
mongodb叢集環境搭建Replica Set
1.引子
mongodb的叢集搭建方式主要有三種,主從模式,Replica set模式,sharding模式, 三種模式各有優劣,適用於不同的場合,屬Replica set應用最為廣泛,主從模式現在用的較少,sharding模式最為完備,但配置維護較為複雜。本節我們來看下Replica Set模式的搭建方法。2.Replica Set模式
Replica Set模式主要包括3個部分,主節點,備節點,仲裁節點. 主節點相當於主庫,所有插入,查詢,修改操作都可以在主節點執行。 備節點相當於從庫,用來做備份,也可以承擔查詢的功能,減輕主節點的壓力,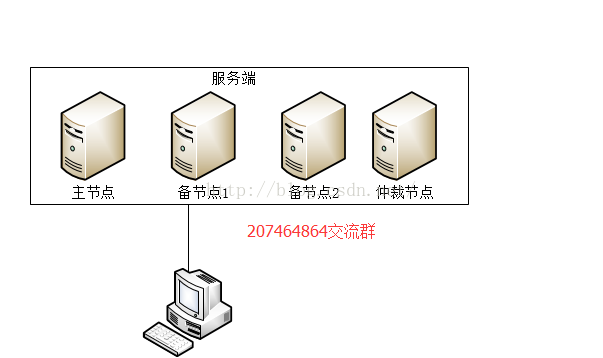 接下來我們看看Replica
Set環境的搭建的搭建方法
接下來我們看看Replica
Set環境的搭建的搭建方法
3.環境搭建
首先我們準備三臺機器,我這裡的機器的作業系統是CentOS 32位,ip地址為192.168.159.135, 192.168.159.136,192.168.159.137, 這裡以192.168.159.135為主節點,以192.168.159.136為從節點,192.168.159.137為仲裁節點 在三臺機器上首先分別安裝mongodb,我這裡安裝在usr/local目錄下,然後在每臺機器的mongodb的bin資料夾下上建立mongodb的配置檔案mongodb.conf的內容如下storageEngine=mmapv1 dbpath=/usr/local/mongodb1/db logpath=/usr/local/mongodb1/logs/mongodb.log pidfilepath=/usr/local/mongodb1/mongodb.pid #keyFile=/opt/mongodb-linux-x86_64-3.2.9/bin/mongodb_keyfile directoryperdb=true logappend=true replSet=rs1 bind_ip=192.168.159.135 port=27017 oplogSize=100 fork=true noprealloc=true auth=false
storageEngine=mmapv1
dbpath=/usr/local/mongodb1/db
logpath=/usr/local/mongodb1/logs/mongodb.log
pidfilepath=/usr/local/mongodb1/mongodb.pid
#keyFile=/opt/mongodb-linux-x86_64-3.2.9/bin/mongodb_keyfile
directoryperdb=true
logappend=true
replSet=rs1
bind_ip=192.168.159.136
port=27017
oplogSize=100
fork=true
noprealloc=true
auth=falsestorageEngine=mmapv1
dbpath=/usr/local/mongodb1/db
logpath=/usr/local/mongodb1/logs/mongodb.log
pidfilepath=/usr/local/mongodb1/mongodb.pid
#keyFile=/opt/mongodb-linux-x86_64-3.2.9/bin/mongodb_keyfile
directoryperdb=true
logappend=true
replSet=rs1
bind_ip=192.168.159.137
port=27017
oplogSize=100
fork=true
noprealloc=true
auth=false ./mongod -f mongodb.conf./mongo 192.168.159.135
use admincfg={ _id:"rs1", members:[ {_id:0,host:'192.168.159.135:27017',priority:2}, {_id:1,host:'192.168.159.136:27017',priority:1}, {_id:2,host:'192.168.159.137:27017',arbiterOnly:true}] };
rs.initiate(cfg) arbiterOnly:true表示仲裁節點 可以執行rs.status()來檢查執行配置結果資訊,如果執行成功,會出現如下資訊
{
"set" : "rs1",
"date" : ISODate("2016-10-24T06:08:10.946Z"),
"myState" : 1,
"term" : NumberLong(1),
"heartbeatIntervalMillis" : NumberLong(2000),
"members" : [
{
"_id" : 0,
"name" : "192.168.159.135:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 335,
"optime" : {
"ts" : Timestamp(1477289289, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2016-10-24T06:08:09Z"),
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(1477289288, 1),
"electionDate" : ISODate("2016-10-24T06:08:08Z"),
"configVersion" : 1,
"self" : true
},
{
"_id" : 1,
"name" : "192.168.159.136:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 13,
"optime" : {
"ts" : Timestamp(1477289289, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2016-10-24T06:08:09Z"),
"lastHeartbeat" : ISODate("2016-10-24T06:08:10.897Z"),
"lastHeartbeatRecv" : ISODate("2016-10-24T06:08:10.851Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "192.168.159.135:27017",
"configVersion" : 1
},
{
"_id" : 2,
"name" : "192.168.159.137:27017",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 13,
"lastHeartbeat" : ISODate("2016-10-24T06:08:10.896Z"),
"lastHeartbeatRecv" : ISODate("2016-10-24T06:08:09.846Z"),
"pingMs" : NumberLong(1),
"configVersion" : 1
}
],
"ok" : 1
}
"stateStr" : "PRIMARY"表示主節點, "stateStr" : "SECONDARY"表示從節點, "stateStr" : "ARBITER",表示仲裁節點
4.客戶端連線
客戶端連線主節點,插入資料,插入後,可以看到資料在備份節點上也進行了同步。./mongo 192.168.159.135
use user db.users.insert({Name: "zhang",Age: 50}) 也可以使用客戶端連線工具進行操作robomongo 備註 1. 關閉mongodb命令 [[email protected] bin]# ps -ef | grep mongod
root 2966 1 0 19:40 ? 00:01:30 ./mongod -f mongodb.conf
root 5741 2547 0 22:58 pts/1 00:00:00 grep mongod
[[email protected] bin]# kill -9 2966 note: noprealloc may hurt performance in many applications
2016-10-23T19:41:26.822-0700 I CONTROL [main]
2016-10-23T19:41:26.822-0700 W CONTROL [main] 32-bit servers don't have journaling enabled by default. Please use --journal if you want
durability.
2016-10-23T19:41:26.822-0700 I CONTROL [main]
about to fork child process, waiting until server is ready for connections.
forked process: 6756
ERROR: child process failed, exited with error number 100
You have new mail in /var/spool/mail/root
相關推薦
mongodb叢集環境搭建Replica Set
1.引子 mongodb的叢集搭建方式主要有三種,主從模式,Replica set模式,sharding模式, 三種模式各有優劣,適用於不同的場合,屬Replica set應用最為廣泛,主從模式現在用的較少,sharding模式最為完備,但配置維護較為複
搭建高可用MongoDB集群(Replica set)
mongodb mongodb副本集 replica set mongodb集群 MongoDB基礎可參考http://blog.51cto.com/kaliarch/2044423一、概述1.1 MongoDB副本集通俗來講,mongodb的副本集相當於具有自動故障恢復的主從集群,主從集群和
MongoDB分散式叢集環境搭建
第一節分片的概念 分片(sharding)是指根據片鍵,將資料進行拆分,使其落在不同的機器上的過程。如此一來,不需要功能,配置等強大的機器,也能儲存大資料量,處理更高的負載。 第二節分片的原理和思想 MongoDB分片的基本思想就是將集合切分成小塊。這些塊分散到
MongoDB學習--環境搭建記錄
文件 .com sea 密碼 chkconfig 密鑰 win -- 啟動 Mongo安裝教程,參考英文官網 基本命令, 索引的引用,索引基於地理位置的數據, win10 64位 系統中安裝虛擬機 win10 系統中安裝虛擬機VMwareWorkstation11 並安裝
Redis單機和叢集環境搭建
一、安裝單機版redis 1、可以自己去官網下載,當然也可以用課程提供的壓縮包 # yum install gcc # wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gz # tar -xzvf tcl8.6.1-s
Hyperledger Fabric v1.1 單機多節點叢集環境搭建
Fabric v1.1 1.環境安裝 1).安裝go 1.9.x 下載地址 http://golang.org/dl/ 配置環境 #go的安裝根目錄 export GOROOT=/usr/local/go #go的工作路徑根目錄 export GOPAT
zookeeper-3.4.10分散式叢集環境搭建
初始叢集狀態 機器名 IP 作用 linux系統 master 192.168.218.133 CentOS-6.9-x86_64-bin-D
centos7中kafka叢集環境搭建部署
一、前期準備 1、下載kafka安裝包 官方下載地址:http://kafka.apache.org/downloads.html kafka_2.11-2.0.0.tgz 2、準備好要安裝的叢集環境的目標機器(3檯安裝centos7系統) 3、將下載好的壓縮包
Eureka高可用叢集環境搭建
註冊中心叢集 在微服務中,註冊中心非常核心,可以實現服務治理,如果一旦註冊出現故障的時候,可能會導致整個微服務無法訪問,在這時候就需要對註冊中心實現高可用叢集模式。 Eureka叢集相當簡單:相互註冊 Eureka高可用實際上將自己作為服務向其他服務註冊中心註冊自己,這樣就可以形成一組相互註冊的服務註冊
kafaka叢集環境搭建
伺服器環境準備 使用vm虛擬三個linux主機:192.168.128.139,192.168.128.140,192.168.128.141 Zookeeper叢集環境搭建 1.每臺伺服器節點上安裝jdk1.8環境 使用java version命令測試 2
Windows 下 Redis 叢集環境搭建
Redis 可以支援單機多例項方式的部署,這樣為叢集環境的搭建提供了方便。 Windows下搭建Redis叢集需要的環境準備包括,Redis,Ruby語言執行環境,Redis的Ruby驅動redis-xxxx.gem、建立Redis叢集的工具redis-trib.rb。 1. Redis Wind
Elasticsearch叢集環境搭建
單節點環境搭建參考:https://blog.csdn.net/qq_38270106/article/details/84309702 建議先搭建好單伺服器,再clone兩個伺服器 環境準備:三臺虛擬機器 node-1----------192.168.128.156
Spark叢集環境搭建
本文作者:賀聖軍,叩丁狼高階講師。原創文章,轉載請註明出處。 現在在大資料的生態圈的離線的處理主要使用的是MapReduce和Hive技術,但是對於實時處理分析,越來越多的企業使用的Spark作為企業的記憶體處理計算框架,相對於MapReduce,Spark主要有以下一些特
Spark叢集環境搭建中所遇到的問題
1. 安裝好JDK後,檢視java版本出現以下提示: 解決方法:在終端輸入以下兩條命令: (1) sudo update-alternatives --install /usr/bin/javac javac /home/fhb/spark
大資料作業(一)基於docker的hadoop叢集環境搭建
主要是根據廈門大學資料庫實驗室的教程(http://dblab.xmu.edu.cn/blog/1233/)在Ubuntu16.04環境下進行搭建。 一、安裝docker(Docker CE) 根據docker官網教程(https://docs.docker.
Hadoop叢集環境搭建(雲伺服器,虛擬機器都適用)
為了配置方便,為每臺電腦配置一個主機名: vim /etc/hostname 各個節點中,主節點寫入:master , 其他從節點寫入:slavexx 如果這樣修改不能生效,則繼續如下操作 vim /etc/cloud/cloud.cfg 做preserve_hostname: true 修改 reb
hadoop叢集環境搭建之偽分散式叢集環境搭建
搭建叢集的模式有三種 1.偽分散式:在一臺伺服器上,啟動多個執行緒分別代表多個角色(因為角色在叢集中使用程序表現的) 2.完全分散式:在多臺伺服器上,每臺伺服器啟動不同角色的程序,多臺伺服器構成叢集 node01:NameNode node02:
Hadoop最完整分散式叢集環境搭建
分散式環境搭建之環境介紹 之前我們已經介紹瞭如何在單機上搭建偽分散式的Hadoop環境,而在實際情況中,肯定都是多機器多節點的分散式叢集環境,所以本文將簡單介紹一下如何在多臺機器上搭建Hadoop的分散式環境。 我這裡準備了三臺機器,IP地址如下: 192.16
zookeeper叢集環境搭建(純zookeeper)
1.首先在三臺機子上放上zookeeper的解壓包,解壓。 然後的話zookeeper是依賴於jdk的,那麼也應該安裝jdk,這裡不詳細說明了。 mv zookeeper-3.4.5 zookeeper 修改節點為zookeeper
mongodb叢集簡介搭建方式 使用mlaunch和m
使用mlaunch和m快速搭建MongoDB測試叢集 前言 不知道大家在使用MongoDB的時候有沒有遇到突然想要一個叢集但是手邊又沒有的時候?特別是我已經升級到4.0了,突然想要一個3.2的叢集怎麼辦?然後去下載,改配置檔案,啟動,修改複製集,新增分片,一番折騰弄好