學家而言,下標 表示的是離 字串開頭的偏移量。 第一個字母的偏移量是0
8.2 len
len 是一個內建函式,返回 字串中字元的個數。
那麼,想要獲取最後一個字元,可以這麼寫:
length = len(fruit)
last = fruit[length-1]或者,可以使用 負數下標
fruit[-1] #最後一個字母
fruit[-2] #倒數第二個字母8.3 使用 for 迴圈進行遍歷(traversal)
方法1:使用 while 迴圈
index = 0
while index<len(fruit)
print(fruit[index])
index = index+1方法2:使用 for 迴圈
for char in fruit
print char每次迭代中,字串中的下個字元 會被賦給 變數char。
迴圈會繼續,直到沒有剩餘的字元為止。
8.4 字串切片(slice)
操作符 [n:m] 返回字串從 第n個字元 到 第m個字元 的部分。
包含 第n個字元,但不包含 第m個字元
8.5 字串是不可變的
字串是不可變的(immutable),也就是說,不能修改一個已經存在的字串。
greeting = 'Hello, World!'
greeting[0] = 'J' # 會出錯!只能新建字串 使用切片拼接起來
new_greeting = 'J'+greeting[1:]8.6 搜尋 find
python 本身是 存在該方法的(函式?)
def find(word,letter)
index = 0
while index<len(word)
if word[index] == letter
return index
index = index+1
return -1從某種意義上,find 是 [ ] 操作符的反面。
[ ] 操作符,通過一個下標查詢對應的字元;
find ,根據一個字元 查詢其在字串中的下標。
【注】:標準庫中存在 find 方法,並且:

8.8 字串方法
方法和函式很類似,——它接受形參並返回值;
但語法有所不同。
例如:接收一個字串,並返回一個將其全部字母均大寫的字串
使用語法的不同 體現在:
函式版:upper(word)
方法版:word.upper() #句點表示法,指定了方法的名稱,以及方法作用的字串名稱
strip 和 replace特別有用
strip: remove all coverings from 移除覆蓋物
移除兩端的空格

replace 替換

8.10 字串比較
所有大寫字母 都在 小寫字母之前。
處理這個問題的常用辦法:先將字串都轉換成 標準的形式(如都大寫或小寫)
8.11 除錯
當使用下標來遍歷序列中的值時,要正確實現遍歷的開端和結尾需要留心。
必要時,可以列印 索引值。
7. 迭代
7.4 break語句
一種常見的寫 while 迴圈的方式:
while True:
line = input('>')
if line == 'done':
break
print line
print 'done!'這種方式有兩個優點:
- 可以把判斷迴圈條件的邏輯放在迴圈的任意地方(而不只是在頂端);
- 可以用肯定的語氣來表示終結條件(“當這樣發生時,停止迴圈”),而不是否定語氣(“繼續執行,直到那個條件發生”)
7.5 平方根
牛頓法 是計算平方根的方法之一。
基於一個簡單的直覺:
在比較小的範圍內,某點的切線可以代替曲線,
且求該切線的零點可以讓我們向 真實的零點靠近。
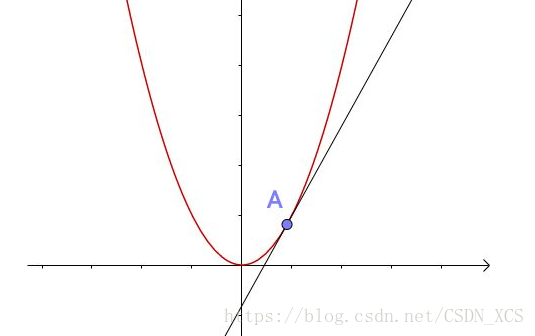
整理即得迭代公式:
特例:求平方根演算法程式實現
while True:
print x0
x = (x0+a/x0)/2
if abs(x-x0)<epsilon:
break
x0 = x終止條件用精度控制,epsilon的值為 0.0000001,近似度是足夠的。
7.6 演算法
定義演算法並不容易。
牛頓方法是 演算法 的一個例子:它是解決一類問題的機械化過程。
演算法的特點是,不需要任何聰明才智就能執行。
人類花費如此多的時間 在學校學習如何執行演算法。。。有寫尷尬;
另一方面,設計演算法 的過程則充滿趣味和挑戰!也是程式設計的核心成分之一。
有時,我們自然而然、毫不費力做的事情,用演算法表達卻很困難。
我們都能夠理解自然語言,但是迄今為止,還沒有人能夠解釋我們怎麼做到的,至少還沒用演算法解釋。
7.7 除錯
二分除錯(debugging by biseection)
當開始編寫 更大的程式時,
找到程式的中點,一個可以檢驗中間結果的地方,
如果檢驗結果錯誤,則錯誤出現在前半部分;如果正確,則在後半部分。
應當思考,哪些地方可能出現錯誤,
哪些地方容易加上檢驗,
然後選擇一個其前後發生錯誤機率差不多的地方進行檢驗。
6. 有返回函式
6.2 增量開發
增量開發 的目標是,通過每次只增加一小部分程式碼,來避免長時間的除錯過程。
關鍵點是:
- 以一個可以正確執行的程式開始,每次只做小的增量修改。如果在任意時刻發生錯誤,你都應當知道錯誤在哪裡。
- 使用臨時變數儲存計算的中間結果,這樣可以顯示和檢查它們;
- 一旦整個程式完成,你可能會想要刪除某些腳手架程式碼(scaffolding)或者把多個語句整合到一個複雜表示式中。但只在不增加程式碼閱讀難度時才這麼做。
6.5 再談遞迴
至今為止,我們只涉及到 python 的一個很小的子集,
但是,這個子集已經是一個 完備的程式語言了呦!
即,任何可以計算的問題,都可以用這個子集語言來完成;任何已有的程式,都可以用現在已經學會的語言特性重寫出來。
6.6 堅持信念
跟蹤程式執行的流程 是閱讀程式的一個辦法。但容易陷入迷宮境地。
另一個辦法就是堅持信念,
即,當你遇到一個函式呼叫時,不去跟蹤執行的流程,而假定函式是工作的!能返回正確結果的!
以 遞迴函式為例:
假設我能夠 正確得到的階乘,如何計算的階乘?
6.8 檢查型別
讓 factorial 函式檢查其實參的