
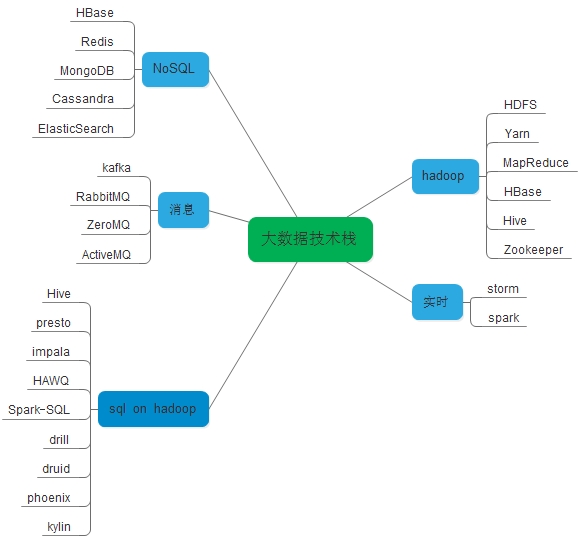
大資料元件架構
大資料,可以稱作近兩年IT界最火的名詞。當前大資料元件蓬勃發展,國內國外IT公司不斷開源自己公司所開發的各種元件,包括訊息佇列、資源管理、資料儲存、資料整合、資料計算、查詢分析、資料視覺化、任務排程等滿足自身業務需求的大資料元件系統。本文總結當前業內應用較多的,並且社群較活躍的元件。主要以腦圖、架構圖、列圖形式展示。
------------------------------------------------------------------------------------------------------------
歡迎關注公眾號【Data黑板報】

相關推薦
大資料元件架構
大資料,可以稱作近兩年IT界最火的名詞。當前大資料元件蓬勃發展,國內國外IT公司不斷開源自己公司所開發的各種元件,包括訊息佇列、資源管理、資料儲存、資料整合、資料計算、查詢分析、資料視覺化、
大資料元件GC問題
GC,指Garbage Collection 是JAVA中的垃圾收集器。 相關元件的常見GC問題 1、Namenode的堆記憶體配置過小導致頻繁產生full GC導致namenode宕機,在hadoop中,資料的寫入&讀取經由namenode,所以namenode的jvm記憶體需
大資料元件之----HIVE,win10下安裝以及配置hadoop詳細步驟
HIVE其本質是以Hadoop作為基礎的資料倉庫基礎設施。其中hadoop為資料的儲存和執行在商業機器上提供了可擴充套件以及容錯性的可能,其中容錯性可通過副本來進行理解。 目標: HIVE是讓資料彙總更加簡單和針對大容量資料的查詢和分析,提供了SWL來使得使用者可以更簡單查詢,彙總和資料分析
大資料元件之zookeeper核心處理 ----paxos演算法
1.如果理解不了paxos演算法,那麼也就理解不了zookeeper的核心處理了。 理論部分(問題產生的背景): 常見的分散式系統中,總會發生例如:機器宕機,以及網路異常( 網路異常包括訊息的延遲,丟失,重複,亂序,以及網路分割槽問題)等情況 paxos目的就是解決如何在發生上述問題
大資料平臺架構思考
筆者早期從事資料開發時,使用spark開發一段時間,感覺大資料開發差不多學到頭了,該會的似乎都會了。在後來的實踐過程中,發現很多事情需要站在更高的視角來看問題,不然很容易陷入“不識廬山真面目”的境界。最近在思考資料資產管理平臺的建設,進行血緣分析開發,有如下感悟: 大資料平臺從資料層面來說,包括資料本身和元
docker容器與大資料元件的衝突點
1.容器裡面安裝spark,外面的程式(安裝spark主機的容器)會連線不上叢集。理由:這個元件用的akka,連線上叢集,會提示: akka.ErrorMonitor: dropping message [class akka.actor.ActorSelectionMessage] for non-loc
大資料元件服務的啟動與關閉命令
本文主要整理了大資料元件服務的啟動與關閉命令,主要包括Hadoop,Spark,HBase,Hive,Zookeeper,Storm,Kafka,Flume,Solr,ElasticSearch。 1、Hadoop叢集 (1)啟動方式切換到主節點的hadoop安裝目錄下的sbin目錄
1.使用spoon進行資料轉換,抽取過程如下,,,,大資料元件之ETL
轉換過程如下: 2018/11/19 17:03:43 - Spoon - Using legacy execution engine 2018/11/19 17:03:43 - areacheckdaily - 轉換已經從資源庫預先載入. 2018/11/19 17:03:43 - Sp
1.大資料元件之ELK過程之安裝logstash-jdbc-input外掛
1.安裝logstash-jdbc-input外掛 安裝logstash的'jdbc連線檔案,首先需要安裝ruby,也是為了更好的使用ruby中的gem安裝外掛,下載地址如下: https://rubyinstaller.org/downloads/ (1)下面先寫一下ruby的安裝教程
重溫大資料---Hbase架構進階
這一講主要是對Hbase JavaApi使用的介紹,程式設計還是挺簡單的,重點在於理解程式設計實現的過程。其次深入講解了Hbase的架構。以及Hbase如何實現資料的遷移。 Hbase Java API Hbase提供了java開發的介面,可以使用java語
大資料元件以及常用軟體埠
Hadoop: 50070:HDFS WEB UI埠 8020 : 高可用的HDFS RPC埠 &
多圖技術貼:深入淺出解析大資料平臺架構
化資料也爆發式增長。比如: 1、業務系統現在平均每天儲存20萬張圖片,磁碟空間每天消耗100G; 2、平均每天產生簽約視訊檔案6000個,每個平均250M,磁碟空間每天消耗1T; …… 三國裡的“大資料” “草船借箭”和大資料有什麼關係呢?對天象的觀察是基於一種對風、雲、溫度、溼度、光照和
阿里如何實現秒級百萬TPS?搜尋離線大資料平臺架構解讀
什麼是搜尋離線? 一個典型的商品搜尋架構如下圖所示,本文將要重點介紹的就是下圖中的離線資料處理系統(Offline System)。 何謂離線?在阿里搜尋工程體系中我們把搜尋引擎、線上算分、SearchPlanner等ms級響應使用者請求的服務稱之為“
大資料的架構及配置技術(一)
大資料 Hadoop Hadoop安裝與配置 HDFS 一、大資料 大資料的定義 — 大資料是指無法在一定時間範圍內用常規軟體工具進行捕捉、管理和處理的資料集合,需要新處理模式才能具有更強的決策力。洞察發現力和流程優化能力的海量、高增長率和
Hadoop大資料平臺架構與實踐
一、什麼是Apache Hadoop? 1.1 定義和特性 可靠的、可擴充套件的、分散式計算開源軟體。 Apache Hadoop軟體庫是一個框架,允許使用簡單的程式設計模型,在計算機叢集分散式地處理大型資料集。 它可以從單個伺服器擴充套件到數千臺機器,每個機
重溫大資料---HA架構部署
說完這一講,Hadoop四個核心模組的內容基本上就結束了。前面講過了基礎的部署,包括單機、偽分散式,雖然完全分散式其實也挺簡單的,但是既然是知識的梳理,在本節我也做個講解吧。本節最重要的內容是對HDFS的HA架構的搭建。一年前看得我頭大,其實嘛沒有那麼難,只是
什麼樣的大資料平臺架構,才是最適合你的?
技術最終為業務服務,沒必要一定要追求先進性,各個企業應根據自己的實際情況去選擇自己的技術路徑。 它不一定具有通用性,但從一定程度講,這個架構可能比BAT的架構更適應大多數企業的情況,畢竟,大多數企業,資料沒到那個份上,也不可能完全自研,商業和開源的結合可能更好一點,
大資料 網際網路架構階段 Redis(三)redis叢集
Redis(三) redis叢集 一、 redis哨兵模式的缺點 問題一 : 橫向擴充套件不方便 , 一旦擴充套件 , 無論程式碼結構多麼簡單, 都需要修改 問題二 : 雜湊分散式演算法是ha
二、Hadoop大資料處理架構
一、概述 Hadoop是Apache軟體基金會旗下的一個開源分散式計算平臺。是一個能夠對大量資料進行分散式處理的軟體框架。由Java開發,但開發其應用可以使用多種語言,C,C++,跨平臺性非常好。 兩大核心:解決了分散式儲存和分散式處理兩大問題 HDFS(Hadoop Distributed Fi
大資料元件圖譜---比較齊全
轉載地址:http://blog.csdn.net/u010039929/article/details/70157376 大資料元件圖譜 檔案系統資料儲存記憶體技術資料蒐集訊息系統資料處理查詢引擎機器學習開發平臺 檔案系統 HD