
利用tensorflow訓練自己的圖片資料集——資料準備
昨天實現了一個簡單的CNN網路。用了MNIST資料集,雖然看來對這個資料集用的很多,但是真正這個資料集是怎麼在訓練的時候被呼叫的,以及怎麼把它換成自己的資料集都是一臉懵。
作者給的程式碼是python2.x版本的,我用的python3.5,改了一些錯誤。
import numpy as np import struct import os import matplotlib.pyplot as plt import pickle import gzip _tag = '>' #使用大端讀取 _twoBytes = 'II' #讀取資料格式是兩個整數 _fourBytes = 'IIII' #讀取的資料格式是四個整數 _pictureBytes = '784B' #讀取的圖片的資料格式是784個位元組,28*28 _lableByte = '1B' #標籤是1個位元組 _msb_twoBytes = _tag + _twoBytes _msb_fourBytes = _tag + _fourBytes _msb_pictureBytes = _tag + _pictureBytes _msb_lableByte = _tag + _lableByte def getImage(filename = None): binfile = open(filename, 'rb') #以二進位制讀取的方式開啟檔案 buf = binfile.read() #獲取檔案內容快取區 binfile.close() index = 0 #偏移量 numMagic, numImgs, numRows, numCols = struct.unpack_from(_msb_fourBytes, buf, index) index += struct.calcsize(_fourBytes) images = [] for i in range(numImgs): imgVal = struct.unpack_from(_msb_pictureBytes, buf, index) index += struct.calcsize(_pictureBytes) imgVal = list(imgVal) #for j in range(len(imgVal)): # if imgVal[j] > 1: # imgVal[j] = 1 images.append(imgVal) return np.array(images) def getlable(filename=None) : binfile = open(filename, 'rb') buf = binfile.read() #獲取檔案內容快取區 binfile.close() index = 0 #偏移量 numMagic, numItems = struct.unpack_from(_msb_twoBytes,buf, index) index += struct.calcsize(_twoBytes) labels = [] for i in range(numItems): value = struct.unpack_from(_msb_lableByte, buf, index) index += struct.calcsize(_lableByte) labels.append(value[0]) #獲取值的內容 return np.array(labels) def outImg(arrX, arrY, order): #根據指定的order來獲取集合中對應的圖片和標籤 test1 = np.array([1,2,3]) print(test1.shape) image = np.array(arrX[order]) print(image.shape) image = image.reshape(28,28) label = arrY[order] print(label) outfile = str(order) + '_'+str(label) + '.png' plt.figure() plt.imshow(image, cmap="gray_r") # 在MNIST官網中有說道 “Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).” plt.show() #plt.savefig("./" + outfile) #儲存圖片 """ The second method """ def load_data(filename = None): f = gzip.open(filename, 'rb') training_data, validation_data, test_data = pickle.load(f,encoding='bytes') return (training_data, validation_data, test_data) def test_cPickle(): filename = 'MNIST_data/mnist.pkl.gz' training_data, validation_data, test_data = load_data(filename) print(len(test_data)) outImg(training_data[0],training_data[1], 1000) #print len(training_data[1]) def test(): trainfile_X = 'MNIST_data/train-images.idx3-ubyte' trainfile_y = 'MNIST_data/train-labels.idx1-ubyte' arrX = getImage(trainfile_X) arrY = getlable(trainfile_y) outImg(arrX, arrY, 1000) if __name__ == '__main__': #test_cPickle() #test the second method test() #test the first method
附上百度百科中魔數的概念(magic number):
很多型別的檔案,其起始幾個位元組的內容是固定的。根據這幾個位元組的內容可以確定檔案的型別,因此這幾個位元組的內容被稱為魔數。此外在一些程式程式碼中,程式設計師常常將在程式碼中出現但沒有解釋的數字常量或字串稱為魔數 (magic number)或魔字串。
訓練分類自己的圖片
找了好幾個部落格做參考,但都有很多的錯誤,沒改好
我從CK+表情資料庫裡選了一些原圖作為我的資料集(此處程式碼和結果已刪)
接下來的任務是要把昨天與今天的東西結合起來。
明天待續……
-------18/7/20更新-------
整理一下大致的流程思路
- 上網爬取所需的圖片(我把這個也算作一塊知識點)
- 將不同大小的圖片轉換成相同的大小(這部分還是有一點小問題沒有改好,可以直接看星爺的部落格:利用Tensorflow構建自己的圖片資料集TFrecords這一節)
- 對上步得到的圖片進行處理(分類製作、banch處理)得到網路的輸入(附上程式碼如下)
把前兩天的程式碼做了修改,檢視預處理效果的時候,可以顯示彩色影象並直接標註屬於何種表情
import os import numpy as np from PIL import Image import tensorflow as tf import matplotlib.pyplot as plt angry = [] label_angry = [] disgusted = [] label_disgusted = [] fearful = [] label_fearful = [] happy = [] label_happy = [] sadness = [] label_sadness = [] surprised = [] label_surprised = [] def get_file(file_dir): # step1:獲取'F:/Python/PycharmProjects/DeepLearning/CK+_part'下所有的圖片路徑名,存放到 # 對應的列表中,同時貼上標籤,存放到label列表中。 for file in os.listdir(file_dir + '/angry'): angry.append(file_dir + '/angry' + '/' + file) label_angry.append(0) for file in os.listdir(file_dir + '/disgusted'): disgusted.append(file_dir + '/disgusted' + '/' + file) label_disgusted.append(1) for file in os.listdir(file_dir + '/fearful'): fearful.append(file_dir + '/fearful' + '/' + file) label_fearful.append(2) for file in os.listdir(file_dir + '/happy'): happy.append(file_dir + '/happy' + '/' + file) label_happy.append(3) for file in os.listdir(file_dir + '/sadness'): sadness.append(file_dir + '/sadness' + '/' + file) label_sadness.append(4) for file in os.listdir(file_dir + '/surprised'): surprised.append(file_dir + '/surprised' + '/' + file) label_surprised.append(5) # 打印出提取圖片的情況,檢測是否正確提取 print("There are %d angry\nThere are %d disgusted\nThere are %d fearful\n" %(len(angry), len(disgusted), len(fearful)),end="") print("There are %d happy\nThere are %d sadness\nThere are %d surprised\n" %(len(happy),len(sadness),len(surprised))) # step2:對生成的圖片路徑和標籤List做打亂處理把所有的合起來組成一個list(img和lab) # 合併資料numpy.hstack(tup) # tup可以是python中的元組(tuple)、列表(list),或者numpy中陣列(array),函式作用是將tup在水平方向上(按列順序)合併 image_list = np.hstack((angry, disgusted, fearful, happy, sadness, surprised)) label_list = np.hstack((label_angry, label_disgusted, label_fearful, label_happy, label_sadness, label_surprised)) # 利用shuffle,轉置、隨機打亂 temp = np.array([image_list, label_list]) # 轉換成2維矩陣 temp = temp.transpose() # 轉置 # numpy.transpose(a, axes=None) 作用:將輸入的array轉置,並返回轉置後的array np.random.shuffle(temp) # 按行隨機打亂順序函式 # 將所有的img和lab轉換成list all_image_list = list(temp[:, 0]) # 取出第0列資料,即圖片路徑 all_label_list = list(temp[:, 1]) # 取出第1列資料,即圖片標籤 label_list = [int(i) for i in label_list] # 轉換成int資料型別 ''' # 將所得List分為兩部分,一部分用來訓練tra,一部分用來測試val ratio = 0.8 n_sample = len(all_label_list) n_val = int(math.ceil(n_sample * ratio)) # 測試樣本數, ratio是測試集的比例 n_train = n_sample - n_val # 訓練樣本數 tra_images = all_image_list[0:n_train] tra_labels = all_label_list[0:n_train] tra_labels = [int(float(i)) for i in tra_labels] # 轉換成int資料型別 val_images = all_image_list[n_train:-1] val_labels = all_label_list[n_train:-1] val_labels = [int(float(i)) for i in val_labels] # 轉換成int資料型別 return tra_images, tra_labels, val_images, val_labels ''' return image_list, label_list # 為了方便網路的訓練,輸入資料進行batch處理 # image_W, image_H, :影象高度和寬度 # batch_size:每個batch要放多少張圖片 # capacity:一個佇列最大多少 def get_batch(image, label, image_W, image_H, batch_size, capacity): # step1:將上面生成的List傳入get_batch() ,轉換型別,產生一個輸入佇列queue # tf.cast()用來做型別轉換 image = tf.cast(image, tf.string) # 可變長度的位元組陣列.每一個張量元素都是一個位元組陣列 label = tf.cast(label, tf.int32) # tf.train.slice_input_producer是一個tensor生成器 # 作用是按照設定,每次從一個tensor列表中按順序或者隨機抽取出一個tensor放入檔名佇列。 input_queue = tf.train.slice_input_producer([image, label]) label = input_queue[1] image_contents = tf.read_file(input_queue[0]) # tf.read_file()從佇列中讀取影象 # step2:將影象解碼,使用相同型別的影象 image = tf.image.decode_jpeg(image_contents, channels=3) # jpeg或者jpg格式都用decode_jpeg函式,其他格式可以去檢視官方文件 # step3:資料預處理,對影象進行旋轉、縮放、裁剪、歸一化等操作,讓計算出的模型更健壯。 image = tf.image.resize_image_with_crop_or_pad(image, image_W, image_H) # 對resize後的圖片進行標準化處理 # image = tf.image.per_image_standardization(image) # step4:生成batch # image_batch: 4D tensor [batch_size, width, height, 3], dtype = tf.float32 # label_batch: 1D tensor [batch_size], dtype = tf.int32 image_batch, label_batch = tf.train.batch([image, label], batch_size=batch_size, num_threads=16, capacity=capacity) # 重新排列label,行數為[batch_size] label_batch = tf.reshape(label_batch, [batch_size]) image_batch = tf.cast(image_batch, tf.uint8) # 顯示彩色影象 # image_batch = tf.cast(image_batch, tf.float32) # 顯示灰度圖 return image_batch, label_batch # 獲取兩個batch,兩個batch即為傳入神經網路的資料 def PreWork(): # 對預處理的資料進行視覺化,檢視預處理的效果 IMG_W = 256 IMG_H = 256 BATCH_SIZE = 5 CAPACITY = 64 train_dir = 'F:/Python/PycharmProjects/DeepLearning/CK+_part' # image_list, label_list, val_images, val_labels = get_file(train_dir) image_list, label_list = get_file(train_dir) image_batch, label_batch = get_batch(image_list, label_list, IMG_W, IMG_H, BATCH_SIZE, CAPACITY) lists = ('angry', 'disgusted', 'fearful', 'happy', 'sadness', 'surprised') with tf.Session() as sess: i = 0 coord = tf.train.Coordinator() # 建立一個執行緒協調器,用來管理之後在Session中啟動的所有執行緒 threads = tf.train.start_queue_runners(coord=coord) try: while not coord.should_stop() and i < 2: # 提取出兩個batch的圖片並可視化。 img, label = sess.run([image_batch, label_batch]) # 在會話中取出img和label # img = tf.cast(img, tf.uint8) ''' 1、range()返回的是range object,而np.arange()返回的是numpy.ndarray() range(start, end, step),返回一個list物件,起始值為start,終止值為end,但不含終止值,步長為step。只能建立int型list。 arange(start, end, step),與range()類似,但是返回一個array物件。需要引入import numpy as np,並且arange可以使用float型資料。 2、range()不支援步長為小數,np.arange()支援步長為小數 3、兩者都可用於迭代 range儘可用於迭代,而np.nrange作用遠不止於此,它是一個序列,可被當做向量使用。 ''' for j in np.arange(BATCH_SIZE): # np.arange()函式返回一個有終點和起點的固定步長的排列 print('label: %d' % label[j]) plt.imshow(img[j, :, :, :]) title = lists[int(label[j])] plt.title(title) plt.show() i += 1 except tf.errors.OutOfRangeError: print('done!') finally: coord.request_stop() coord.join(threads) if __name__ == '__main__': PreWork()

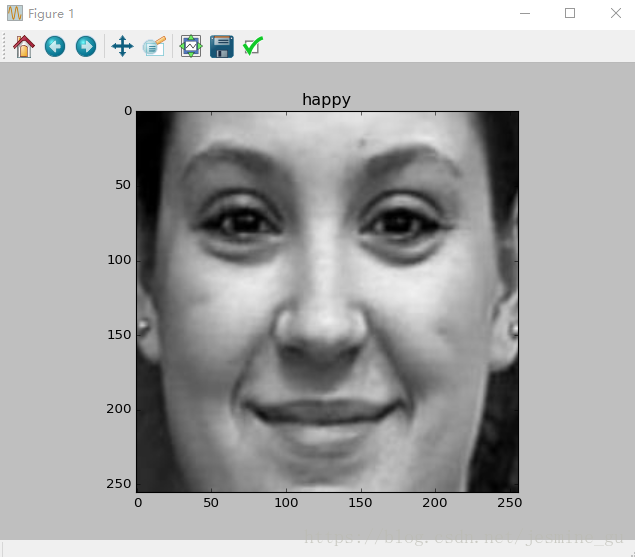

隨便挑著放了兩張效果圖
附言:我的程式碼一如既往有很多很多的註釋,不談標不標準,單純是記錄,方便自己理解
相關推薦
完整實現利用tensorflow訓練自己的圖片資料集
經過差不多一個禮拜的時間的學習,終於把完整的一個利用自己爬取的圖片做訓練資料集的卷積神經網路的實現(基於tensorflow) 簡單整理一下思路: 獲取資料集(上網爬取,或者直接找公開的圖片資料集) reshape圖片成相同大小(公開資料集一般都是相同sha
利用tensorflow訓練自己的圖片資料集——資料準備
昨天實現了一個簡單的CNN網路。用了MNIST資料集,雖然看來對這個資料集用的很多,但是真正這個資料集是怎麼在訓練的時候被呼叫的,以及怎麼把它換成自己的資料集都是一臉懵。 作者給的程式碼是python2.x版本的,我用的python3.5,改了一些錯誤。 import
利用tensorflow訓練自己的圖片資料(5)——測試訓練網路
一.說明 上一篇部落格中,我們已經將建立好的網路模型訓練好了,並將訓練的網路引數儲存在相應的檔案中;下面我們就開始測試網路,驗證網路的訓練效果;本次測試為隨機的單圖片測試,即隨機的從訓練集或測試集中讀取一張圖片,送入到神經網路中進行識別,列印識別率及識別的影象。 二. 程式
利用tensorflow訓練自己的圖片資料(3)——建立網路模型
一. 說明 在上一部落格——利用tensorflow訓練自己的圖片資料(2)中,我們已經獲得了神經網路的訓練輸入資料:image_batch,label_batch。接下就是建立神經網路模型,筆者的網路模型結構如下: 輸入資料:(batch_size,IMG_W,IMG_H
利用tensorflow訓練自己的圖片——2、網路搭建(AlexNet)
得到資料之後,接下來就是網路的搭建,我在這裡將模型單獨定義出來,方便後期的網路修正。 #!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script f
使用TFRecord進行圖片格式轉換以及搭建神經網路實驗全過程,使用Tensorflow訓練自己的資料集
最近一個大作業需要進行影象處理可是網上的資源太分散,於是想整合網上資源,形成一個系統: 主要包括 圖片預處理 圖片轉TFrecord格式 TFrecord格式轉圖片檢視 簡單神經網路搭建 TFrecord格式在神經網路中的讀取 batch方法提取資料
SSD Tensorflow訓練自己的資料集,遇到報錯absl.flags._exceptions.IllegalFlagValueError: flag --num_classes==: 求助
按照此部落格訓練到“五.訓練”這一步報錯。 連結:https://blog.csdn.net/Echo_Harrington/article/details/81131441 下面是bash 的 train.sh 檔案博主給的內容 D
使用tensorflow訓練自己的資料集(一)——製作資料集
使用tensorflow訓練自己的資料集—製作資料集 想記錄一下自己製作訓練集並訓練的過、希望踩過的坑能幫助後面入坑的人。 本次使用的訓練集的是kaggle中經典的貓狗大戰資料集(提取碼:ufz5)。因為本人筆記本配置很差還不是N卡所以把train的資料分成了訓練集和測試集並沒有使用
使用tensorflow訓練自己的資料集(四)——計算模型準確率
使用tensorflow訓練自己的資料集—定義反向傳播 上一篇使用tensorflow訓練自己的資料集(三)中製作已經介紹了定義反向傳播過程來訓練神經網路,訓練完神經網路後應對神經網路進行準確率的計算。 import time import forward import back
使用tensorflow訓練自己的資料集(一)
使用tensorflow訓練自己的資料集 想記錄一下自己製作訓練集並訓練的過、希望踩過的坑能幫助後面入坑的人。 本次使用的訓練集的是kaggle中經典的貓狗大戰資料集(提取碼:ufz5)。因為本人筆記本配置很差還不是N卡所以把train的資料分成了訓練集和測試集
使用tensorflow訓練自己的資料集(二)
使用tensorflow訓練自己的資料集—定義神經網路 上一篇使用tensorflow訓練自己的資料集(一)中製作已經介紹了製作自己的資料集、接下來就是定義向前傳播過程了也就是定義神經網路。本次使用了兩層卷積兩層最大池化兩層全連線神經網路最後加softmax層的
使用tensorflow訓練自己的資料集(三)——定義反向傳播過程
使用tensorflow訓練自己的資料集—定義反向傳播 上一篇使用tensorflow訓練自己的資料集(二)中製作已經介紹了定義神經網路、接下來就是定義反向傳播過程進行訓練神經網路了。反向傳播過程中使用了滑動平均類和學習率指數下降來優化神經網路。 ps.沒有GP
Tensorflow 訓練自己的資料集(二)(TFRecord)
Tensorflow 提供了一種統一的格式來儲存資料,這個格式就是TFRecord,上一篇部落格中所提到的方法當資料的來源更復雜,每個樣例中的資訊更豐富的時候就很難有效的記錄輸入資料中的資訊了,於是Tensorflow提供了TFRecord來統一儲存資料,接下來
如何利用caffe訓練自己資料集
這篇博文主要參考了另一位博主https://blog.csdn.net/hellohaibo,在此向他表示感謝 首先,博主今天的caffe崩了,毫無徵兆的崩了,具體表現為博主想做一個更大的資料集,但是在生成lmbd檔案時永遠生成的是一個沒有名字的資料夾,可是博主已經在指定的example目錄裡寫了
目標檢測SSD+Tensorflow 訓練自己的資料集
對原文的幾點解釋這說明: 1.程式碼地址:https://github.com/balancap/SSD-Tensorflow,下載該程式碼到本地 注:該程式碼是github上tensorflow版的SSD star 最多的程式碼. 2.解壓ssd_300_vg
詳解tensorflow訓練自己的資料集實現CNN影象分類
利用卷積神經網路訓練影象資料分為以下幾個步驟1.讀取圖片檔案2.產生用於訓練的批次3.定義訓練的模型(包括初始化引數,卷積、池化層等引數、網路)4.訓練1 讀取圖片檔案def get_files(filename): class_train = [] label_trai
Tensorflow 訓練自己的資料集(一)(資料直接匯入到記憶體)
製作自己的訓練集 下圖是我們資料的存放格式,在data目錄下有驗證集與測試集分別對應iris_test, iris_train 為了向偉大的MNIST致敬,我們採用的資料名稱格式和MNIST類似 classification_index.jpg
Yolov3訓練自己資料集+資料分析
訓練自己到資料集已經在上一篇文中說明過了,這一篇著重記錄一下資料分析過程 資料分析 1. mAP值計算 1)訓練完成後,執行darknet官方程式碼中到 detector valid 命令,生成對測試集到檢測結果,命令如下: ./darknet detector va
TensorFlow——訓練自己的資料(五)模型評估
模型的評估主要有幾個指標:平均準確率、識別的時間、loss下降變化等。Tensorflow提供了一個log視覺化的工具tensroboard。要看到log就必須在訓練時用summary去記錄想
TensorFlow——訓練自己的資料(三)模型訓練
檔案training.py 匯入檔案 import os import numpy as np import tensorflow as tf import input_data