
ATS中的RAM快取簡介
RAM快取
新RAM快取演算法(CLFUS)
新的RAM快取使用的創意來自許多快取替換策略和演算法,包括LRU,LFU,CLOCK,GDFS及2Q,它被命名為時鐘週期內最小頻繁使用大小演算法CLFUS(Clocked Least Frequently Used by Size)。它避開了任何專利演算法,具有如下特性:
- 均衡最近性(Recentness),頻率(Frequency)和大小(Size)以最大化
命中率(hit byte,不是位元組命中率byte hit rate) 耐掃描(scan resistant),命中率提取可靠,即使工作集並不適應RAM Cache- 支援
3級壓縮率: fastlz, gzip(libz庫)和xz(liblzma庫),壓縮工作可以移至另外一個執行緒處理 非常低的CPU開銷,僅略高於基礎的LRU,沒有使用O(lgn)堆,而是使用O(1)成本的概率替換策略(probabilistic replacement policy)相對低的記憶體開銷,記憶體中的每個物件平均大約200位元組
強調命中率而不是位元組命中率的合理性,是因為從次級儲存裝置(硬碟)讀取更多位元組的開銷(overhead)較之一個請求的成本(cost)更低。
RAM快取由最前面的兩個LRU/CLOCK物件雜湊連結串列和一個seen雜湊表組成。第一個快取連結串列包含記憶體中的物件,但是第二個連結串列包含了近來放入快取中或者打算放入快取中的物件的歷史資訊(history of objects),seen雜湊表用來使演算法耐掃描。
下表中的元素(對應原始碼中的RamCacheCLFUSEntry)記錄了下面的資訊:
- key
16位元組的唯一物件識別符號 - auxkeys
相當於8位元組的版本號(系統中分割槽的塊),當物件的版本號改變時,舊元素將從快取中刪除掉 - hits
當前時鐘週期內的命中數 - size
快取中物件的大小,包括填充 - len
物件的實際長度,因為壓縮和填充的原因,和size有區別。 - compressed_len
物件壓縮後的長度 - compressed
壓縮型別,可能的值是fastlz, libz和liblzma,不可壓縮時值為none - uncompressible
true表示物件內容可以壓縮,false表示不可壓縮 - copy
物件是否應該複製進來或複製出去(比如,HTTP HDR) - LRU link
所在的LRU連結串列,有兩個(cached list和history list) - HASH link
所在bucket的雙鏈表 - IOBufferData
資料快取(data buffer)的智慧指標
快取介面是Get和Put操作,Get操作檢查一個物件是否在快取中,在將要讀取時呼叫,Put操作決定是否將給定的物件放入快取中,它在從磁碟中讀取物件後呼叫。
RamCacheCLFUS::get虛擬碼演算法分析:
if X is in cached list then
move X to the tail of cached list, and return the data in X
else if X is in history list then
move X to the tail of history list
"cache miss"
else
"cache miss"
end if
RamCacheCLFUS::put虛擬碼演算法分析:
if X is in cached list then
move X to the tail of cached list, and update its data
else if X is in history list then
if cached list has room to place X then
insert X to the tail of cached list, and update its data
else
create list V
do
pop one page Y from cached list
//simulate the aging algorithm, for avoiding cache pollution
pop one page Z from history list
if HIT_VALUE(Z) is not greater than 1 then
delete Z
else
let the HIT_VALUE(Z) with 1, and reinserted Z to the tail of history list
end if
//end
if CACHE_VALUE(X) is greater than CACHE_VALUE(Y) then
push it to V
else
insert X to the tail of history list and update its data, return
end if
util cached list has enough room for placing X
end do
for(Z in V)
if cached list has room for both Z and X, then
reinsert Z to the tail of cached list
insert X to the tail of cached list, and update its data
end if
end for
end if
else // X is neither in history list nor in cached list
//judge X is or not first accessed by seen hash
if X is first accessed and history list has no room for it, then
save the record of X in seen hash
else
insert X to the tail of history list
end if
end ifSeen Hash
ATS冷啟動後,Cached連結串列和History連結串列填滿,將啟用Seen連結串列。該連結串列的作用是快取耐掃描,這意味著,經過對快取中只見到一次的物件們做一長串的Get和Put操作,快取狀態一定不能受到影響。這是最本質的,如果沒有這點保證,不僅快取會受到汙染,而且會丟失它所關注的物件相關的重要資訊。所以,Cache連結串列和History連結串列不會受到第一次見到的物件上的Put操作和Get操作的影響是非常關鍵的。Seen Hash維護著一個16位元雜湊標籤(hash tags)的集合,未命中物件快取(Cache連結串列和History連結串列中的)的請求,以及不匹配雜湊標籤的請求,導致雜湊標籤被更新,否則會被忽略。Seen Hash的大小近似快取中的物件數,為了匹配用Cached連結串列和History連結串列的CLOCK率傳給它的個數。
Cached List
Cached連結串列含有實際在記憶體中的物件,基本操作就是LRU,新物件插入FIFO佇列中,命中導致物件被重新插入連結串列尾部。當要考慮插入一個物件時,會有一個有趣的bit位,首先檢查物件雜湊去看物件是否在Cached連結串列或者History連結串列中。命中意味著更新hit域並重新插入物件到連結串列尾部。History命中導致hit域被更新,然後比較物件是否儲存在記憶體中。比較基於Cached連結串列中的最近最少使用元素,並基於一個加權頻率:
CACHE_VALUE = hits / (size + overhead)
該公式類似GDFS演算法,用於計算物件的快取值,這裡hits是請求物件的命中率,size是該物件的大小,overhead是一個加權值,在程式碼中設定為256。該公式從直觀上比較易於理解,那些訪問次數多的小物件將會更易於進入RAM中,這比較符合事實。
新物件必須有足夠的位元組值得當前快取的物件去覆蓋它。每次,當一個物件被認為可替換時,CLOCK就向前移動。假如History物件的值更大,就將它插入Cached連結串列,被替換的物件從記憶體中移除,並插入到History連結串列中。視作替換(至少一個)但還沒有替換的物件,它們的hits域設為0,被重新插入Cached連結串列中,這就是Cached連結串列上的CLOCK操作。
History List
每個CLOCK操作時,History連結串列中的最少最近使用的元素被取出,假如hits域不超過1(History連結串列和Cached連結串列中至少命中一次)將被刪除。否則,hits域設為0,被重新放入History連結串列中。
壓縮和解壓
壓縮被後臺操作執行(當前稱作Put操作的一部分),後臺操作維護了一個指向Cached連結串列的指標,並向頭部正在壓縮的元素前進。在Get操作過程中,解壓根據要求進行。當物件被標記為copy時,壓縮版本將被再次插入LRU中,因為我們需要做一次拷貝,沒有標記為copy的那些物件被插入未壓縮LRU中,希望它們能以未壓縮形式重用。有一個編譯時間選項,或許是我們想改變的東西。
下面是三種壓縮演算法和級別的對比(在Intel i7 920系列CPU上使用單執行緒測試)
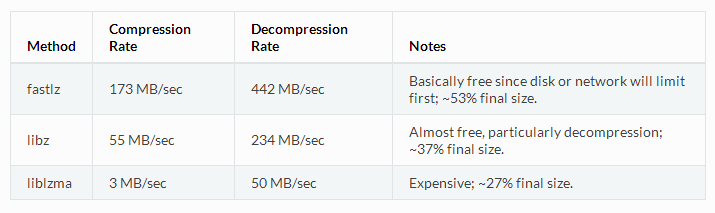
這些都是粗略數字,你的測試結果可能相差很大。比如說,JPEG並不會用上述任何一種演算法壓縮(或者至少只會在個別級別做這種測試,壓縮和解壓成本完全沒有說服力),對其它許多嵌入某種壓縮形式的媒體和二進位制檔案型別也是如此。RAM快取探測不到具體的壓縮級別,假如壓縮後的檔案大小不能達到原來大小的90%以下,RAM快取就認為該檔案是不可壓縮的,並將這個值快取下來,RAM快取不會企圖再去壓縮它(至少在history中的這段時間內)。