
Python應用(一) 識別網站驗證碼以及識別演算法
00 識別涉及技術
驗證碼識別涉及很多方面的內容。入手難度大,但是入手後,可拓展性又非常廣泛,可玩性極強,成就感也很足。
驗證碼影象處理
驗證碼影象識別技術主要是操作圖片內的畫素點,通過對圖片的畫素點進行一系列的操作,最後輸出驗證碼影象內的每個字元的文字矩陣。
1.讀取圖片
2.圖片降噪
3.圖片切割
4.影象文字輸出
驗證字元識別
驗證碼內的字元識別主要以機器學習的分類演算法來完成,目前我所利用的字元識別的演算法為KNN(K鄰近演算法)和SVM (支援向量機演算法),後面我 會對這兩個演算法的適用場景進行詳細描述。
1.獲取字元矩陣
2.矩陣進入分類演算法
3.輸出結果
涉及的Python庫
這次研究主要使用了以下這三個庫
1.numpy(數學處理庫)
2.Image(影象處理庫)
3.ImageEnhance(影象處理庫)
驗證碼識別技術難點
驗證碼識別由兩部分組成,分別是驗證碼圖片處理和驗證碼字元學習。
在編碼過程中,我認為難度最大的部分是識別演算法的學習和使用。
在寫文件的時候,我認為難度最大的部分是影象處理部分,影象處理部分需要對抗各種干擾因素,對抗不同型別的驗證碼需要不同的演算法支援,因此影象處理程式需要對各種驗證碼具體問題具體分析,不能抱有大而全的思想,務必注重細節處理。
01 學習與識別
驗證碼識別的過程分為學習過程與識別過程
學習
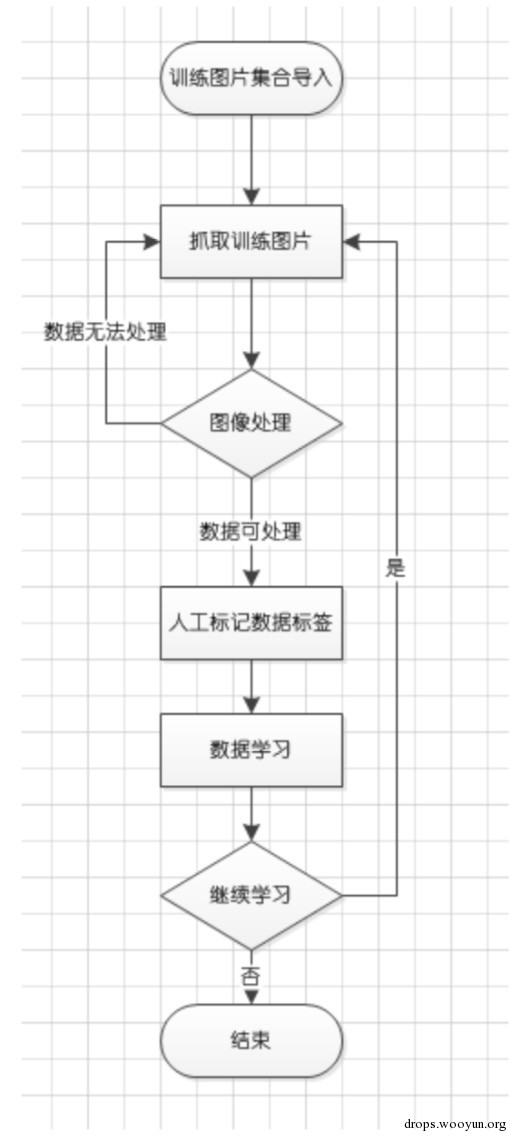
識別
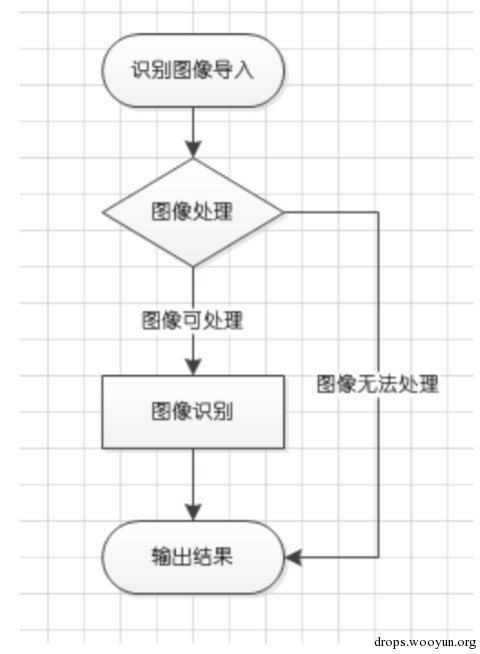
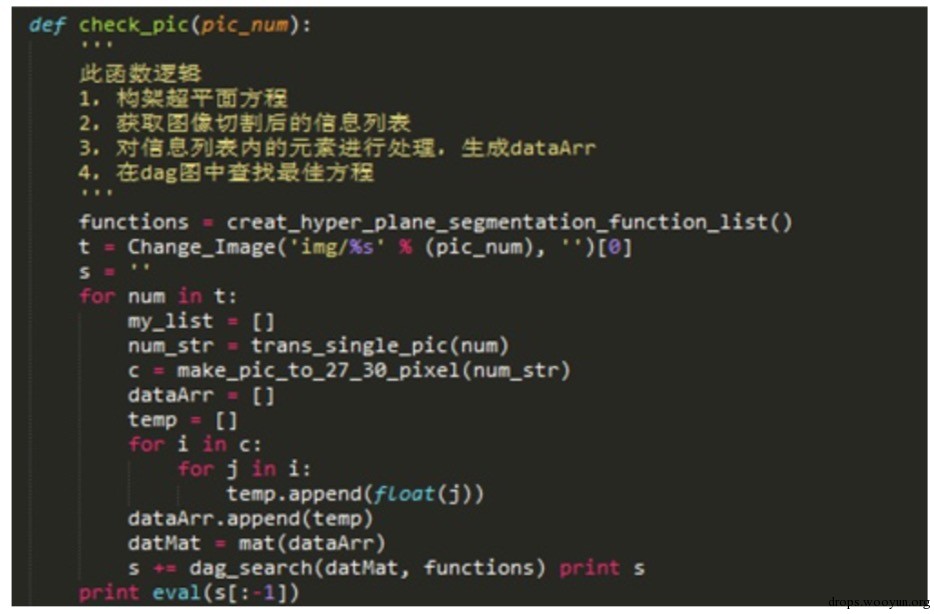
上圖程式碼運用的是SVM的識別過程
02 影象處理
驗證碼影象處理腦圖
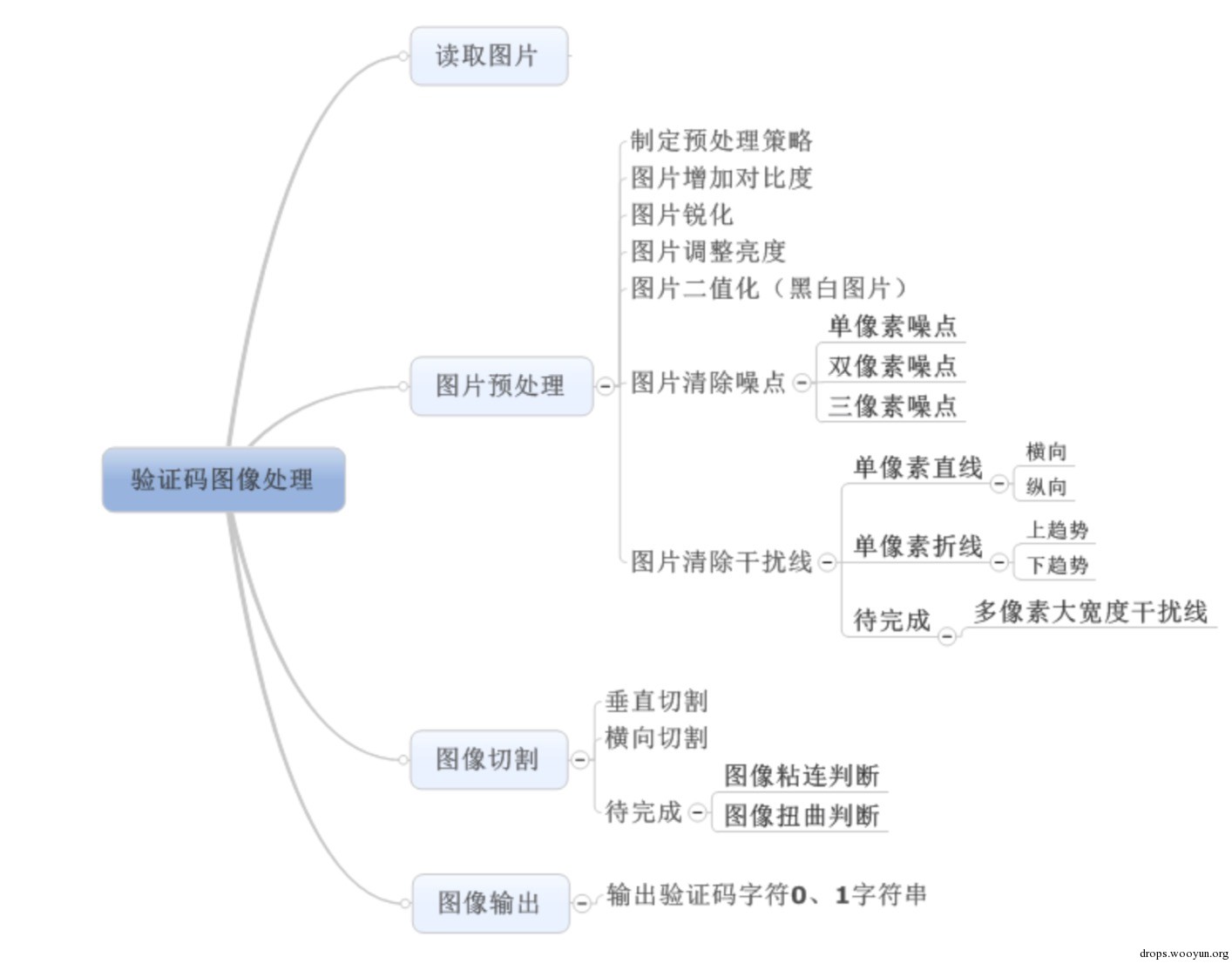
如上圖所示,驗證碼影象處理模組是一個結構規整、內部分支複雜的模組,整個驗證碼識別準確率全靠這個模組,可謂是整個驗證碼識別的根本。如 上文所說,影象處理模組玩的是圖片內的每一個畫素百度百科:畫素,因此這個模組好上手。

上面這兩句便可以開啟一個影象物件,im物件內建許多方法有興趣可以檢視Image庫原始碼或者參考Python Imaging Library Handbook 圖片增加對比度、銳化、調整亮度、二值化,這四塊是比較規整的模組,處理呼叫庫函式即可。下面主要說說圖片降噪和清楚單畫素干擾線。
圖片清除噪點
圖片降噪的原理是利用9宮格內資訊點(資訊畫素,一般經過預處理的資訊畫素為黑色)。

上圖黑色部分為(x,y),單畫素噪點處理時分別驗證周圍的八個點是否為白色,如果為白色即可判斷(x,y)為噪點。同理雙畫素噪點需要考慮兩個像 素的排列是橫向還是縱向或者是斜向,之後判斷其周圍10個畫素是否均為白色畫素即可。同理三畫素噪點也是這樣,我嘗試的情況三畫素噪點不包括 橫向排列和縱向排列。
圖片清除干擾線
對於單畫素的干擾線目前可以解決,但是大寬度干擾線則會產生判斷上的誤差,目前不好解決。

上圖的干擾線為單畫素,因此通過演算法即可解決。

干擾線處理後的圖片如上圖所示。
圖片切割
對於去噪後的圖片,我們需要對圖片進行切割,切割的目的是為了提取資訊,方便把圖片中的數字轉化為01形式的文字。 我所採用的切割方式是投影法.
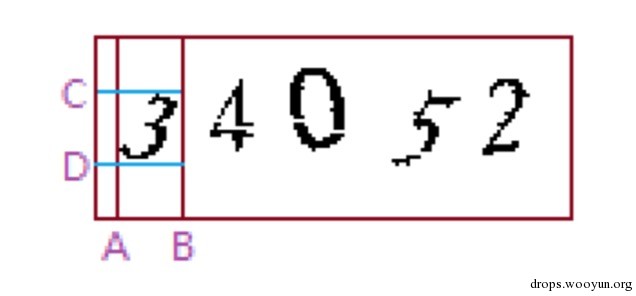
如上圖所示,對於切割數字3,首先需要找到垂線A和B,判斷步驟是:縱向從左向右掃描圖片,找到第一條含有資訊點的直線記為A,繼續向右掃描, 當從A開始,找到第一條無資訊點的直線記為B,從投影的角度來看,A與B之間X軸上的投影的資訊值均大於0,切割A與B之間的影象後,以新影象為 基礎,找出C與D,至此便可切割出數字3。
圖片切割目前可以僅可對非粘連字元進行切割,對於粘連字元,我的程式並沒能很好的處理。
資訊輸出
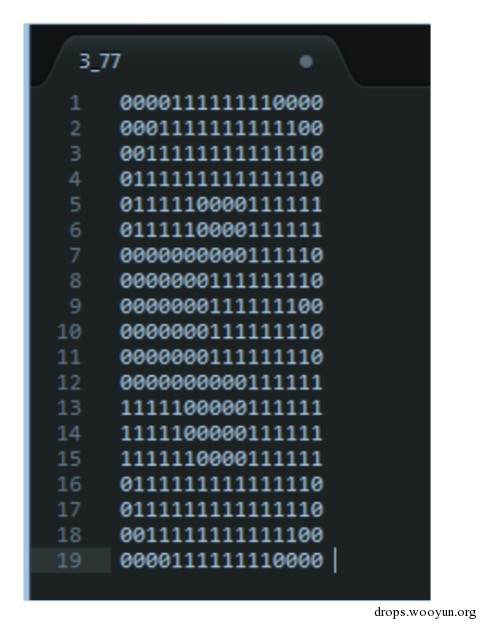
當獲取了切割好的圖片,由於圖片只有黑色與白色,因此遍歷每一個畫素點,根據畫素點的顏色來進行0,1輸出,一般認為黑色畫素輸出1,白色畫素 輸出0。
03 識別演算法概述
字元識別演算法整體流程很好理解,舉個例子,字元畫素文字A進入識別演算法,通過對演算法的結果進行判斷,便可以完成識別過程。我實踐了兩種識別算 法,第一種是KNN演算法,第二種是SVM演算法,下面我將以個人的角度來闡述下這兩種演算法的原理以及適用場景,個人水平有限,演算法細節可以參考我 之後給出的連結。
KNN(K鄰近演算法)
KNN演算法是一種簡單的演算法,KNN演算法基本思想是把資料轉化為點,通過計算兩點之間的距離來進行判斷。 在n維度下,兩點間距離可以表示為 S = math.sqrt((x1-y1)^2+(x2-y2)^2+.+(xn-yn)^2)。
SVM(支援向量機)
SVM演算法相比較KNN演算法來說,原理上要複雜複雜的多,SVM演算法基本思想是把資料轉化為點,通過把點對映到n維空間上,通過n-1維的超平面 切割,找到最佳切割超平面,通過判斷點在超平面的哪一邊,來判斷點屬於哪一類字元。
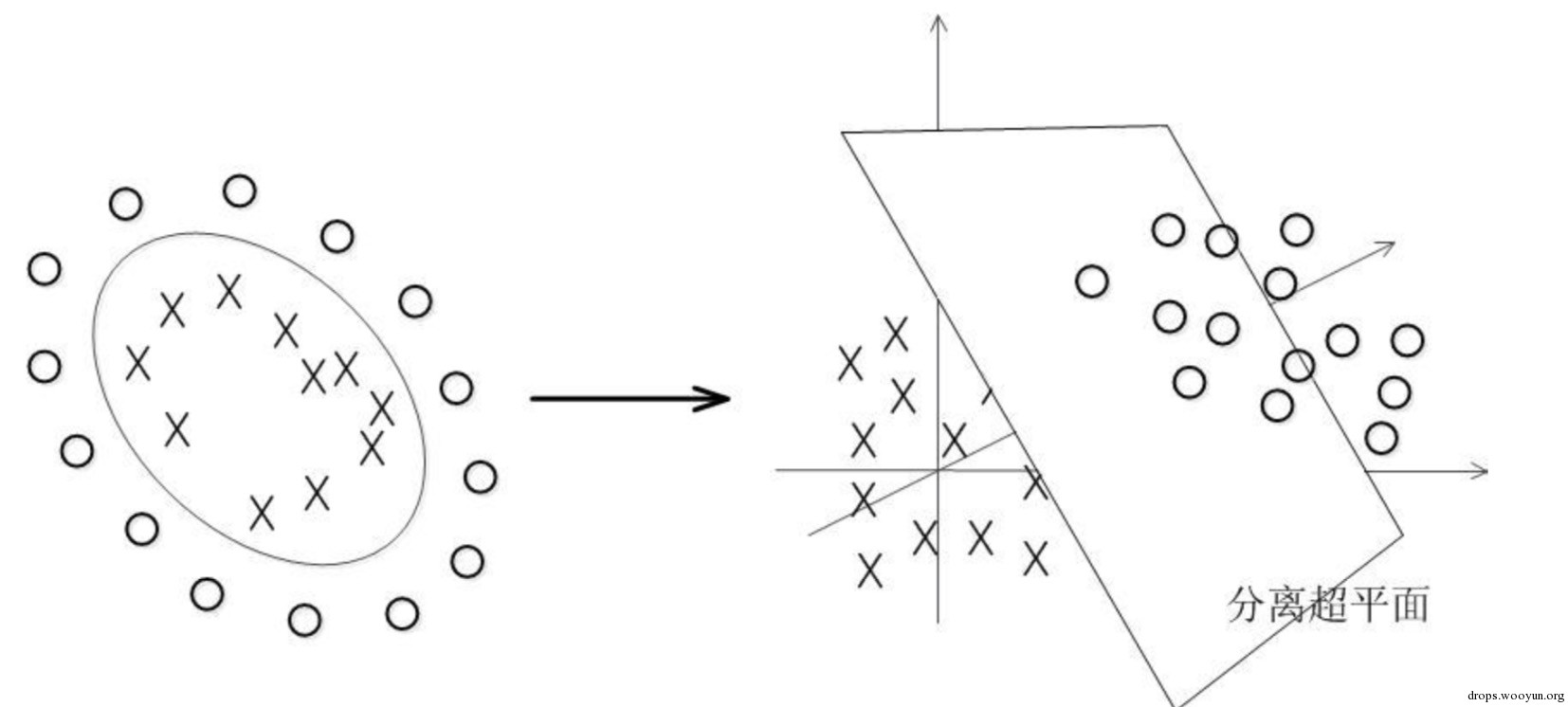
但是SVM演算法的特點只能在兩類中間比較,因此把字元識別運用到該演算法上,還需要在比較過程中加以一個遍歷演算法,遍歷演算法可以減少大量無效計 算,遍歷的場景是一個有向無環圖。
演算法細節文件連結
jerrylead 的blog : Machine Learning
支援向量機通俗導論(理解SVM的三層境界)
0x04 識別演算法適用場景
KNN與SVM的適用場景存在一定區別。
KNN演算法在執行過程上來說,並不存在學習過程,只是遍歷已知分類進行距離上的判斷,根據待測資料與已知分類進行比較,找出與待測距離最近的n個數據來進行匹配,因此當已分類的樣本越來越多,KNN演算法的運算時間會越來越長。
SVM演算法在執行過程中,是存在學習的過程的,通過對已知分類標籤進行兩兩組合,找出每個組合的切割方程。待測資料只需要一個一個計算切割方程,根據切割方程的返回值來判斷下一個執行的是哪個方程即可。0-9數字的判斷,只需要執行9次方程計算即可。SVM多類分類方法
因此如果大規模識別驗證碼,我建議適用SVM作為識別演算法。
04 實踐細節注意事項
這部分內容是我所遇到的問題。
規則化影象
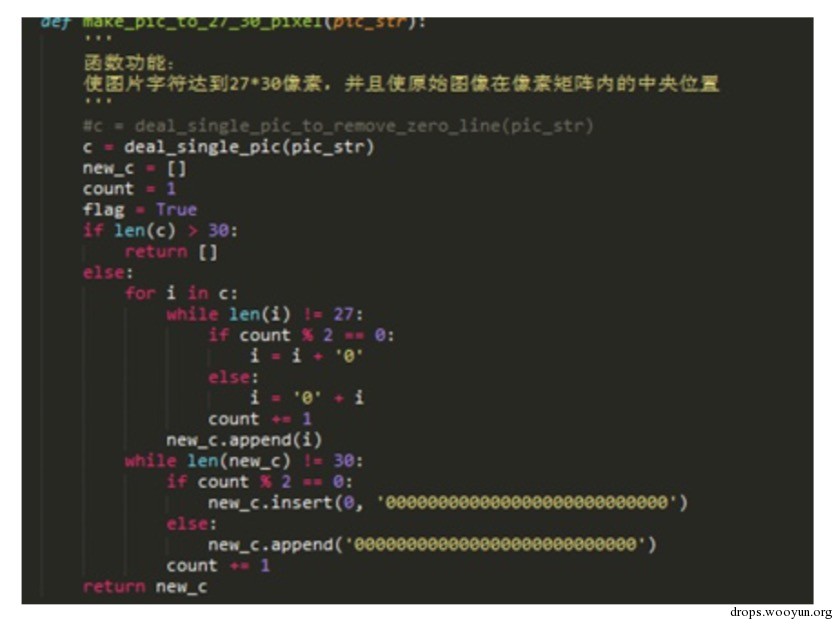
當切割的驗證碼以數字呈現在文本里,他們的畫素是各不相同的,需要把這些標準化,我選擇標準化在27*30畫素是一個經驗值。此外,還需要把新圖 像放置在標準化畫素的正中央。
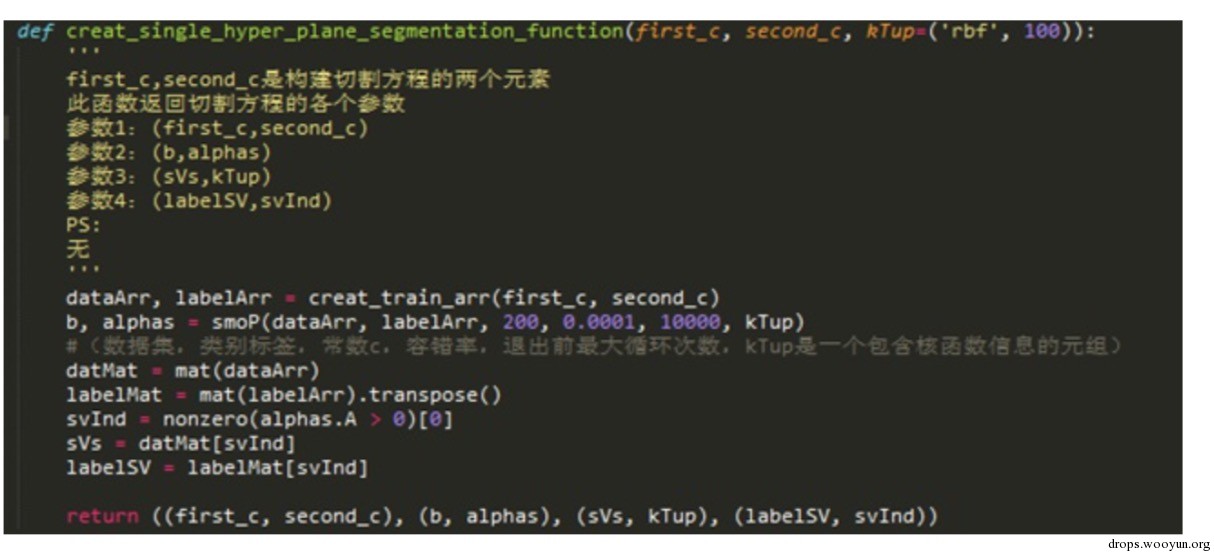
使用SVM構建超平面方程
SVM演算法的重點是尋找切割方程,首先需要把待判斷的兩種元素存入到dataArr和labelArr中,通smoP方程尋找b和alphas。
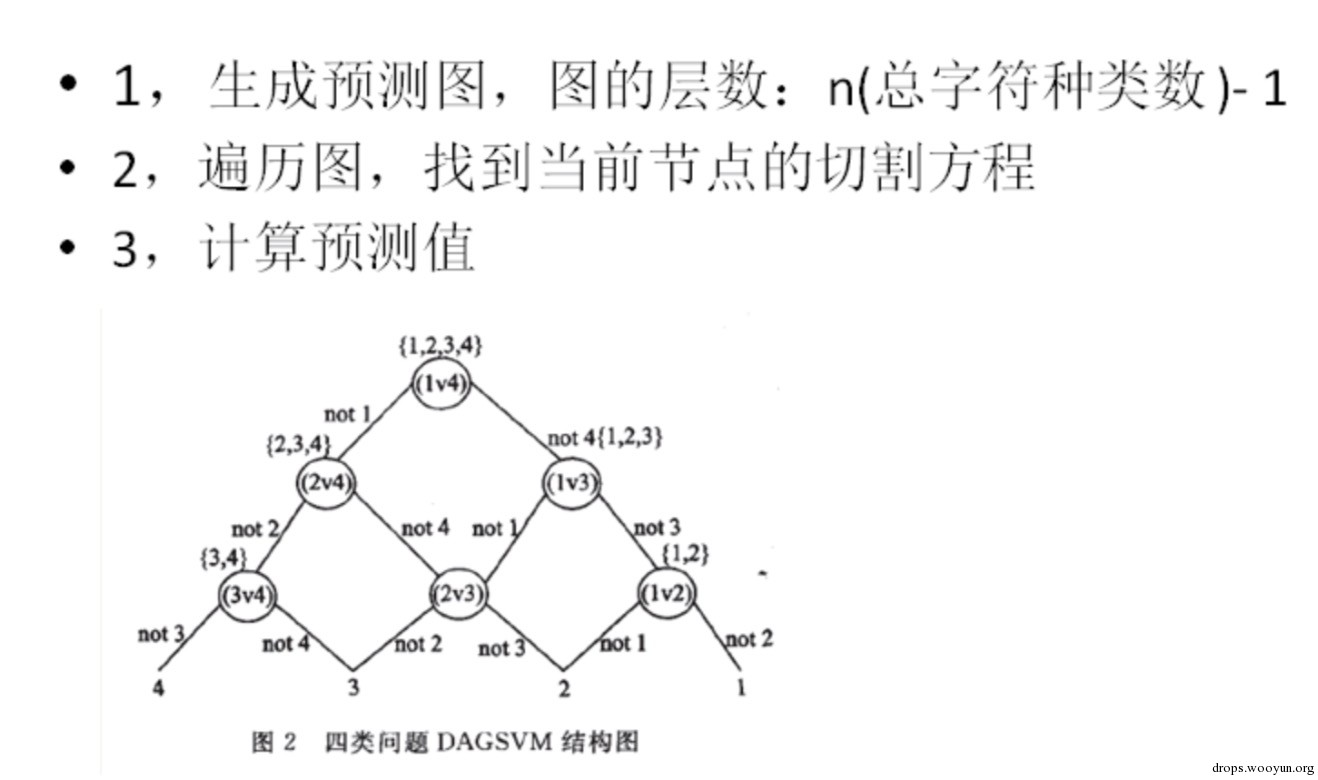
利用方程組預測——遍歷dag圖
由於svm是二分類器,只能判斷是或者不是,只需要使用k一1個決策函式即可得出結果,不存在誤分、拒分割槽域;另外,由於其特殊的結構,故有一定的容錯性,分類精度較一般的二叉樹方法高。
對於0123456789 共10個字元 共有45種非重複組合。利用dag只需判斷9次即可找出目標。
05 實踐總結
運用機器學習演算法時,如果不理解實現原理,先直接套介面,總之先實現功能,不必強求對演算法的徹底理解。 2. 識別演算法是通用的。
處理不同驗證碼,應該有不同的處理策略。
測試發現,主要耗時發生在構建方程過程中,構建方程耗時105s,識別1s。
影象去噪時對於大寬度的干擾線沒有好的解決辦法(干擾線寬度大於3畫素)。 6. 影象切割在面臨影象粘連時,目前無很好的處理方法。