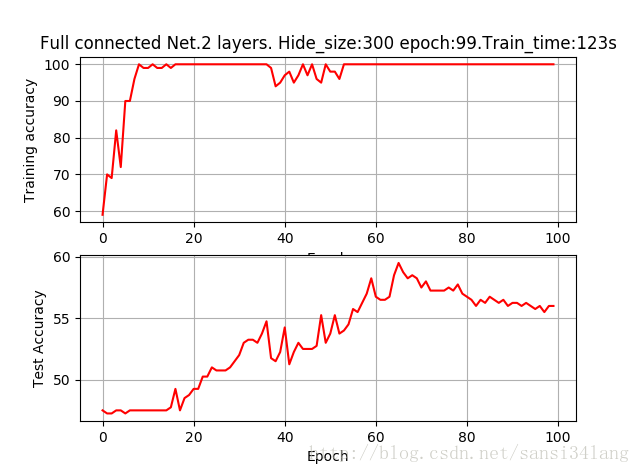
FER實際訓練過程記錄 genki4k資料集
阿新 • • 發佈:2019-01-25
文獻記載 使用RBF核的SVM在genki4k的test acc為93.2%
全連線神經網路
64*64解析度 2層
| hide_size | epoch | train_acc | test_acc |
|---|---|---|---|
| 100 | 100 | 88 | 55 |
| 100 | 200 | 93 | 57.5 |
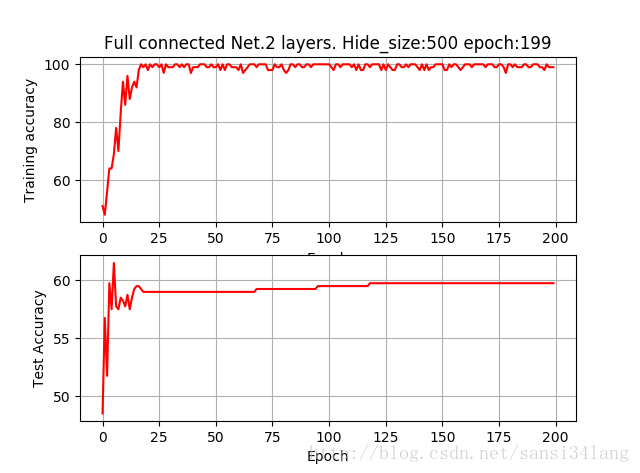
| 500 | 200 | 100 | 60 |
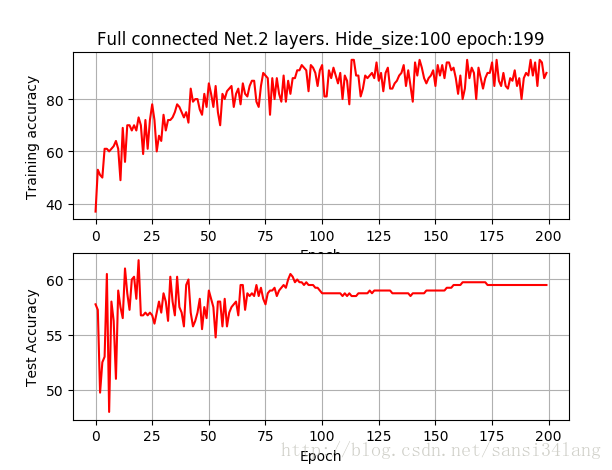
全連線層2層,hide_size為100,訓練200個epoch即可達到較高的訓練準確率,測試準確率只有58%,訓練500個epoch圖形基本相同。hide_size為500時,很快訓練準確率達到100%,耗時更多而test acc僅提高到60%,如下圖
加入dropout=0.5,
| hide_size | epoch | train_acc | test_acc | time |
|---|---|---|---|---|
| 100 | 200 | 60 | 48.8 404s | |
| 100 | 2000 | 75 | 57 | 2600s |
加入dropout防止過擬合,訓練2000epoch,訓練acc為75%,而實際上得到的test acc依然和不加dropout 200epoch的準確率差不多,是否說明經過2000epoch達到的model係數,已經是最優的?模型的可提升空間只能靠more data?
CNN
64*64解析度 2層Conv和Pool 兩層FC
(由於train_test_split的random種子不同,因而同等情況下,每組測試準確率存在一定差異)
| patch_size | epoch | train_acc | test_acc | train_time |
|---|---|---|---|---|
| 6 | 10 | 75 | 66 | 827s |
| 5 | 10 | 80 | 60 | 480s |
| 5 | 20 | 83 | 70 | 808s |
| 5 | 100 | 100 | 73 | 3660s |
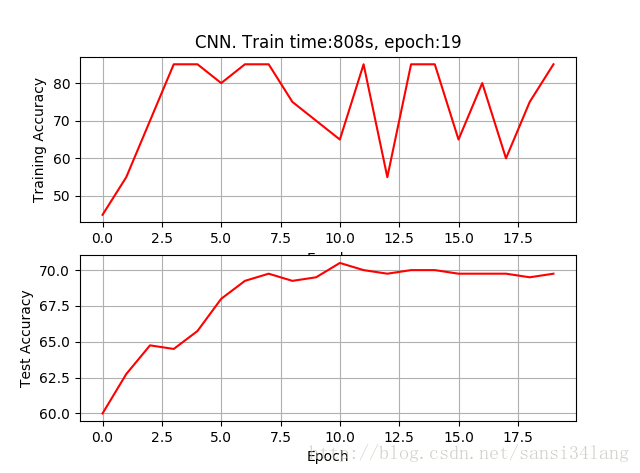
再將epoch加到100,當訓練到20epoch時,訓練準確率即達到100%,測試準確率72%,到100epoch,耗時3660s,測試準確率73%。
本想嘗試將所有訓練集資料帶入模型求一個整體訓練集的準確率,但因訓練集資料太多(n*64*64*3),維度太大,導致程式崩潰。
經過試驗,基本上25個epoch,即可達到訓練結果的視覺化冗餘,同全連線層一樣存在較嚴重的過擬合問題
加入dropout=0.5,結果如下,準確率甚至下降
patch_size epoch train_acc test_acc
5 25 60-70% 59.2
64*64解析度 3層Conv和Pool 兩層FC
| patch_size | epoch | train_acc | test_acc | train_time | 卷積層數 | 備註 |
|---|---|---|---|---|---|---|
| 5 | 20 | 83 | 70 | 808s | 2 | |
| 5 | 20 | 89 | 65.2 | 1230s | 3 | |
| 5 | 30 | 94.6 | 70 | 1369s | 3 | 3層fc,random_state=1(含以下) |
| 5 | 30 | 67 | 61.8 | 1322s | 3 | keep_prob=0.8 |
| 5 | 50 | 96.7 | 73.4 | 1960s | 3 | keep_prob=0.95 |
| 5 | 50 | 94.8 | 75.5 | 2357 | 3 | keep_prob=0.9 |
| 5 | 50 | 88.1 | 70.5 | 2548 | 3 | keep_prob=0.85 |
| 5 | 50 | 90.1 | 71 | 2005 | 3 | keep_prob=0.88 |
| 5 | 50 | 97 | 77 | 3490 | 3 | keep_prob=0.92 |
| 5 | 50 | 91.4 | 74.4 | 1964 | 3 | keep_prob=0.92,random_state=0 |
Hog 深度神經網路(3層,h1=300,h2=100)
hog特徵提取,
hide1_size h2_size train_acc test_acc train_time
300 100 100 56 123s